多项式计数草图#
- class sklearn.kernel_approximation.PolynomialCountSketch(*, gamma=1.0, degree=2, coef0=0, n_components=100, random_state=None)[source]#
基于张量草图的多项式核近似。
实现张量草图,通过使用快速傅里叶变换 (FFT)有效计算向量与其自身的外部乘积的计数草图来近似多项式核的特征映射。
K(X, Y) = (gamma * <X, Y> + coef0)^degree
更多信息请阅读 用户指南。
版本 0.24 中新增。
- 参数:
- gammafloat, default=1.0
将被近似的多项式核的参数。
- degreeint, default=2
将被近似的多项式核的阶数。
- coef0int, default=0
将被近似的多项式核的常数项。
- n_componentsint, default=100
输出特征空间的维度。通常,为了获得良好的性能,
n_components应该大于输入样本中特征的数量。最佳分数/运行时间平衡通常在n_components= 10 *n_features附近实现,但这取决于所使用的特定数据集。- random_stateint, RandomState 实例, default=None
确定 indexHash 和 bitHash 初始化的随机数生成。传递一个整数以便在多次函数调用中获得可重复的结果。参见 词汇表。
- 属性:
- indexHash_ndarray of shape (degree, n_features), dtype=int64
范围在 [0, n_components) 内的索引数组,用于表示用于计数草图计算的 2-wise 独立哈希函数。
- bitHash_ndarray of shape (degree, n_features), dtype=float32
包含 {+1, -1} 中随机条目的数组,用于表示用于计数草图计算的 2-wise 独立哈希函数。
- n_features_in_int
在 拟合期间看到的特征数量。
版本 0.24 中新增。
- feature_names_in_ndarray of shape (
n_features_in_,) 在 拟合期间看到的特征名称。仅当
X的特征名称全部为字符串时才定义。版本 1.0 中新增。
另请参见
AdditiveChi2Sampler加性 chi2 核的近似特征映射。
Nystroem使用训练数据的子集近似核映射。
RBFSampler使用随机傅里叶特征近似 RBF 核特征映射。
SkewedChi2Sampler“偏斜卡方”核的近似特征映射。
sklearn.metrics.pairwise.kernel_metrics内置核列表。
示例
>>> from sklearn.kernel_approximation import PolynomialCountSketch >>> from sklearn.linear_model import SGDClassifier >>> X = [[0, 0], [1, 1], [1, 0], [0, 1]] >>> y = [0, 0, 1, 1] >>> ps = PolynomialCountSketch(degree=3, random_state=1) >>> X_features = ps.fit_transform(X) >>> clf = SGDClassifier(max_iter=10, tol=1e-3) >>> clf.fit(X_features, y) SGDClassifier(max_iter=10) >>> clf.score(X_features, y) 1.0
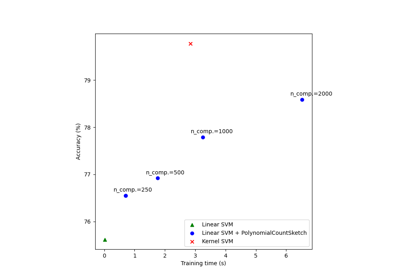
有关更详细的用法示例,请参见 使用多项式核近似进行可扩展学习
- fit(X, y=None)[source]#
使用 X 拟合模型。
初始化内部变量。该方法不需要关于数据分布的信息,因此我们只关心 X 中的 n_features。
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
训练数据,其中
n_samples是样本数,n_features是特征数。- yarray-like of shape (n_samples,) or (n_samples, n_outputs), default=None
目标值(对于无监督变换则为 None)。
- 返回:
- selfobject
返回实例本身。
- fit_transform(X, y=None, **fit_params)[source]#
拟合数据,然后转换它。
使用可选参数
fit_params将变换器拟合到X和y,并返回X的转换版本。- 参数:
- Xarray-like of shape (n_samples, n_features)
输入样本。
- yarray-like of shape (n_samples,) or (n_samples, n_outputs), default=None
目标值(对于无监督变换则为 None)。
- **fit_paramsdict
附加拟合参数。
- 返回:
- X_newndarray array of shape (n_samples, n_features_new)
转换后的数组。
- get_feature_names_out(input_features=None)[source]#
获取转换后的输出特征名称。
输出的特征名称将以小写的类名作为前缀。例如,如果转换器输出3个特征,则输出的特征名称为:
["class_name0", "class_name1", "class_name2"]。- 参数:
- input_features类似数组的 str 或 None,默认值=None
仅用于使用在
fit中看到的名称验证特征名称。
- 返回:
- feature_names_outstr 对象的ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看用户指南,了解路由机制的工作原理。
- 返回:
- routingMetadataRequest
一个
MetadataRequest封装了路由信息。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deep布尔值,默认值=True
如果为 True,则将返回此估计器和作为估计器的包含子对象的参数。
- 返回:
- params字典
参数名称与其值的映射。
- set_output(*, transform=None)[source]#
设置输出容器。
请参阅介绍 set_output API,了解如何使用该 API 的示例。
- 参数:
- transform{"default", "pandas", "polars"},默认值=None
配置
transform和fit_transform的输出。"default":转换器的默认输出格式"pandas":DataFrame 输出"polars":Polars 输出None:转换配置保持不变
版本 1.4 中新增:
"polars"选项已添加。
- 返回:
- self估计器实例
估计器实例。