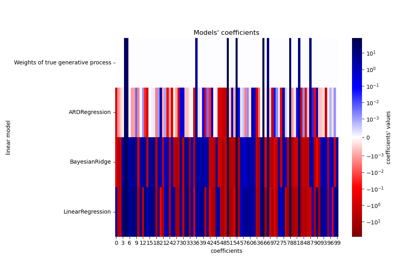
ARD 回归#
- class sklearn.linear_model.ARDRegression(*, max_iter=300, tol=0.001, alpha_1=1e-06, alpha_2=1e-06, lambda_1=1e-06, lambda_2=1e-06, compute_score=False, threshold_lambda=10000.0, fit_intercept=True, copy_X=True, verbose=False)[source]#
贝叶斯ARD回归。
使用ARD先验拟合回归模型的权重。假设回归模型的权重服从高斯分布。同时估计参数lambda(权重分布的精度)和alpha(噪声分布的精度)。估计通过迭代过程(证据最大化)完成。
更多信息请参见用户指南。
- 参数:
- max_iterint, default=300
最大迭代次数。
1.3版本中的更改。
- tolfloat, default=1e-3
如果w收敛,则停止算法。
- alpha_1float, default=1e-6
超参数:alpha参数的Gamma分布先验的形状参数。
- alpha_2float, default=1e-6
超参数:alpha参数的Gamma分布先验的逆尺度参数(率参数)。
- lambda_1float, default=1e-6
超参数:lambda参数的Gamma分布先验的形状参数。
- lambda_2float, default=1e-6
超参数:lambda参数的Gamma分布先验的逆尺度参数(率参数)。
- compute_scorebool, default=False
如果为True,则计算模型每一步的目标函数。
- threshold_lambdafloat, default=10 000
移除(剪枝)具有高精度的权重的阈值。
- fit_interceptbool, default=True
是否计算此模型的截距。如果设置为false,则计算中不会使用截距(即,数据应居中)。
- copy_Xbool, default=True
如果为True,则复制X;否则,它可能会被覆盖。
- verbosebool, default=False
拟合模型时的详细模式。
- 属性:
- coef_array-like of shape (n_features,)
回归模型的系数(分布的均值)
- alpha_float
估计的噪声精度。
- lambda_array-like of shape (n_features,)
估计的权重精度。
- sigma_array-like of shape (n_features, n_features)
估计的权重的方差-协方差矩阵
- scores_float
如果计算,则为目标函数的值(要最大化)
- n_iter_int
达到停止准则的实际迭代次数。
1.3版本中添加。
- intercept_float
决策函数中的独立项。如果
fit_intercept = False,则设置为0.0。- X_offset_float
如果
fit_intercept=True,则偏移量用于将数据中心化到零均值。否则设置为np.zeros(n_features)。- X_scale_float
设置为np.ones(n_features)。
- n_features_in_int
在fit期间看到的特征数量。
0.24版本中添加。
- feature_names_in_ndarray of shape (
n_features_in_,) 在fit期间看到的特征名称。仅当
X具有全是字符串的特征名称时才定义。1.0版本中添加。
另请参见
BayesianRidge贝叶斯岭回归。
备注
有关示例,请参见examples/linear_model/plot_ard.py。
参考文献
D. J. C. MacKay, Bayesian nonlinear modeling for the prediction competition, ASHRAE Transactions, 1994.
R. Salakhutdinov, Lecture notes on Statistical Machine Learning, http://www.utstat.toronto.edu/~rsalakhu/sta4273/notes/Lecture2.pdf#page=15 他们的beta是我们的
self.alpha_,他们的alpha是我们的self.lambda_。ARD与幻灯片略有不同:仅保留self.lambda_ < self.threshold_lambda的维度/特征,其余的将被丢弃。示例
>>> from sklearn import linear_model >>> clf = linear_model.ARDRegression() >>> clf.fit([[0,0], [1, 1], [2, 2]], [0, 1, 2]) ARDRegression() >>> clf.predict([[1, 1]]) array([1.])
