贡献#
这是一个社区项目,欢迎所有人贡献。它托管在 scikit-learn/scikit-learn。scikit-learn 的决策过程和治理结构在 Scikit-learn 治理和决策 中阐述。
在添加新算法方面,Scikit-learn 有点 选择性,而贡献和帮助项目最好的方法是从处理已知问题开始。请参阅 新手贡献者的问题 开始。
如果您在使用此软件包时遇到问题,请随时向 GitHub 问题追踪器 提交工单。您也可以随时发布功能请求或拉取请求。
贡献方式#
有很多方法可以为 scikit-learn 做贡献,最常见的是为项目贡献代码或文档。改进文档与改进库本身一样重要。如果您在文档中发现错别字,或者做出了改进,请随时创建一个 GitHub 问题,或者最好提交一个 GitHub 拉取请求。完整的文档可以在 doc/ 目录下找到。
但还有许多其他方法可以提供帮助。特别是帮助 改进、分类和调查问题 和 审查其他开发者的拉取请求 都是非常宝贵的贡献,可以减轻项目维护人员的负担。
另一种贡献方式是报告您遇到的问题,并对其他人报告且与您相关的有问题点赞。如果您宣传该项目,例如在您的博客和文章中引用该项目,从您的网站链接到它,或者只是加星标以表示“我正在使用它”,这也会对我们有所帮助。
如果贡献/问题涉及对 API 原则的更改或对依赖项或支持版本的更改,则必须由 增强提案 (SLEP) 支持,其中必须将 SLEP 作为拉取请求提交到 增强提案,使用 SLEP 模板 并遵循 Scikit-learn 治理和决策 中概述的决策过程。
自动化贡献策略#
请避免提交由全自动化工具生成的 issue 或 pull request。维护人员保留自行决定关闭此类提交以及阻止任何为此负责的帐户的权利。
理想情况下,贡献应该源于以 issue 形式进行的人际讨论。
提交错误报告或功能请求#
我们使用 GitHub issue 来跟踪所有错误和功能请求;如果您发现错误或希望实现某个功能,请随时打开一个 issue。
如果您在使用此软件包时遇到问题,请随时向 错误追踪器 提交工单。您也可以随时发布功能请求或拉取请求。
建议在提交之前检查您的问题是否符合以下规则
如果您要提交算法或功能请求,请验证该算法是否符合我们的 新算法要求。
如果您要提交错误报告,我们强烈建议您遵循 如何编写有效的错误报告 中的指南。
如何编写有效的错误报告#
当您向 GitHub 提交问题时,请尽力遵循这些指南!这将使我们更容易为您提供良好的反馈。
理想的错误报告包含一个 简短的可复现代码片段,这样任何人都可以轻松地重现该错误。如果您的代码片段超过大约 50 行,请链接到 Gist 或 GitHub 仓库。
如果无法包含可复现的代码片段,请具体说明涉及哪些估计器和/或函数以及数据的形状。
如果引发异常,请提供完整的回溯信息。
请提供您的**操作系统类型和版本号**,以及您的**Python、scikit-learn、numpy和scipy版本**。您可以通过运行以下命令找到这些信息:
python -c "import sklearn; sklearn.show_versions()"请确保所有**代码片段和错误消息都以适当的代码块格式显示**。更多详情请参考 创建和突出显示代码块。
如果您想帮助管理问题,请阅读关于 Bug 分类和问题管理 的内容。
贡献代码#
注意
为了避免重复工作,强烈建议您搜索 问题跟踪器 和 PR 列表。如果您对重复工作存疑,或者想处理一个非简单的功能,建议您首先在 问题跟踪器 中打开一个问题,以获得核心开发人员的反馈。
查找需要处理的问题的一种简单方法是在搜索中应用“help wanted”标签。这会列出所有尚未认领的问题。为了认领一个问题,请在问题评论中精确输入/take,CI 系统会自动将该问题分配给您。
为了维护代码库的质量并简化审查流程,任何贡献都必须符合项目的 编码规范,特别是:
不要修改不相关的代码行,以保持 PR 集中于其描述或问题中说明的范围。
只编写有价值的内联注释,并避免说明显而易见的内容:解释“为什么”而不是“什么”。
**最重要的是**:不要贡献您不理解的代码。
视频资源#
这些视频逐步介绍了如何为 scikit-learn 做贡献,并且是以下文本指南的绝佳补充。请务必仍然查看下面的指南,因为它们描述了我们最新的工作流程。
注意
2021 年 1 月,scikit-learn GitHub 代码库的默认分支名称从master更改为main,以使用更具包容性的术语。这些视频是在分支重命名之前创建的。对于观看这些视频以设置其工作环境并提交 PR 的贡献者,应将master替换为main。
如何贡献#
为 scikit-learn 贡献代码的首选方式是在 GitHub 上分叉 主代码库,然后提交“拉取请求”(PR)。
在最初的几个步骤中,我们将解释如何在本地安装 scikit-learn,以及如何设置您的 Git 代码库。
如果您还没有 GitHub 帐户,请 创建一个帐户。
分叉 项目代码库:点击页面顶部的“Fork”按钮。这会在您的 GitHub 用户帐户下创建代码副本。有关如何分叉代码库的更多详细信息,请参阅 本指南。
将您在 GitHub 帐户上分叉的 scikit-learn 代码库克隆到您的本地磁盘。
git clone git@github.com:YourLogin/scikit-learn.git # add --depth 1 if your connection is slow cd scikit-learn
按照 从源码构建 中的步骤 2-6 进行操作,以开发模式构建 scikit-learn 并返回此文档。
安装开发依赖项。
pip install pytest pytest-cov ruff mypy numpydoc black==24.3.0
添加
upstream远程仓库。这将保存对主 scikit-learn 代码库的引用,您可以使用它来使您的代码库与最新的更改保持同步。git remote add upstream git@github.com:scikit-learn/scikit-learn.git通过运行
git remote -v检查upstream和origin远程别名是否配置正确,这应该显示:origin git@github.com:YourLogin/scikit-learn.git (fetch) origin git@github.com:YourLogin/scikit-learn.git (push) upstream git@github.com:scikit-learn/scikit-learn.git (fetch) upstream git@github.com:scikit-learn/scikit-learn.git (push)
您现在应该已经拥有了 scikit-learn 的工作安装程序,并且您的 Git 代码库已正确配置。运行一些测试以验证您的安装可能很有用。请参考 有用的 pytest 别名和标志 以获取示例。
