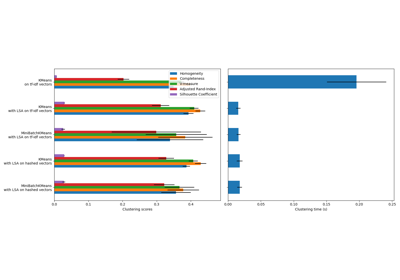
MiniBatchKMeans#
- class sklearn.cluster.MiniBatchKMeans(n_clusters=8, *, init='k-means++', max_iter=100, batch_size=1024, verbose=0, compute_labels=True, random_state=None, tol=0.0, max_no_improvement=10, init_size=None, n_init='auto', reassignment_ratio=0.01)[source]#
Mini-Batch K均值聚类。
更多信息请参见 用户指南。
- 参数:
- n_clustersint, 默认值=8
要形成的簇的数量以及要生成的质心的数量。
- init{‘k-means++’, ‘random’}, 可调用对象或 shape 为 (n_clusters, n_features) 的数组,默认值='k-means++'
初始化方法
‘k-means++’ : 使用基于点对整体惯性贡献的经验概率分布的采样来选择初始簇质心。此技术可加快收敛速度。实现的算法是“贪婪 k-means++”。它与普通 k-means++ 的区别在于,它在每个采样步骤中进行多次尝试,并在其中选择最佳质心。
‘random’: 从数据中随机选择
n_clusters个观测值(行)作为初始质心。如果传递数组,则其形状应为 (n_clusters, n_features),并给出初始中心。
如果传递可调用对象,则它应接受参数 X、n_clusters 和随机状态,并返回初始化。
- max_iterint, 默认值=100
在停止之前遍历完整数据集的最大迭代次数,独立于任何提前停止标准启发式方法。
- batch_sizeint, 默认值=1024
小批次的大小。为了加快计算速度,您可以将
batch_size设置为大于 256 * 核心数,以便在所有核心上启用并行处理。1.0 版本中的变更:
batch_size的默认值从 100 更改为 1024。- verboseint, 默认值=0
详细模式。
- compute_labelsbool, 默认值=True
在拟合中最小批次优化收敛后,计算完整数据集的标签分配和惯性。
- random_stateint,RandomState 实例或 None,默认值=None
确定质心初始化和随机重新分配的随机数生成。使用整数可以使随机性确定性。参见 词汇表。
- tolfloat, 默认值=0.0
根据通过平滑的、方差归一化的平均中心平方位置变化来衡量的相对中心变化来控制提前停止。这种提前停止启发式方法更接近于算法的批量变体中使用的启发式方法,但与惯性启发式方法相比,会稍微增加计算和内存开销。
要禁用基于归一化中心变化的收敛检测,请将 tol 设置为 0.0(默认值)。
- max_no_improvementint, 默认值=10
根据不会在平滑惯性上产生改进的连续小批次的数目来控制提前停止。
要禁用基于惯性的收敛检测,请将 max_no_improvement 设置为 None。
- init_sizeint, 默认值=None
随机采样以加快初始化速度(有时会以牺牲准确性为代价)的样本数:唯一的算法是通过对数据的随机子集运行批量 KMeans 来初始化的。这需要大于 n_clusters。
如果
None,则启发式方法为init_size = 3 * batch_size(如果3 * batch_size < n_clusters),否则init_size = 3 * n_clusters。- n_init‘auto’ 或 int,默认值=”auto”
尝试的随机初始化次数。与 KMeans 相反,算法只运行一次,使用根据惯性测量的最佳
n_init初始化。对于稀疏高维问题,建议进行多次运行(参见 使用 k-means 聚类稀疏数据)。当
n_init='auto'时,运行次数取决于 init 的值:如果使用init='random'或init是可调用对象,则为 3;如果使用init='k-means++'或init是类数组对象,则为 1。1.2 版本中添加: 为
n_init添加了 “auto” 选项。1.4 版本中的变更: 版本中的
n_init默认值更改为'auto'。- reassignment_ratiofloat, 默认值=0.01
控制中心最大计数分数的重新分配分数。较高的值意味着低计数中心更容易重新分配,这意味着模型需要更长时间才能收敛,但应该收敛到更好的聚类。但是,过高的值可能会导致收敛问题,尤其是在小批量大小的情况下。
- 属性:
- cluster_centers_shape 为 (n_clusters, n_features) 的 ndarray
聚类中心的坐标。
- labels_shape 为 (n_samples,) 的 ndarray
每个点的标签(如果 compute_labels 设置为 True)。
- inertia_float
如果 `compute_labels` 设置为 True,则此值为所选分区的惯性准则值。如果 `compute_labels` 设置为 False,则它是基于批量惯性指数加权平均值的惯性近似值。惯性定义为样本到其聚类中心的平方距离之和,如果提供样本权重,则按样本权重加权。
- n_iter_int
遍历完整数据集的迭代次数。
- n_steps_int
已处理的小批量数量。
版本 1.0 中新增。
- n_features_in_int
在 fit 期间看到的特征数量。
版本 0.24 中新增。
- feature_names_in_ndarray of shape (
n_features_in_,) 在 fit 期间看到的特征名称。仅当
X的特征名称全部为字符串时才定义。版本 1.0 中新增。
另请参见
KMeans基于 Lloyd 算法的经典聚类方法实现。每次迭代都会消耗整个输入数据集。
备注
参见 https://www.eecs.tufts.edu/~dsculley/papers/fastkmeans.pdf
当数据集中的点数太少时,某些中心可能会重复,这意味着在请求的聚类数量和返回的聚类数量方面,正确的聚类并不总是匹配。一种解决方案是设置
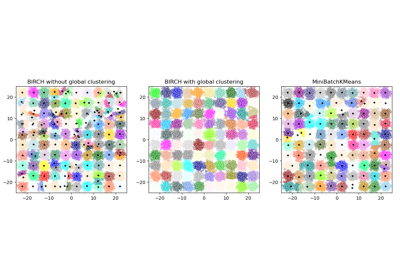
reassignment_ratio=0,这可以防止对太小的聚类进行重新分配。请参阅 比较 BIRCH 和 MiniBatchKMeans,了解与
BIRCH的比较。示例