- fit(X, y)[source]#
根据给定的训练数据和参数拟合模型。
迭代过程以最大化证据。
- 参数:
- Xarray-like of shape (n_samples, n_features)
训练向量,其中
n_samples是样本数,n_features是特征数。- yarray-like of shape (n_samples,)
目标值(整数)。如果必要,将转换为X的数据类型。
- 返回:
- selfobject
已拟合的估计器。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看用户指南,了解路由机制的工作原理。
- 返回:
- routingMetadataRequest
一个
MetadataRequest,封装了路由信息。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为True,则将返回此估计器和包含的作为估计器的子对象的参数。
- 返回:
- paramsdict
参数名称与其值的映射。
- predict(X, return_std=False)[source]#
使用线性模型进行预测。
除了预测分布的均值外,还可以返回其标准差。
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
样本。
- return_stdbool, default=False
是否返回后验预测的标准差。
- 返回:
- y_meanarray-like of shape (n_samples,)
查询点的预测分布的均值。
- y_stdarray-like of shape (n_samples,)
查询点的预测分布的标准差。
- score(X, y, sample_weight=None)[source]#
返回预测的决定系数。
决定系数\(R^2\)定义为\((1 - \frac{u}{v})\),其中\(u\)是残差平方和
((y_true - y_pred)** 2).sum(),\(v\)是总平方和((y_true - y_true.mean()) ** 2).sum()。最佳分数为1.0,也可能为负值(因为模型可以任意差)。一个始终预测y期望值的常数模型,忽略输入特征,其\(R^2\)分数为0.0。- 参数:
- Xarray-like of shape (n_samples, n_features)
测试样本。对于某些估计器,这可能是一个预先计算的核矩阵,或者是一个形状为
(n_samples, n_samples_fitted)的泛型对象列表,其中n_samples_fitted是估计器拟合中使用的样本数。- yarray-like of shape (n_samples,) or (n_samples, n_outputs)
X的真值。- sample_weightarray-like of shape (n_samples,), default=None
样本权重。
- 返回:
- scorefloat
self.predict(X)相对于y的\(R^2\)。
备注
从0.23版本开始,在回归器上调用
score时使用的\(R^2\)分数使用multioutput='uniform_average',以保持与r2_score的默认值一致。这会影响所有多输出回归器的score方法(MultiOutputRegressor除外)。
- set_params(**params)[source]#
设置此估计器的参数。
此方法适用于简单的估计器以及嵌套对象(例如
Pipeline)。后者具有<component>__<parameter>形式的参数,因此可以更新嵌套对象的每个组件。- 参数:
- **paramsdict
估计器参数。
- 返回:
- selfestimator instance
估计器实例。
- set_predict_request(*, return_std: bool | None | str = '$UNCHANGED$') ARDRegression[source]#
向
predict方法请求传递的元数据。请注意,只有在
enable_metadata_routing=True时(参见sklearn.set_config),此方法才相关。请参阅用户指南了解路由机制的工作原理。每个参数的选项:
True:请求元数据,如果提供则传递给predict。如果未提供元数据,则忽略请求。False:不请求元数据,元估计器不会将其传递给predict。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:元数据应使用此给定的别名而不是原始名称传递给元估计器。
默认值(
sklearn.utils.metadata_routing.UNCHANGED)保留现有请求。这允许您更改某些参数的请求,而其他参数不变。1.3版本中添加。
注意
只有在此估计器用作元估计器的子估计器时(例如,在
Pipeline中使用),此方法才相关。否则无效。- 参数:
- return_stdstr, True, False 或 None,默认为 sklearn.utils.metadata_routing.UNCHANGED
predict方法中return_std参数的元数据路由。
- 返回:
- selfobject
更新后的对象。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') ARDRegression[source]#
向
score方法请求传递的元数据。请注意,只有在
enable_metadata_routing=True时(参见sklearn.set_config),此方法才相关。请参阅用户指南了解路由机制的工作原理。每个参数的选项:
True:请求元数据,如果提供则传递给score。如果未提供元数据,则忽略请求。False:不请求元数据,元估计器不会将其传递给score。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:元数据应使用此给定的别名而不是原始名称传递给元估计器。
默认值(
sklearn.utils.metadata_routing.UNCHANGED)保留现有请求。这允许您更改某些参数的请求,而其他参数不变。1.3版本中添加。
注意
只有在此估计器用作元估计器的子估计器时(例如,在
Pipeline中使用),此方法才相关。否则无效。- 参数:
- sample_weightstr, True, False 或 None,默认为 sklearn.utils.metadata_routing.UNCHANGED
score方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。