接下来的步骤描述了修改代码和提交 PR 的过程。
将您的
main分支与upstream/main分支同步,更多详细信息请参阅 GitHub 文档git checkout main git fetch upstream git merge upstream/main
创建一个功能分支来保存您的开发更改。
git checkout -b my_feature并开始进行更改。始终使用功能分支。最好不要在
main分支上工作!(**可选**)安装 pre-commit 以在每次提交之前运行代码样式检查。
pip install pre-commit pre-commit install
可以使用
git commit -n为特定提交禁用 pre-commit 检查。在您的计算机上使用 Git 进行版本控制,在您的功能分支上开发该功能。完成编辑后,使用
git add,然后git commitgit add modified_files git commit
在 Git 中记录您的更改,然后使用以下命令将更改推送到您的 GitHub 帐户:
git push -u origin my_feature请按照这些说明从你的fork创建pull request。这将向潜在的评审者发送通知。如果你的pull request几天后没有收到关注,你可能需要考虑在开发频道中向discord发送消息以提高可见性(不过不能保证立即回复)。
通常情况下,将你的本地特性分支与scikit-learn主仓库的最新更改保持同步非常有帮助。
git fetch upstream
git merge upstream/main
随后,你可能需要解决冲突。你可以参考关于使用命令行解决合并冲突的Git文档。
Pull request检查清单#
在合并PR之前,需要获得两位核心开发者的批准。对于尚未完工的贡献(你期望在收到完整审查之前完成更多工作),应将其标记为草稿pull request,并在成熟时更改为“已准备好审查”。草稿PR可能用于:表明你正在处理某些内容以避免重复工作,请求对功能或API进行广泛审查,或寻找合作者。草稿PR通常受益于在PR描述中包含任务列表。
为了简化审查过程,我们建议你的贡献在将PR标记为“已准备好审查”之前符合以下规则。**加粗**的规则尤其重要。
**为你的pull request 提供一个有帮助的标题**,总结你的贡献做了什么。这个标题在合并后通常会成为提交信息,因此它应该总结你的贡献以供后人参考。在某些情况下,“修复
” 就足够了。“修复 # ” 从来都不是一个好的标题。 **确保你的代码通过测试**。可以使用
pytest运行整个测试套件,但这通常不推荐,因为它需要很长时间。通常只需运行与你的更改相关的测试就足够了:例如,如果你更改了sklearn/linear_model/_logistic.py中的某些内容,运行以下命令通常就足够了。pytest sklearn/linear_model/_logistic.py以确保doctest示例正确。pytest sklearn/linear_model/tests/test_logistic.py以运行特定于该文件的测试。pytest sklearn/linear_model以测试整个linear_model模块。pytest doc/modules/linear_model.rst以确保用户指南示例正确。pytest sklearn/tests/test_common.py -k LogisticRegression以运行我们所有的估计器检查(特别是对于LogisticRegression,如果那是你更改的估计器)。
可能还有其他失败的测试,但CI会捕获它们,因此你不需要在本地运行整个测试套件。有关如何有效使用
pytest的指南,请参阅有用的pytest别名和标志。**确保你的代码已正确注释和记录**,并**确保文档正确渲染**。要构建文档,请参考我们的文档指南。CI也会构建文档:请参考GitHub Actions 上生成的文档。
**增强功能需要测试才能被接受**。错误修复或新功能应提供非回归测试。这些测试验证修复或功能的正确行为。这样,代码库上的进一步修改就能保证与预期行为一致。对于错误修复,在PR时,非回归测试应该对于
main分支中的代码库失败,而对于PR代码则通过。如果你的PR可能会影响用户,你需要添加一个变更日志条目来描述你的PR更改,请参阅
以下 README <https://github.com/scikit-learn/scikit-learn/blob/main/doc/whats_new/upcoming_changes/README.md>了解更多详情。请遵循编码指南。
在适用情况下,使用
sklearn.utils模块中的验证工具和脚本。可在开发者实用工具页面找到可供开发者使用的实用程序例程列表。pull request 通常会解决一个或多个其他问题(或pull request)。如果合并你的pull request意味着某些其他问题/PR应该关闭,你应该使用关键词来创建指向它们的链接(例如,
Fixes #1234;只要每个问题/PR前面都有一个关键词,就可以允许多个问题/PR)。合并后,GitHub将自动关闭这些问题/PR。如果你的pull request只是与其他一些问题/PR相关,或者它只是部分解决了目标问题,请创建指向它们的链接,但不要使用关键词(例如,Towards #1234)。PR通常应该通过性能和效率的基准测试(参见性能监控)或使用示例来证实更改。示例还可以向用户演示库的功能和复杂性。请查看examples/目录中的其他示例以供参考。示例应该演示为什么新功能在实践中很有用,如果可能的话,将其与scikit-learn中可用的其他方法进行比较。
新功能会带来一些维护开销。我们期望 PR 作者至少在最初阶段参与他们提交代码的维护工作。新功能需要在用户指南中用叙述性文档进行说明,并附带少量代码片段。如有相关内容,请同时添加文献引用,如果可能的话,请提供 PDF 链接。
用户指南还应包含算法的预期时间和空间复杂度以及可扩展性,例如:“此算法可以扩展到大量样本 > 100000,但在维度上不具有可扩展性:
n_features预期值应低于 100”。
您还可以查看我们的 代码审查指南,了解审阅者会期待什么。
您可以使用以下工具检查常见的编程错误
代码应具有良好的单元测试覆盖率(至少 80%,最好 100%),请使用以下工具检查:
pip install pytest pytest-cov pytest --cov sklearn path/to/tests
另请参见 测试和提高测试覆盖率。
使用
mypy运行静态分析mypy sklearn这不能在您的 pull request 中产生新的错误。对于
mypy不支持的少数情况,可以使用# type: ignore注解作为变通方法,尤其是在以下情况下:导入 C 或 Cython 模块时;
使用装饰器的属性。