>>> from sklearn.cluster import MiniBatchKMeans >>> import numpy as np >>> X = np.array([[1, 2], [1, 4], [1, 0], ... [4, 2], [4, 0], [4, 4], ... [4, 5], [0, 1], [2, 2], ... [3, 2], [5, 5], [1, -1]]) >>> # manually fit on batches >>> kmeans = MiniBatchKMeans(n_clusters=2, ... random_state=0, ... batch_size=6, ... n_init="auto") >>> kmeans = kmeans.partial_fit(X[0:6,:]) >>> kmeans = kmeans.partial_fit(X[6:12,:]) >>> kmeans.cluster_centers_ array([[3.375, 3. ], [0.75 , 0.5 ]]) >>> kmeans.predict([[0, 0], [4, 4]]) array([1, 0], dtype=int32) >>> # fit on the whole data >>> kmeans = MiniBatchKMeans(n_clusters=2, ... random_state=0, ... batch_size=6, ... max_iter=10, ... n_init="auto").fit(X) >>> kmeans.cluster_centers_ array([[3.55102041, 2.48979592], [1.06896552, 1. ]]) >>> kmeans.predict([[0, 0], [4, 4]]) array([1, 0], dtype=int32)
- fit(X, y=None, sample_weight=None)[source]#
通过将 X 分块成小批量来计算质心。
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
要聚类的训练样本。需要注意的是,数据将转换为 C 顺序,如果给定的数据不是 C 连续的,则会造成内存复制。如果传递的是稀疏矩阵,则如果它不是 CSR 格式,则会进行复制。
- y忽略
未使用,出于 API 一致性约定而保留在此处。
- sample_weightarray-like of shape (n_samples,), default=None
X 中每个观测值的权重。如果为 None,则所有观测值都分配相同的权重。如果 `init` 是可调用对象或用户提供的数组,则在初始化期间不使用 `sample_weight`。
版本 0.20 中新增。
- 返回:
- selfobject
已拟合的估计器。
- fit_predict(X, y=None, sample_weight=None)[source]#
计算聚类中心并预测每个样本的聚类索引。
便捷方法;等效于调用 fit(X) 后跟 predict(X)。
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
要转换的新数据。
- y忽略
未使用,出于 API 一致性约定而保留在此处。
- sample_weightarray-like of shape (n_samples,), default=None
X 中每个观测值的权重。如果为 None,则所有观测值都分配相同的权重。
- 返回:
- labelsndarray of shape (n_samples,)
每个样本所属聚类的索引。
- fit_transform(X, y=None, sample_weight=None)[source]#
计算聚类并将 X 转换为聚类距离空间。
等效于 fit(X).transform(X),但实现效率更高。
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
要转换的新数据。
- y忽略
未使用,出于 API 一致性约定而保留在此处。
- sample_weightarray-like of shape (n_samples,), default=None
X 中每个观测值的权重。如果为 None,则所有观测值都分配相同的权重。
- 返回:
- X_newndarray of shape (n_samples, n_clusters)
在新空间中转换的 X。
- get_feature_names_out(input_features=None)[source]#
获取转换的输出特征名称。
输出的特征名称将以小写的类名作为前缀。例如,如果转换器输出 3 个特征,则输出的特征名称为:
["class_name0", "class_name1", "class_name2"]。- 参数:
- input_featuresarray-like of str or None, default=None
仅用于使用在
fit中看到的名称验证特征名称。
- 返回:
- feature_names_outndarray of str objects
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看 用户指南,了解路由机制的工作原理。
- 返回:
- routingMetadataRequest
一个
MetadataRequest封装路由信息。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,则将返回此估计器及其包含的子对象(也是估计器)的参数。
- 返回:
- paramsdict
参数名称与其值的映射。
- partial_fit(X, y=None, sample_weight=None)[source]#
使用单个小批量 X 更新 k 均值估计。
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
要聚类的训练样本。需要注意的是,数据将转换为 C 顺序,如果给定的数据不是 C 连续的,则会造成内存复制。如果传递的是稀疏矩阵,则如果它不是 CSR 格式,则会进行复制。
- y忽略
未使用,出于 API 一致性约定而保留在此处。
- sample_weightarray-like of shape (n_samples,), default=None
X 中每个观测值的权重。如果为 None,则所有观测值都分配相同的权重。如果 `init` 是可调用对象或用户提供的数组,则在初始化期间不使用 `sample_weight`。
