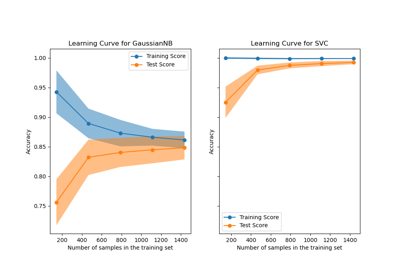
学习曲线显示#
- class sklearn.model_selection.LearningCurveDisplay(*, train_sizes, train_scores, test_scores, score_name=None)[source]#
学习曲线可视化。
建议使用
from_estimator创建LearningCurveDisplay实例。所有参数都存储为属性。更多信息请参见 用户指南,了解可视化 API 的一般信息,以及 学习曲线可视化的详细文档。
版本 1.2 中新增。
- 参数:
- train_sizes形状为 (n_unique_ticks,) 的 ndarray
用于生成学习曲线的训练样本数量。
- train_scores形状为 (n_ticks, n_cv_folds) 的 ndarray
训练集上的得分。
- test_scores形状为 (n_ticks, n_cv_folds) 的 ndarray
测试集上的得分。
- score_namestr,默认为 None
在
learning_curve中使用的得分的名称。它将覆盖从scoring参数推断出的名称。如果score为None,如果negate_score为False,则使用"Score",否则使用"Negative score"。如果scoring是字符串或可调用对象,我们将推断名称。我们将_替换为空格,并将首字母大写。如果negate_score为False,我们将删除neg_并将其替换为"Negative",否则直接删除。
- 属性:
- ax_matplotlib Axes
包含学习曲线的 Axes。
- figure_matplotlib Figure
包含学习曲线的图形。
- errorbar_matplotlib Artist 列表或 None
当
std_display_style为"errorbar"时,这是一个matplotlib.container.ErrorbarContainer对象列表。如果使用其他样式,则errorbar_为None。- lines_matplotlib Artist 列表或 None
当
std_display_style为"fill_between"时,这是一个matplotlib.lines.Line2D对象列表,对应于平均训练和测试分数。如果使用其他样式,则line_为None。- fill_between_matplotlib Artist 列表或 None
当
std_display_style为"fill_between"时,这是一个matplotlib.collections.PolyCollection对象列表。如果使用其他样式,则fill_between_为None。
另请参见
示例
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import load_iris >>> from sklearn.model_selection import LearningCurveDisplay, learning_curve >>> from sklearn.tree import DecisionTreeClassifier >>> X, y = load_iris(return_X_y=True) >>> tree = DecisionTreeClassifier(random_state=0) >>> train_sizes, train_scores, test_scores = learning_curve( ... tree, X, y) >>> display = LearningCurveDisplay(train_sizes=train_sizes, ... train_scores=train_scores, test_scores=test_scores, score_name="Score") >>> display.plot() <...> >>> plt.show()
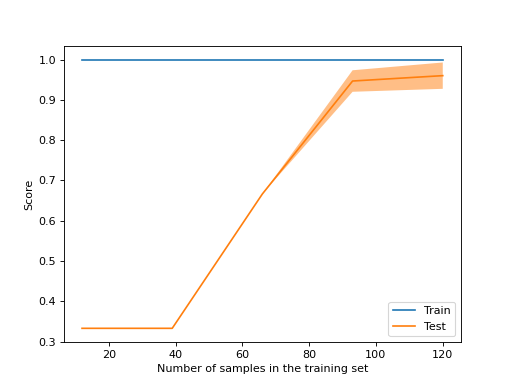
- classmethod from_estimator(estimator, X, y, *, groups=None, train_sizes=array([0.1, 0.33, 0.55, 0.78, 1.]), cv=None, scoring=None, exploit_incremental_learning=False, n_jobs=None, pre_dispatch='all', verbose=0, shuffle=False, random_state=None, error_score=nan, fit_params=None, ax=None, negate_score=False, score_name=None, score_type='both', std_display_style='fill_between', line_kw=None, fill_between_kw=None, errorbar_kw=None)[source]#
根据估计器创建学习曲线显示。
更多信息请参见 用户指南,了解可视化 API 的一般信息,以及 学习曲线可视化的详细文档。
- 参数:
- estimator实现“fit”和“predict”方法的对象类型
对于每个验证,都会克隆该类型的一个对象。
- X形状为 (n_samples, n_features) 的类数组
训练数据,其中
n_samples是样本数,n_features是特征数。- y形状为 (n_samples,) 或 (n_samples, n_outputs) 或 None 的类数组
针对分类或回归的与 X 相关的目标;对于无监督学习则为 None。
- groups形状为 (n_samples,) 的类数组,默认为 None
将数据集拆分为训练集/测试集时使用的样本分组标签。仅与“Group” cv 实例(例如,
GroupKFold)结合使用。- train_sizes形状为 (n_ticks,) 的类数组,默认为 np.linspace(0.1, 1.0, 5)
将用于生成学习曲线的训练样本的相对数或绝对数。如果 dtype 为浮点数,则将其视为训练集最大大小(由所选验证方法确定)的一部分,即它必须在 (0, 1] 内。否则,它将被解释为训练集的绝对大小。请注意,对于分类,样本数量通常必须足够大,以便至少包含每个类别的一个样本。
- cv整数、交叉验证生成器或可迭代对象,默认为 None
确定交叉验证拆分策略。cv 的可能输入为:
None,使用默认的 5 折交叉验证;
整数,指定
(Stratified)KFold中的折叠数;产生 (train, test) 拆分作为索引数组的可迭代对象。
对于 int/None 输入,如果估计器是分类器并且