如果您的贡献包含使用基准脚本和性能分析输出的性能分析(请参阅 性能监控),将获得额外加分。另请查看 如何优化速度 指南,了解更多关于性能分析和 Cython 优化的细节。
注意
当前 scikit-learn 代码库的状态并不符合所有这些指南,但我们期望对所有新贡献强制执行这些约束,将使整个代码库的质量朝着正确的方向发展。
另请参见
关于开发流程的两个文档完善且更详细的指南,请访问 Scipy 开发流程 和 Astropy 开发人员工作流程 部分。
持续集成 (CI)#
Azure pipelines 用于在 Linux、Mac 和 Windows 上测试 scikit-learn,并使用不同的依赖项和设置。
CircleCI 用于构建文档以供查看。
Github Actions 用于各种任务,包括构建 wheel 和源代码分发包。
Cirrus CI 用于在 ARM 上构建。
提交信息标记#
请注意,如果在最新的提交信息中出现以下标记之一,则将采取以下操作。
提交信息标记 |
CI 执行的操作 |
|---|---|
[ci skip] |
完全跳过 CI |
[cd build] |
运行 CD(构建 wheel 和源代码分发包) |
[cd build gh] |
仅针对 GitHub Actions 运行 CD |
[cd build cirrus] |
仅针对 Cirrus CI 运行 CD |
[lint skip] |
Azure pipeline 跳过 lint 检查 |
[scipy-dev] |
使用我们的依赖项(numpy、scipy 等)的开发版本进行构建和测试 |
[free-threaded] |
使用 CPython 3.13 free-threaded 进行构建和测试 |
[pyodide] |
使用 Pyodide 进行构建和测试 |
[azure parallel] |
并行运行 Azure CI 作业 |
[cirrus arm] |
运行 Cirrus CI ARM 测试 |
[float32] |
通过设置 |
[doc skip] |
不构建文档 |
[doc quick] |
构建文档,但不包含示例库图表 |
[doc build] |
构建文档,包括示例库图表(非常耗时) |
请注意,默认情况下,会构建文档,但仅执行 pull request 直接修改的示例。
构建锁文件#
CI 使用锁文件来构建具有特定依赖项版本的构建环境。当 PR 需要修改依赖项或其版本时,应相应地更新锁文件。这可以通过在 GitHub Pull Request (PR) 讨论中直接添加以下评论来完成
@scikit-learn-bot update lock-files
几分钟后,机器人会将一个包含已更新锁文件的提交推送到您的 PR 分支。请务必选中 PR 右侧边栏底部 的“允许维护者编辑”复选框。您还可以像在命令行中一样指定选项 --select-build、--skip-build 和 --select-tag。有关更多信息,请在脚本 build_tools/update_environments_and_lock_files.py 上使用 --help。例如:
@scikit-learn-bot update lock-files --select-tag main-ci --skip-build doc
机器人会自动为某些标签添加 提交信息标记 到提交中。如果您想手动添加更多标记,您可以使用 --commit-marker 选项。例如,以下评论将触发机器人更新与文档相关的锁文件并将 [doc build] 标记添加到提交中
@scikit-learn-bot update lock-files --select-build doc --commit-marker "[doc build]"
解决锁文件中的冲突#
这是一个有助于解决环境和锁文件冲突的 bash 代码片段
# pull latest upstream/main
git pull upstream main --no-rebase
# resolve conflicts - keeping the upstream/main version for specific files
git checkout --theirs build_tools/*/*.lock build_tools/*/*environment.yml \
build_tools/*/*lock.txt build_tools/*/*requirements.txt
git add build_tools/*/*.lock build_tools/*/*environment.yml \
build_tools/*/*lock.txt build_tools/*/*requirements.txt
git merge --continue
这会将 upstream/main 合并到我们的分支中,自动优先考虑 upstream/main 中冲突的环境和锁文件(这已经足够了,因为我们之后会重新生成锁文件)。
请注意,这只会修复环境和锁文件中的冲突,您可能还需要解决其他冲突。
最后,我们必须为 CI 重新生成环境和锁文件,如 构建锁文件 中所述,或者通过运行以下命令:
python build_tools/update_environments_and_lock_files.py
停滞的 pull requests#
由于贡献功能可能是一个漫长的过程,一些 pull request 看起来不活跃,但尚未完成。在这种情况下,接手它们是对项目的一大贡献。接手的良好礼仪是
确定 PR 是否停滞
如果我们已经将某个 PR 确定为其他贡献者的候选者,则它可能带有“停滞”或“需要帮助”标签。
要确定不活跃的 PR 是否停滞,请询问贡献者她/他是否计划在不久的将来继续处理此 PR。如果在两周内没有回复或进行推进 PR 的活动,则表明 PR 已停滞,并将为此 PR 添加“需要帮助”标签。
请注意,如果 PR 之前收到的关于贡献的评论一个月内没有回复,则可以安全地假设 PR 已停滞,并将等待时间缩短为一天。
冲刺结束后,将对冲刺期间打开但未合并的 PR 进行后续沟通,并将这些 PR 标记为“sprint”。带有“sprint”标签的 PR 可以由冲刺负责人重新分配或声明为停滞。
接管停滞的 PR:要接管 PR,务必在停滞的 PR 上评论您正在接管,并从新的 PR 链接到旧的 PR。新的 PR 应该通过从旧的 PR 拉取代码来创建。
停滞和无人认领的问题#
一般来说,可供选择的 issue 会带有 “help wanted” 标签。但是,并非所有需要贡献者的 issue 都会有此标签,因为“help wanted”标签并不总是与 issue 的状态同步。贡献者可以使用以下指南找到仍然可供选择的 issue
首先,要确定 issue 是否已被认领
检查链接的 pull request
检查对话,看看是否有人说过他们正在努力创建 pull request