- 返回:
- selfobject
返回更新后的估计器。
- predict(X)[source]#
预测 X 中每个样本所属的最近集群。
在矢量量化文献中,
cluster_centers_称为码本,predict返回的每个值都是码本中最近代码的索引。- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
要预测的新数据。
- 返回:
- labelsndarray of shape (n_samples,)
每个样本所属聚类的索引。
- score(X, y=None, sample_weight=None)[source]#
K 均值目标函数中 X 值的反值。
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
新数据。
- y忽略
未使用,出于 API 一致性约定而保留在此处。
- sample_weightarray-like of shape (n_samples,), default=None
X 中每个观测值的权重。如果为 None,则所有观测值都分配相同的权重。
- 返回:
- scorefloat
K 均值目标函数中 X 值的反值。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MiniBatchKMeans[source]#
请求传递给
fit方法的元数据。请注意,只有当
enable_metadata_routing=True时(参见sklearn.set_config),此方法才相关。请参见用户指南,了解路由机制的工作原理。每个参数的选项为
True:请求元数据,并在提供时传递给fit。如果未提供元数据,则忽略请求。False:不请求元数据,元估计器不会将其传递给fit。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:元数据应使用此给定的别名而不是原始名称传递给元估计器。
默认值(
sklearn.utils.metadata_routing.UNCHANGED)保留现有的请求。这允许您更改某些参数的请求,而无需更改其他参数。版本 1.3 中新增。
注意
仅当将此估计器用作元估计器的子估计器时(例如,在
Pipeline内部使用)此方法才相关。否则,它无效。- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
fit中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。
- set_output(*, transform=None)[source]#
设置输出容器。
参见介绍 set_output API,了解如何使用 API 的示例。
- 参数:
- transform{“default”, “pandas”, “polars”}, default=None
配置
transform和fit_transform的输出。"default":转换器的默认输出格式"pandas":DataFrame 输出"polars":Polars 输出None:转换配置保持不变
版本 1.4 中新增:
"polars"选项已添加。
- 返回:
- selfestimator instance
估计器实例。
- set_params(**params)[source]#
设置此估计器的参数。
此方法适用于简单的估计器以及嵌套对象(例如
Pipeline)。后者具有<component>__<parameter>形式的参数,因此可以更新嵌套对象的每个组件。- 参数:
- **params**dict
估计器参数。
- 返回:
- selfestimator instance
估计器实例。
- set_partial_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MiniBatchKMeans[source]#
请求传递给
partial_fit方法的元数据。请注意,只有当
enable_metadata_routing=True时(参见sklearn.set_config),此方法才相关。请参见用户指南,了解路由机制的工作原理。每个参数的选项为
True:请求元数据,如果提供则传递给partial_fit。如果未提供元数据,则忽略请求。False:不请求元数据,元估计器不会将其传递给partial_fit。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:元数据应使用此给定的别名而不是原始名称传递给元估计器。
默认值(
sklearn.utils.metadata_routing.UNCHANGED)保留现有的请求。这允许您更改某些参数的请求,而无需更改其他参数。版本 1.3 中新增。
注意
仅当将此估计器用作元估计器的子估计器时(例如,在
Pipeline内部使用)此方法才相关。否则,它无效。- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
partial_fit方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MiniBatchKMeans[source]#
请求传递给
score方法的元数据。请注意,只有当
enable_metadata_routing=True时(参见sklearn.set_config),此方法才相关。请参见用户指南,了解路由机制的工作原理。每个参数的选项为
True:请求元数据,如果提供则传递给score。如果未提供元数据,则忽略请求。False:不请求元数据,元估计器不会将其传递给score。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:元数据应使用此给定的别名而不是原始名称传递给元估计器。
默认值(
sklearn.utils.metadata_routing.UNCHANGED)保留现有的请求。这允许您更改某些参数的请求,而无需更改其他参数。版本 1.3 中新增。
注意
仅当将此估计器用作元估计器的子估计器时(例如,在
Pipeline内部使用)此方法才相关。否则,它无效。- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
score方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。