轮廓系数#
- sklearn.metrics.silhouette_score(X, labels, *, metric='euclidean', sample_size=None, random_state=None, **kwds)[source]#
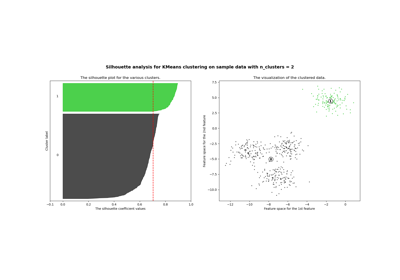
计算所有样本的平均轮廓系数。
轮廓系数是使用每个样本的平均簇内距离(
a)和平均最近簇距离(b)计算的。样本的轮廓系数为(b - a) / max(a, b)。明确地说,b是样本与其不属于的最近簇之间的距离。请注意,只有当标签数量为2 <= n_labels <= n_samples - 1时,轮廓系数才定义。此函数返回所有样本的平均轮廓系数。要获得每个样本的值,请使用
silhouette_samples。最佳值为 1,最差值为 -1。接近 0 的值表示簇重叠。负值通常表示样本被分配到错误的簇,因为不同的簇更相似。
在用户指南中了解更多信息。
- 参数:
- X形状为 (n_samples_a, n_samples_a)(如果 metric == “precomputed”)或 (n_samples_a, n_features)(否则)的{数组型,稀疏矩阵}
样本间的成对距离数组,或特征数组。
- labels形状为 (n_samples,) 的数组型
每个样本的预测标签。
- metricstr 或可调用对象,默认为 ‘euclidean’
计算特征数组中实例之间距离时使用的度量。如果 metric 是字符串,它必须是
pairwise_distances允许的选项之一。如果X是距离数组本身,请使用metric="precomputed"。- sample_sizeint,默认为 None
在数据的随机子集上计算轮廓系数时使用的样本大小。如果
sample_size is None,则不使用采样。- random_stateint、RandomState 实例或 None,默认为 None
确定用于选择样本子集的随机数生成。当
sample_size is not None时使用。传递一个整数以在多次函数调用中获得可重复的结果。参见词汇表。- **kwds可选关键字参数
任何其他参数都直接传递给距离函数。如果使用 scipy.spatial.distance 度量,参数仍然取决于度量。有关用法示例,请参见 scipy 文档。
- 返回:
- silhouettefloat
所有样本的平均轮廓系数。
参考文献
[2]示例
>>> from sklearn.datasets import make_blobs >>> from sklearn.cluster import KMeans >>> from sklearn.metrics import silhouette_score >>> X, y = make_blobs(random_state=42) >>> kmeans = KMeans(n_clusters=2, random_state=42) >>> silhouette_score(X, kmeans.fit_predict(X)) np.float64(0.49...)