如果贡献者在 issue 上评论说他们正在处理它,则预计会在 2 周(新贡献者)或 4 周(贡献者或核心开发者)内提交 pull request,除非明确给出更长的时间范围。超过该时间后,其他贡献者可以接管该 issue 并为其创建 pull request。我们鼓励贡献者直接在停滞或无人认领的 issue 上评论,让社区成员知道他们将要处理它。
如果 issue 链接到 停滞的 pull request,我们建议贡献者遵循停滞的 pull request 部分中描述的流程,而不是直接处理 issue。
新贡献者的 issue#
新贡献者在寻找 issue 时应该注意以下标签。我们强烈建议新贡献者首先处理“easy”级别的 issue:这有助于贡献者熟悉贡献流程,并让核心开发者了解贡献者;此外,我们经常低估一个 issue 的解决难度!
Good first issue 标签
开始为 scikit-learn 贡献代码的一个好方法是从 issue 跟踪器中的 good first issues 列表 中选择一个项目。解决这些 issue 允许您在没有太多预备知识的情况下开始为项目贡献代码。如果您已经为 scikit-learn 做过贡献,则应该查看 Easy 级别的 issue。
Easy 标签
如果您已经为 scikit-learn 做过贡献,另一个为 scikit-learn 贡献代码的好方法是从 issue 跟踪器中的 Easy issues 列表 中选择一个项目。您在此方面的帮助将受到经验丰富的开发人员的高度赞赏,因为它有助于释放他们的时间,让他们专注于其他 issue。
Help wanted 标签
我们经常使用 help wanted 标签来标记 issue,无论其难度如何。此外,我们使用 help wanted 标签来标记已被其原始贡献者放弃且可供其他人接手的 Pull Request。带有 help wanted 标签的 issue 列表可以在这里找到 这里。请注意,并非所有需要贡献者的 issue 都会有此标签。
文档#
我们很乐意接受任何类型的文档
函数/方法/类文档字符串: 也称为“API 文档”,它们描述了对象的功能以及任何参数、属性和方法的详细信息。文档字符串与代码一起位于 sklearn/ 中,并根据 doc/api_reference.py 生成。要添加、更新、删除或弃用 API 参考 中列出的公共 API,这里就是需要查看的地方。
用户指南: 这些提供了关于 scikit-learn 中实现的算法的更详细信息,通常位于根目录 doc/ 目录和 doc/modules/ 中。
示例: 这些提供了完整的代码示例,可能演示 scikit-learn 模块的使用,比较不同的算法或讨论它们的解释等等。示例位于 examples/ 中。
编写文档字符串的指南#
在记录参数和属性时,这里列出了一些格式良好的示例
n_clusters : int, default=3 The number of clusters detected by the algorithm. some_param : {"hello", "goodbye"}, bool or int, default=True The parameter description goes here, which can be either a string literal (either `hello` or `goodbye`), a bool, or an int. The default value is True. array_parameter : {array-like, sparse matrix} of shape (n_samples, n_features) \ or (n_samples,) This parameter accepts data in either of the mentioned forms, with one of the mentioned shapes. The default value is `np.ones(shape=(n_samples,))`. list_param : list of int typed_ndarray : ndarray of shape (n_samples,), dtype=np.int32 sample_weight : array-like of shape (n_samples,), default=None multioutput_array : ndarray of shape (n_samples, n_classes) or list of such arrays一般情况下,请记住以下几点
使用 Python 基本类型。(
bool而不是boolean)使用括号定义形状:
array-like of shape (n_samples,)或array-like of shape (n_samples, n_features)对于具有多个选项的字符串,使用括号:
input: {'log', 'squared', 'multinomial'}一维或二维数据可以是
{array-like, ndarray, sparse matrix, dataframe}的子集。请注意,array-like也可以是list,而ndarray明确地只表示numpy.ndarray。当使用“类似框架”的特征(例如列名)时,请指定
dataframe。指定列表的数据类型时,使用
of作为分隔符:list of int。如果参数支持数组,并给出关于形状和/或数据类型的详细信息以及此类数组的列表,则可以使用array-like of shape (n_samples,) or list of such arrays。指定ndarray的dtype时,例如在定义形状后使用
dtype=np.int32:ndarray of shape (n_samples,), dtype=np.int32。可以将多个dtype指定为一个集合:array-like of shape (n_samples,), dtype={np.float64, np.float32}。如果需要提到任意精度,请使用integral和floating,而不是Python的dtypeint和float。如果同时支持int和floating,则无需指定dtype。当默认值为
None时,只需要在最后用default=None指定None。请务必在文档字符串中说明参数或属性为None的含义。
在文档字符串中添加“参见” (See Also) 用于相关的类/函数。
文档字符串中的“参见” (See Also) 应每条引用一行,并在冒号后加上解释,例如:
See Also -------- SelectKBest : Select features based on the k highest scores. SelectFpr : Select features based on a false positive rate test.
