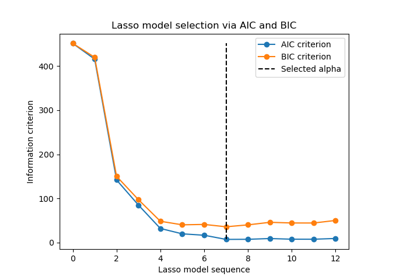
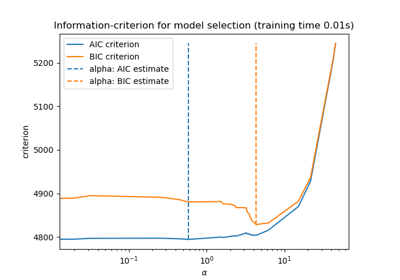
LassoLarsIC#
- class sklearn.linear_model.LassoLarsIC(criterion='aic', *, fit_intercept=True, verbose=False, precompute='auto', max_iter=500, eps=np.float64(2.220446049250313e-16), copy_X=True, positive=False, noise_variance=None)[source]#
使用BIC或AIC进行模型选择的Lasso模型,基于最小角回归 (Lars) 算法拟合。
Lasso的优化目标是
(1 / (2 * n_samples)) * ||y - Xw||^2_2 + alpha * ||w||_1
AIC是赤池信息准则[2],BIC是贝叶斯信息准则[3]。这些准则通过在拟合优度和模型复杂度之间进行权衡,用于选择正则化参数的值。一个好的模型应该很好地解释数据,同时又足够简单。
更多信息请参阅用户指南。
- 参数:
- criterion{‘aic’, ‘bic’}, default=’aic’
使用的准则类型。
- fit_interceptbool, default=True
是否计算该模型的截距。如果设置为False,则计算中不使用截距(即,数据应已中心化)。
- verbosebool 或 int, default=False
设置详细程度。
- precomputebool, ‘auto’ 或 array-like, default=’auto’
是否使用预计算的Gram矩阵来加速计算。如果设置为
'auto',则由算法自动决定。Gram矩阵也可以作为参数传入。- max_iterint, default=500
执行的最大迭代次数。可用于提前停止。
- epsfloat, default=np.finfo(float).eps
计算Cholesky对角因子时的机器精度正则化。对于病态系统,请增大此值。与一些基于迭代优化的算法中的
tol参数不同,此参数不控制优化的容差。- copy_Xbool, default=True
如果为True,则复制X;否则,可能会覆盖X。
- positivebool, default=False
将系数限制为>= 0。请注意,您可能需要移除默认设置为True的fit_intercept。在正值限制下,模型系数不会收敛到小的alpha值的普通最小二乘解。只有逐步Lars-Lasso算法达到的最小alpha值之前的系数(当fit_path=True时为
alphas_[alphas_ > 0.].min())通常与坐标下降Lasso估计器的解一致。因此,只有在预期和/或达到稀疏解的问题中,使用LassoLarsIC才有意义。- noise_variancefloat, default=None
数据的估计噪声方差。如果为
None,则通过OLS模型计算无偏估计。但是,只有在n_samples > n_features + fit_intercept的情况下才有可能。版本1.1中新增。
- 属性:
- coef_array-like of shape (n_features,)
参数向量(公式中的w)。
- intercept_float
决策函数中的独立项。
- alpha_float
信息准则选择的alpha参数。
- alphas_array-like of shape (n_alphas + 1,) 或此类数组列表
每次迭代的最大协方差(绝对值)。
n_alphas为max_iter、n_features或路径中alpha >= alpha_min的节点数中的较小值。如果是列表,则长度为n_targets。- n_iter_int
lars_path 查找 alpha 网格时运行的迭代次数。
- criterion_array-like of shape (n_alphas,)
所有alpha的信息准则(‘aic’,‘bic’)的值。选择信息准则最小的alpha,如[1]中所述。
- noise_variance_float
用于计算准则的数据的估计噪声方差。
版本1.1中新增。
- n_features_in_int
在拟合期间看到的特征数量。
版本0.24中新增。
- feature_names_in_ndarray of shape (
n_features_in_,) 在拟合期间看到的特征名称。仅当
X具有全是字符串的特征名称时才定义。版本1.0中新增。
另请参见
lars_path使用LARS算法计算最小角回归或Lasso路径。
lasso_path使用坐标下降计算Lasso路径。
Lasso使用L1先验作为正则化器的线性模型(又名Lasso)。
LassoCV沿着正则化路径进行迭代拟合的Lasso线性模型。
LassoLars使用最小角回归(也称为Lars)拟合的Lasso模型。
LassoLarsCV使用LARS算法的交叉验证Lasso。
sklearn.decomposition.sparse_encode稀疏编码。
备注
自由度的计算方法如[1]所示。
有关AIC和BIC准则数学公式的更多细节,请参考用户指南。
参考文献
示例
>>> from sklearn import linear_model >>> reg = linear_model.LassoLarsIC(criterion='bic') >>> X = [[-2, 2], [-1, 1], [0, 0], [1, 1], [2, 2]] >>> y = [-2.2222, -1.1111, 0, -1.1111, -2.2222] >>> reg.fit(X, y) LassoLarsIC(criterion='bic') >>> print(reg.coef_) [ 0. -1.11...]
