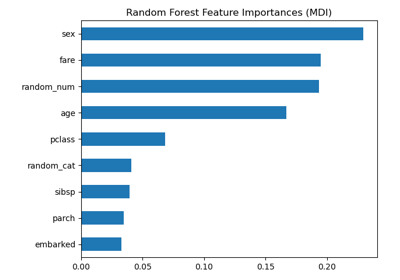
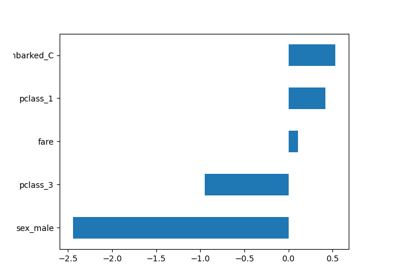
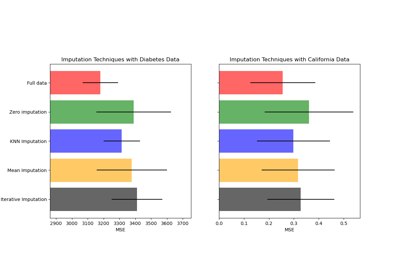
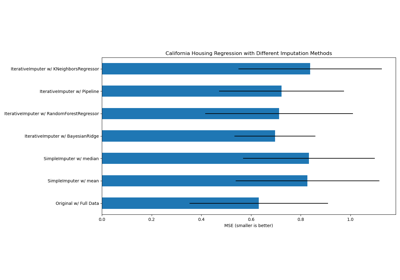
SimpleImputer 简单插补器#
- class sklearn.impute.SimpleImputer(*, missing_values=nan, strategy='mean', fill_value=None, copy=True, add_indicator=False, keep_empty_features=False)[source]#
用于使用简单策略完成缺失值的单变量估算器。
使用描述性统计量(例如,均值、中位数或最频繁值)沿每列替换缺失值,或使用常数值。
在用户指南中了解更多信息。
版本 0.20 中新增:
SimpleImputer替换了之前的sklearn.preprocessing.Imputer估算器,该估算器现已移除。- 参数:
- missing_valuesint、float、str、np.nan、None 或 pandas.NA,默认为 np.nan
缺失值的占位符。所有
missing_values的出现都将被估算。对于具有可空整数 dtype 和缺失值的 pandas 数据框,missing_values可以设置为np.nan或pd.NA。- strategystr 或 Callable,默认为 'mean'
估算策略。
如果为“mean”,则使用每列的均值替换缺失值。只能与数值数据一起使用。
如果为“median”,则使用每列的中位数替换缺失值。只能与数值数据一起使用。
如果为“most_frequent”,则使用每列中最频繁的值替换缺失值。可用于字符串或数值数据。如果存在多个这样的值,则只返回最小的值。
如果为“constant”,则使用 fill_value 替换缺失值。可用于字符串或数值数据。
如果为 Callable 实例,则使用通过对包含每列非缺失值的密集一维数组运行可调用对象返回的标量统计量来替换缺失值。
版本 0.20 中新增: strategy=”constant” 用于固定值估算。
版本 1.5 中新增: strategy=callable 用于自定义值估算。
- fill_valuestr 或数值,默认为 None
当 strategy == “constant” 时,
fill_value用于替换所有出现的 missing_values。对于字符串或对象数据类型,fill_value必须是字符串。如果为None,则在估算数值数据时fill_value将为 0,对于字符串或对象数据类型则为“missing_value”。- copybool,默认为 True
如果为 True,则将创建 X 的副本。如果为 False,则只要有可能,就会就地进行估算。请注意,在以下情况下,即使
copy=False,也会始终创建新副本:如果
X不是浮点值数组;如果
X编码为 CSR 矩阵;如果
add_indicator=True。
- add_indicatorbool,默认为 False
如果为 True,则
MissingIndicator变换将堆叠到估算器的变换输出上。这允许预测估算器即使在估算后也能解释缺失值。如果某个特征在拟合/训练时没有缺失值,即使在变换/测试时存在缺失值,该特征也不会出现在缺失指示器上。- keep_empty_featuresbool,默认为 False
如果为 True,则当调用
fit时,完全由缺失值组成的特征将在调用transform时返回结果中。估算值始终为0,除非strategy="constant",在这种情况下将使用fill_value。版本 1.2 中新增。
版本 1.6 中已更改: 当前,当
keep_empty_feature=False和strategy="constant"时,不会丢弃空特征。此行为将在版本 1.8 中更改。设置keep_empty_feature=True以保留此行为。
- 属性:
- statistics_形状为 (n_features,) 的数组
每个特征的估算填充值。计算统计量可能会导致
np.nan值。在transform期间,将丢弃与np.nan统计量对应的特征。- indicator_
MissingIndicator 用于添加缺失值二元指示器的指示器。如果
add_indicator=False,则为None。- n_features_in_int
在 fit 期间看到的特征数量。
版本 0.24 中新增。