在“示例” (Example) 部分添加一到两段代码片段,以展示其使用方法。
编写用户指南和其他reStructuredText文档的指南#
在数学和算法细节之间保持良好的平衡非常重要,并让读者直观地了解算法的功能。
首先简要地、通俗地解释算法/代码对数据的作用。
突出该功能的实用性和推荐的应用场景。如果可用,请考虑包含算法的复杂度(\(O\left(g\left(n\right)\right)\)),因为“经验法则”可能非常依赖于机器。只有在这些复杂度不可用时,才能提供经验法则。
加入相关的图表(由示例生成)以提供直观理解。
包含一到两个简短的代码示例以演示该功能的使用。
介绍任何必要的数学方程式,然后是参考文献。通过推迟数学方面的内容,文档对于主要感兴趣于理解功能的实际意义而不是其底层机制的用户来说更容易理解。
编辑reStructuredText (
.rst) 文件时,如果可能,请尽量将行长保持在88个字符以内(链接和表格除外)。在scikit-learn的reStructuredText文件中,文本周围的单反引号和双反引号都将呈现为内联文本(通常用于代码,例如
list)。这是由于我们设置的特定配置。现在应该使用单反引号。过多的信息会使用户难以访问他们感兴趣的内容。使用下拉菜单进行分解,使用以下语法:
.. dropdown:: Dropdown title Dropdown content.
上面的代码片段将生成以下下拉菜单:
下拉菜单标题#
下拉菜单内容。
可以使用下拉菜单隐藏的信息包括:
低层次的部分,例如
References,Properties等(例如,参见检测误差均衡 (DET)中的子部分);深入的数学细节;
特定用例的叙述;
一般而言,可能只对那些希望超越给定工具的实用性的用户感兴趣的叙述。
不要对低级部分
Examples使用下拉菜单,因为它应该对所有用户可见。确保Examples部分紧跟在主要讨论之后,中间尽可能少地折叠部分。请注意,下拉菜单会破坏交叉引用。如果这样做有意义,请将引用与提及它的文本一起隐藏。否则,请不要使用下拉菜单。
编写参考文献的指南#
如果参考文献带有arxiv或数字对象标识符 (DOI) 编号,请使用sphinx指令
:arxiv:或:doi:。例如,参见谱聚类图中的参考文献。关于文档字符串中“参考文献” (References) 部分,请参见
sklearn.metrics.silhouette_score为例。要交叉引用 scikit-learn 文档中的其他页面,请使用 reStructuredText 交叉引用语法。
章节:要链接到文档中的任意章节,请使用引用标签(参见 Sphinx 文档)。例如:
.. _my-section: My section ---------- This is the text of the section. To refer to itself use :ref:`my-section`.