- fit(X, y, copy_X=None)[源码]#
使用X, y作为训练数据拟合模型。
- 参数:
- X形状为 (n_samples, n_features) 的类数组
训练数据。
- y形状为 (n_samples,) 的类数组
目标值。如有必要,将转换为X的数据类型。
- copy_X布尔值,默认为None
如果提供,此参数将覆盖在实例创建时对copy_X的选择。如果为
True,则会复制X;否则,可能会覆盖X。
- 返回:
- self对象
返回自身的一个实例。
- get_metadata_routing()[源码]#
获取此对象的元数据路由。
请查看用户指南,了解路由机制的工作原理。
- 返回:
- routingMetadataRequest
一个
MetadataRequest,封装了路由信息。
- get_params(deep=True)[源码]#
获取此估计器的参数。
- 参数:
- deep布尔值,默认为True
如果为True,则将返回此估计器和作为估计器的包含子对象的参数。
- 返回:
- params字典
参数名称及其值的映射。
- predict(X)[源码]#
使用线性模型进行预测。
- 参数:
- X类数组或稀疏矩阵,形状为 (n_samples, n_features)
样本。
- 返回:
- C数组,形状为 (n_samples,)
返回预测值。
- score(X, y, sample_weight=None)[源码]#
返回预测的决定系数。
决定系数\(R^2\)定义为\((1 - \frac{u}{v})\),其中\(u\)是残差平方和
((y_true - y_pred)** 2).sum(),而\(v\)是总平方和((y_true - y_true.mean()) ** 2).sum()。最佳分数为1.0,也可能为负值(因为模型可以任意差)。一个始终预测y期望值的常数模型,忽略输入特征,其\(R^2\)分数为0.0。- 参数:
- X形状为 (n_samples, n_features) 的类数组
测试样本。对于某些估计器,这可能是一个预计算的核矩阵,或者是一个形状为
(n_samples, n_samples_fitted)的泛型对象列表,其中n_samples_fitted是估计器拟合中使用的样本数。- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组
X的真值。- sample_weight形状为 (n_samples,) 的类数组,默认为None
样本权重。
- 返回:
- score浮点数
self.predict(X)相对于y的\(R^2\)。
备注
从0.23版本开始,在回归器上调用
score时使用的\(R^2\)分数使用multioutput='uniform_average',以保持与r2_score的默认值一致。这会影响所有多输出回归器的score方法(MultiOutputRegressor除外)。
- set_fit_request(*, copy_X: bool | None | str = '$UNCHANGED$') LassoLarsIC[source]#
向
fit方法请求传递的元数据。请注意,只有在
enable_metadata_routing=True时,此方法才相关(参见sklearn.set_config)。请参阅用户指南了解路由机制的工作原理。每个参数的选项为
True:请求元数据,如果提供则传递给fit。如果未提供元数据,则忽略请求。False:不请求元数据,元估计器不会将其传递给fit。None:不请求元数据,如果用户提供元数据,则元估计器将引发错误。str:元数据应使用此给定的别名而不是原始名称传递给元估计器。
默认值(
sklearn.utils.metadata_routing.UNCHANGED)保留现有的请求。这允许您更改某些参数的请求而不会更改其他参数。版本1.3中添加。
注意
仅当将此估计器用作元估计器的子估计器(例如,在
Pipeline内部使用)时,此方法才相关。否则,它无效。- 参数:
- copy_Xstr, True, False, 或 None,默认值=sklearn.utils.metadata_routing.UNCHANGED
fit中copy_X参数的元数据路由。
- 返回:
- self对象
更新后的对象。
- set_params(**params)[source]#
设置此估计器的参数。
此方法适用于简单估计器以及嵌套对象(例如
Pipeline)。后者具有<component>__<parameter>形式的参数,因此可以更新嵌套对象的每个组件。- 参数:
- **paramsdict
估计器参数。
- 返回:
- self估计器实例
估计器实例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LassoLarsIC[source]#
向
score方法请求传递的元数据。请注意,只有在
enable_metadata_routing=True时,此方法才相关(参见sklearn.set_config)。请参阅用户指南了解路由机制的工作原理。每个参数的选项为
True:请求元数据,如果提供则传递给score。如果未提供元数据,则忽略请求。False:不请求元数据,元估计器不会将其传递给score。None:不请求元数据,如果用户提供元数据,则元估计器将引发错误。str:元数据应使用此给定的别名而不是原始名称传递给元估计器。
默认值(
sklearn.utils.metadata_routing.UNCHANGED)保留现有的请求。这允许您更改某些参数的请求而不会更改其他参数。版本1.3中添加。
注意
仅当将此估计器用作元估计器的子估计器(例如,在
Pipeline内部使用)时,此方法才相关。否则,它无效。- 参数:
- sample_weightstr, True, False, 或 None,默认值=sklearn.utils.metadata_routing.UNCHANGED
score中sample_weight参数的元数据路由。
- 返回:
- self对象
更新后的对象。