y是二元或多类,则使用StratifiedKFold。在所有其他情况下,使用KFold。这些分割器使用shuffle=False实例化,因此拆分在调用之间将保持一致。请参阅 用户指南,了解此处可以使用各种交叉验证策略。
- scoring字符串或可调用对象,默认为 None
字符串(请参阅 评分参数:定义模型评估规则)或评分可调用对象/函数,其签名为
scorer(estimator, X, y)(请参阅 可调用评分器)。- exploit_incremental_learning布尔值,默认为 False
如果估计器支持增量学习,这将用于加快不同训练集大小的拟合速度。
- n_jobs整数,默认为 None
并行运行的作业数。估计器的训练和分数计算在不同的训练集和测试集上并行化。
None表示 1,除非在joblib.parallel_backend上下文中。-1表示使用所有处理器。有关详细信息,请参阅 词汇表。- pre_dispatch整数或字符串,默认为“all”
并行执行的预调度作业数(默认为 all)。此选项可以减少分配的内存。字符串可以是类似“2*n_jobs”的表达式。
- verbose整数,默认为 0
控制详细程度:值越高,显示的消息越多。
- shuffle布尔值,默认为 False
是否根据 `train_sizes` 在获取训练数据的开头部分之前对其进行洗牌。
- random_state整数、RandomState 实例或 None,默认为 None
当
shuffle为 True 时使用。传递整数可在多次函数调用中获得可重复的结果。请参阅 词汇表。- error_score“raise”或数字,默认为 np.nan
如果估计器拟合发生错误,则分配给分数的值。如果设置为“raise”,则会引发错误。如果给出数值,则会引发 FitFailedWarning。
- fit_params字典,默认为 None
传递给估计器 fit 方法的参数。
- axmatplotlib Axes,默认为 None
要绘制的 Axes 对象。如果为
None,则会创建一个新的图形和 Axes。- negate_score布尔值,默认为 False
是否否定通过
learning_curve获得的分数。当使用scikit-learn中由neg_*表示的误差时,这特别有用。- score_namestr,默认为 None
用于装饰绘图 y 轴的评分名称。它将覆盖从
scoring参数推断的名称。如果score为None,如果negate_score为False,则我们使用"Score",否则使用"Negative score"。如果scoring是字符串或可调用对象,我们将推断名称。我们将_替换为空格,并将第一个字母大写。如果negate_score为False,我们将删除neg_并将其替换为"Negative",否则将其删除。- score_type{“test”, “train”, “both”},默认为“both”
要绘制的评分类型。可以是
"test"、"train"或"both"之一。- std_display_style{“errorbar”, “fill_between”} 或 None,默认为“fill_between”
用于显示围绕平均分数的标准差分数的样式。如果为
None,则不显示标准差的表示。- line_kwdict, default=None
传递给用于绘制平均分数的
plt.plot的附加关键字参数。- fill_between_kwdict, default=None
传递给用于绘制分数标准差的
plt.fill_between的附加关键字参数。- errorbar_kwdict, default=None
传递给用于绘制平均分数和标准差分数的
plt.errorbar的附加关键字参数。
- 返回:
- display
LearningCurveDisplay 存储计算值的對象。
- display
示例
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import load_iris >>> from sklearn.model_selection import LearningCurveDisplay >>> from sklearn.tree import DecisionTreeClassifier >>> X, y = load_iris(return_X_y=True) >>> tree = DecisionTreeClassifier(random_state=0) >>> LearningCurveDisplay.from_estimator(tree, X, y) <...> >>> plt.show()
- plot(ax=None, *, negate_score=False, score_name=None, score_type='both', std_display_style='fill_between', line_kw=None, fill_between_kw=None, errorbar_kw=None)[source]#
绘制可视化。
- 参数:
- axmatplotlib Axes,默认为 None
要绘制的 Axes 对象。如果为
None,则会创建一个新的图形和 Axes。- negate_score布尔值,默认为 False
是否否定通过
learning_curve获得的分数。当使用scikit-learn中由neg_*表示的误差时,这特别有用。- score_namestr,默认为 None
用于装饰绘图 y 轴的评分名称。它将覆盖从
scoring参数推断的名称。如果score为None,如果negate_score为False,则我们使用"Score",否则使用"Negative score"。如果scoring是字符串或可调用对象,我们将推断名称。我们将_替换为空格,并将第一个字母大写。如果negate_score为False,我们将删除neg_并将其替换为"Negative",否则将其删除。- score_type{“test”, “train”, “both”},默认为“both”
要绘制的评分类型。可以是
"test"、"train"或"both"之一。- std_display_style{“errorbar”, “fill_between”} 或 None,默认为“fill_between”
用于显示围绕平均分数的标准差分数的样式。如果为 None,则不显示标准差表示。
- line_kwdict, default=None
传递给用于绘制平均分数的
plt.plot的附加关键字参数。- fill_between_kwdict, default=None
传递给用于绘制分数标准差的
plt.fill_between的附加关键字参数。- errorbar_kwdict, default=None
传递给用于绘制平均分数和标准差分数的
plt.errorbar的附加关键字参数。
- 返回:
- display
LearningCurveDisplay 存储计算值的對象。
- display