不要修改现有的 Sphinx 引用标签,因为这会破坏现有的交叉引用和指向 scikit-learn 文档中特定章节的外部链接。
术语表:链接到 常用术语和 API 元素术语表 中的术语。
:term:`cross_validation`
函数:要链接到函数的文档,请使用函数的完整导入路径。
:func:`~sklearn.model_selection.cross_val_score`
但是,如果文档上方有
.. currentmodule::指令,则只需要使用当前模块后面指定的函数路径即可。例如:.. currentmodule:: sklearn.model_selection :func:`cross_val_score`
类:要链接到类的文档,请使用类的完整导入路径,除非文档上方有
.. currentmodule::指令(参见上文)。:class:`~sklearn.preprocessing.StandardScaler`
您可以使用任何文本编辑器编辑文档,然后按照 构建文档 中的说明生成 HTML 输出。生成的 HTML 文件将放置在 _build/html/ 目录下,可以在 Web 浏览器中查看,例如,打开本地 _build/html/index.html 文件或运行本地服务器。
python -m http.server -d _build/html
构建文档#
在提交拉取请求之前,请检查您的修改是否引入了新的 Sphinx 警告,方法是本地构建文档并尝试修复它们。
首先,确保您已 正确安装 开发版本。除此之外,构建文档还需要安装一些额外的软件包。
pip install sphinx sphinx-gallery numpydoc matplotlib Pillow pandas \
polars scikit-image packaging seaborn sphinx-prompt \
sphinxext-opengraph sphinx-copybutton plotly pooch \
pydata-sphinx-theme sphinxcontrib-sass sphinx-design \
sphinx-remove-toctrees
要构建文档,您需要位于 doc 文件夹中。
cd doc
在绝大多数情况下,您只需要生成网站,而不需要示例库。
make
文档将生成在 _build/html/stable 目录中,可以在 Web 浏览器中查看,例如,打开本地 _build/html/stable/index.html 文件。要同时生成示例库,可以使用:
make html
这将运行所有示例,这需要一些时间。您也可以根据文件名只运行几个示例。以下是如何运行所有文件名包含 plot_calibration 的示例:
EXAMPLES_PATTERN="plot_calibration" make html
您可以使用正则表达式来处理更高级的用例。
如果您打算在脱机环境中查看文档,请设置环境变量 NO_MATHJAX=1。要构建 PDF 手册,请运行:
make latexpdf
Sphinx 版本
尽管我们尽最大努力使文档在尽可能多的 Sphinx 版本下都能构建,但不同版本的行为往往略有不同。为了获得最佳结果,您应该使用我们在 CircleCI 上使用的相同版本。查看此 GitHub 搜索 以了解确切的版本。
GitHub Actions 上生成的文档#
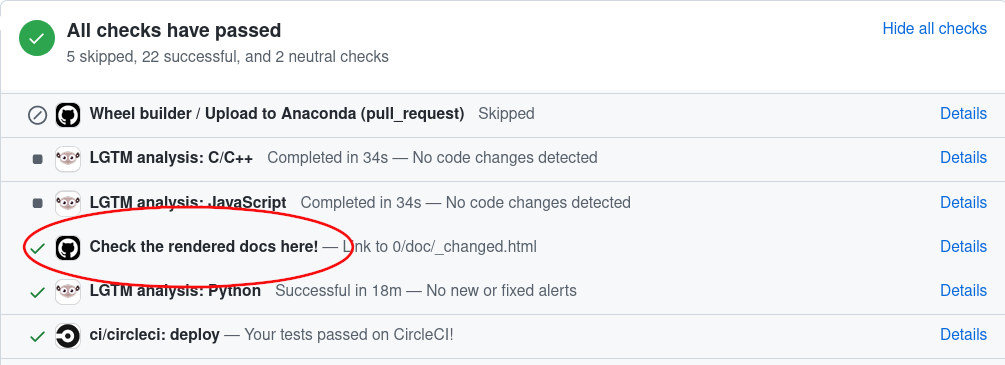
当您在拉取请求中更改文档时,GitHub Actions 会自动构建它。要查看 GitHub Actions 生成的文档,只需转到 PR 页面的底部,查找“在此处查看渲染后的文档!”项,然后单击它旁边的“详细信息”。
测试和改进测试覆盖率#
高质量的 单元测试 是 scikit-learn 开发过程的基石。为此,我们使用 pytest 包。测试是位于 tests 子目录中的命名合适的函数,用于检查算法和代码的不同选项的有效性。
在文件夹中运行 pytest 将运行相应子包的所有测试。有关更详细的 pytest 工作流程,请参考 拉取请求清单。
我们期望新功能的代码覆盖率至少达到 90% 左右。
性能监控#
本节内容大量参考自 pandas 文档。
在对现有代码库进行更改时,务必确保不会引入性能下降。Scikit-learn 使用 asv 基准测试 来监控一些常用估计器和函数的性能。您可以在 scikit-learn 基准测试页面 查看这些基准测试结果。相应的基准测试套件位于 asv_benchmarks/ 目录中。
要使用 asv 的所有功能,您需要 conda 或 virtualenv。更多详细信息,请查看 asv 安装网页。
首先,您需要安装 asv 的开发版本
pip install git+https://github.com/airspeed-velocity/asv
并将您的目录更改为 asv_benchmarks/
cd asv_benchmarks
基准测试套件配置为针对您本地克隆的 scikit-learn 运行。确保它是最新的
git fetch upstream
在基准测试套件中,基准测试的组织结构与 scikit-learn 相同。例如,您可以比较特定估计器在 upstream/main 和您正在使用的分支之间的性能
asv continuous -b LogisticRegression upstream/main HEAD
该命令默认使用 conda 创建基准环境。如果您想改用 virtualenv,请使用 -E 标志
asv continuous -E virtualenv -b LogisticRegression upstream/main HEAD
您还可以指定要进行基准测试的整个模块
asv continuous -b linear_model upstream/main HEAD
您可以将 HEAD 替换为任何本地分支。默认情况下,它只会报告至少变化 10% 的基准测试。您可以使用 -f 标志控制此比率。
要运行完整的基准测试套件,只需删除 -b 标志
asv continuous upstream/main HEAD
但是这可能需要长达两个小时。 -b 标志也接受正则表达式,用于运行更复杂的基准测试子集。
要运行基准测试而不与其他分支进行比较,请使用 run 命令
asv run -b linear_model HEAD^!
您还可以使用当前 Python 环境中已安装的 scikit-learn 版本运行基准测试套件
asv run --python=same
当您以可编辑模式安装 scikit-learn 时,这尤其有用,可以避免每次运行基准测试时都创建新环境。默认情况下,使用现有安装时不会保存结果。要保存结果,必须指定提交哈希值
asv run --python=same --set-commit-hash=<commit hash>
基准测试结果按机器、环境和提交进行保存和组织。要查看所有已保存基准测试的列表
asv show
以及查看特定运行的报告
asv show <commit hash>
运行您正在处理的拉取请求的基准测试时,请在 github 上报告结果。
基准测试套件支持其他可配置选项,这些选项可以在 benchmarks/config.json 配置文件中设置。例如,基准测试可以针对 n_jobs 参数的提供的列表值运行。
有关如何编写基准测试以及如何使用 asv 的更多信息,请参阅 asv 文档。
维护向后兼容性#
弃用#
如果任何公开访问的类、函数、方法、属性或参数被重命名,我们仍然在两个版本中支持旧版本,并在调用、传递或访问旧版本时发出弃用警告。
弃用类或函数
假设函数 zero_one 重命名为 zero_one_loss,我们将装饰器 utils.deprecated 添加到 zero_one 并从该函数调用 zero_one_loss
from ..utils import deprecated
def zero_one_loss(y_true, y_pred, normalize=True):
# actual implementation
pass
@deprecated(
"Function `zero_one` was renamed to `zero_one_loss` in 0.13 and will be "
"removed in 0.15. Default behavior is changed from `normalize=False` to "
"`normalize=True`"
)
def zero_one(y_true, y_pred, normalize=False):
return zero_one_loss(y_true, y_pred, normalize)
还需要将 zero_one 从 API_REFERENCE 移动到 DEPRECATED_API_REFERENCE,并在 doc/api_reference.py 文件中将 zero_one_loss 添加到 API_REFERENCE,以反映 API 参考 中的更改。
弃用属性或方法
如果要弃用属性或方法,请在属性上使用装饰器 deprecated。请注意,如果存在 property 装饰器,则应将 deprecated 装饰器放在 property 装饰器之前,以便可以正确呈现文档字符串。例如,将属性 labels_ 重命名为 classes_ 可以这样完成
@deprecated(
"Attribute `labels_` was deprecated in 0.13 and will be removed in 0.15. Use "
"`classes_` instead"
)
@property
def labels_(self):
return self.classes_
弃用参数
如果必须弃用参数,则必须手动引发 FutureWarning 警告。在下面的示例中,k 已弃用并重命名为 n_clusters
import warnings
def example_function(n_clusters=8, k="deprecated"):
if k != "deprecated":
warnings.warn(
"`k` was renamed to `n_clusters` in 0.13 and will be removed in 0.15",
FutureWarning,
)
n_clusters = k
如果更改在类中,我们将在 fit 中验证并引发警告
import warnings
class ExampleEstimator(BaseEstimator):
def __init__(self, n_clusters=8, k='deprecated'):
self.n_clusters = n_clusters
self.k = k
def fit(self, X, y):
if self.k != "deprecated":
warnings.warn(
"`k` was renamed to `n_clusters` in 0.13 and will be removed in 0.15.",
FutureWarning,
)
self._n_clusters = self.k
else:
self._n_clusters = self.n_clusters
如同这些例子所示,警告信息应始终同时给出弃用发生和旧行为将被移除的版本号。如果弃用发生在 0.x-dev 版本中,则消息应说明弃用发生在 0.x 版本,移除将在 0.(x+2) 版本中进行,以便用户有足够的时间将其代码适配到新的行为。例如,如果弃用发生在 0.18-dev 版本中,则消息应说明它发生在 0.18 版本中,旧行为将在 0.20 版本中移除。
警告信息还应包含对更改的简要解释,并引导用户找到替代方案。
此外,应在文档字符串中添加弃用说明,内容与上述弃用警告中说明的信息相同。使用 .. deprecated:: 指令
.. deprecated:: 0.13
``k`` was renamed to ``n_clusters`` in version 0.13 and will be removed
in 0.15.
此外,弃用需要一个测试来确保警告在相关情况下被引发,但在其他情况下不被引发。所有其他测试都应捕获警告(例如,使用 @pytest.mark.filterwarnings),并且示例中不应出现警告。
更改参数的默认值#
如果需要更改参数的默认值,请用特定值替换默认值(例如,"warn"),并在用户使用默认值时引发 FutureWarning。以下示例假设当前版本为 0.20,并且我们将 n_clusters 的默认值从 5(0.20 的旧默认值)更改为 10(0.22 的新默认值)
import warnings
def example_function(n_clusters="warn"):
if n_clusters == "warn":
warnings.warn(
"The default value of `n_clusters` will change from 5 to 10 in 0.22.",
FutureWarning,
)
n_clusters = 5
如果更改在类中,我们将在 fit 中验证并引发警告
import warnings
class ExampleEstimator:
def __init__(self, n_clusters="warn"):
self.n_clusters = n_clusters
def fit(self, X, y):
if self.n_clusters == "warn":
warnings.warn(
"The default value of `n_clusters` will change from 5 to 10 in 0.22.",
FutureWarning,
)
self._n_clusters = 5
与弃用类似,警告信息应始终同时给出更改发生和旧行为将被移除的版本号。
文档字符串中的参数描述需要相应更新,方法是添加一个 versionchanged 指令,其中包含旧的和新的默认值,并指向更改生效的版本。
.. versionchanged:: 0.22
The default value for `n_clusters` will change from 5 to 10 in version 0.22.
最后,我们需要一个测试来确保警告在相关情况下被引发,但在其他情况下不被引发。所有其他测试都应捕获警告(例如,使用 @pytest.mark.filterwarnings),并且示例中不应出现警告。
代码审查指南#
作为 PR 对项目贡献的代码进行审查是 scikit-learn 开发的关键组成部分。我们鼓励任何人都可以开始审查其他开发人员的代码。代码审查过程通常对所有参与者来说都是非常有教育意义的。如果您想使用某个功能,这尤其适用,因此您可以批判性地回应 PR 是否满足您的需求。虽然每个拉取请求都需要由两位核心开发人员签署,但您可以通过提供反馈来加快此过程。
注意
客观改进和主观细节之间的区别并不总是很清晰。审查者应记住,代码审查的主要目的是降低项目的风险。审查代码时,应尽量避免可能需要错误修复、弃用或撤回的情况。关于文档:最好立即处理错别字、语法问题和歧义。
任何代码审查中都应涵盖的重要方面#
以下是一些任何代码审查中都应涵盖的重要方面,从高级问题到更详细的清单。
我们是否需要这个库?它可能被使用吗?作为 scikit-learn 用户,您是否喜欢此更改并打算使用它?它在 scikit-learn 的范围内吗?维护新功能的成本是否值得其好处?
代码是否与 scikit-learn 的 API 一致?公共函数/类/参数是否命名合理且设计直观?
所有公共函数/类及其参数、返回类型和存储属性是否都根据 scikit-learn 约定命名并清晰地记录?
用户指南中是否描述了任何新功能并用示例进行了说明?
每个公共函数/类是否都经过测试?是否测试了一组合理的参数、其值、值类型和组合?测试是否验证代码是正确的,即按照文档说明执行操作?如果更改是错误修复,是否包含非回归测试?请查看此处以开始使用 Python 进行测试。
测试是否在持续集成构建中通过?如果合适,帮助贡献者理解为什么测试失败。
测试是否涵盖了每一行代码(请参阅构建日志中的覆盖率报告)?如果没有,未覆盖的行是否为良好的异常情况?
代码是否易于阅读且冗余度低?是否应改进变量名称以提高清晰度或一致性?是否应添加注释?是否应删除无用或多余的注释?
是否可以轻松地重写代码以针对相关设置运行更高效?
代码是否与之前的版本向后兼容?(或者是否需要弃用周期?)
新代码是否会添加对其他库的任何依赖?(这不太可能被接受)
文档是否正确呈现(有关更多详细信息,请参阅文档部分),并且绘图是否具有指导意义?
审查的标准回复包含审查者可能发表的一些常见评论。
沟通指南#
审查开放的拉取请求 (PR) 有助于项目的推进。这是熟悉代码库的好方法,应该激励贡献者继续参与项目。[1]
每个 PR,无论好坏,都是一种慷慨的行为。以积极的评论开头将有助于作者感到欣慰,并且您的后续评论可能会被更清晰地听到。您可能也会感觉良好。
如果可能,从大的问题开始,这样作者就知道他们已经被理解了。避免立即逐行检查,或以小的普遍性问题开头。
不要让完美成为好的敌人。如果你发现自己提出了许多不符合代码审查指南的小建议,请考虑以下方法:
不要提交这些建议;
在建议前加上“Nit”前缀,以便贡献者知道不必处理这些建议;
出于礼貌,你可能希望在后续的PR中告知原始贡献者。
不要仓促,花时间使你的评论清晰并证明你的建议。
你是项目的代表。每个人都会有糟糕的日子,在这种情况下,你应该休息一下:尽量放慢速度并下线。
阅读现有代码库#
阅读和理解现有的代码库总是一项困难的任务,需要时间和经验才能掌握。即使我们通常试图编写简单的代码,鉴于项目的庞大规模,理解代码一开始似乎也会让人不知所措。以下是一些可能使这项任务更容易和更快的技巧(无特定顺序)。
熟悉scikit-learn 对象的 API:了解fit、predict、transform等的使用目的。
在深入阅读函数/类的代码之前,首先阅读文档字符串,并尝试了解每个参数/属性的作用。停下来思考一下“如果我必须自己做这件事,我会怎么做?” 也可能会有所帮助。
最棘手的事情通常是确定哪些代码部分是相关的,哪些是不相关的。在 scikit-learn 中,进行了**大量**的输入检查,尤其是在fit方法的开头。有时,只有一小部分代码在实际工作。例如,查看
fit方法LinearRegression,你可能正在寻找的只是对scipy.linalg.lstsq的调用,但它被埋在多行输入检查和各种参数的处理中。由于使用了继承,一些方法可能在父类中实现。所有估计器至少继承自
BaseEstimator,并继承自Mixin类(例如ClassifierMixin),这使得根据估计器的性质(分类器、回归器、转换器等)能够实现默认行为。有时,阅读给定函数的测试会让你了解其预期用途。你可以使用
git grep(见下文)查找为函数编写的全部测试。特定函数/类的多数测试都位于模块的tests/文件夹下。你经常会看到如下代码:
out = Parallel(...)(delayed(some_function)(param) for param in some_iterable)。这使用Joblib并行运行some_function。out然后是一个可迭代对象,包含每次调用some_function返回的值。我们使用Cython编写快速代码。Cython 代码位于
.pyx和.pxd文件中。Cython 代码具有更类似 C 的风格:我们使用指针,执行手动内存分配等。在这里,具备一些 C/C++ 的基本经验几乎是必须的。更多信息请参见Cython最佳实践、约定和知识。掌握你的工具。
配置
git blame以忽略将代码风格迁移到black的提交。git config blame.ignoreRevsFile .git-blame-ignore-revs在 black 的文档中查找更多关于避免破坏 git blame 的信息。