- feature_names_in_形状为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时定义。1.0 版本新增。
另请参阅
IterativeImputer多变量填补器,根据所有其他特征的值来估计每个具有缺失值的特征的填补值。
KNNImputer使用最近邻样本估计缺失特征的多变量填补器。
备注
如果策略不是
"constant",则在fit时仅包含缺失值的列将在transform中被丢弃。在预测环境中,简单填补通常与弱学习器一起使用时效果不佳。但是,对于强大的学习器,它可以达到与复杂填补(例如
IterativeImputer或KNNImputer)一样好或更好的性能。示例
>>> import numpy as np >>> from sklearn.impute import SimpleImputer >>> imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean') >>> imp_mean.fit([[7, 2, 3], [4, np.nan, 6], [10, 5, 9]]) SimpleImputer() >>> X = [[np.nan, 2, 3], [4, np.nan, 6], [10, np.nan, 9]] >>> print(imp_mean.transform(X)) [[ 7. 2. 3. ] [ 4. 3.5 6. ] [10. 3.5 9. ]]
有关更详细的示例,请参阅 构建估计器之前填补缺失值。
- fit(X, y=None)[source]#
在
X上拟合填补器。- 参数:
- X{array-like, sparse matrix}, shape (n_samples, n_features)
输入数据,其中
n_samples是样本数,n_features是特征数。- y忽略
未使用,出于 API 一致性约定而在此处显示。
- 返回值:
- selfobject
拟合的估计器。
- fit_transform(X, y=None, **fit_params)[source]#
拟合数据,然后转换它。
使用可选参数
fit_params将转换器拟合到X和y,并返回X的转换版本。- 参数:
- Xarray-like of shape (n_samples, n_features)
输入样本。
- yarray-like of shape (n_samples,) or (n_samples, n_outputs), default=None
目标值(无监督转换则为 None)。
- **fit_paramsdict
附加拟合参数。
- 返回值:
- X_newndarray array of shape (n_samples, n_features_new)
转换后的数组。
- get_feature_names_out(input_features=None)[source]#
获取转换后的输出特征名称。
- 参数:
- input_featuresarray-like of str or None, default=None
输入特征。
如果
input_features为None,则使用feature_names_in_作为输入特征名称。如果feature_names_in_未定义,则生成以下输入特征名称:["x0", "x1", ..., "x(n_features_in_ - 1)"]。如果
input_features是一个类数组,则如果feature_names_in_已定义,则input_features必须与feature_names_in_匹配。
- 返回值:
- feature_names_outndarray of str objects
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看 用户指南,了解路由机制的工作原理。
- 返回值:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,则将返回此估计器和包含的作为估计器的子对象的的参数。
- 返回值:
- paramsdict
参数名称与其值的映射。
- inverse_transform(X)[source]#
将数据转换回原始表示。
反转对数组执行的
transform操作。只有在使用add_indicator=True实例化SimpleImputer之后才能执行此操作。请注意,
inverse_transform只能反转具有缺失值二元指示符的特征的转换。如果某个特征在fit时没有缺失值,则该特征将没有二元指示符,并且在transform时进行的插补将不会被反转。版本 0.24 中新增。
- 参数:
- X形状为 (n_samples, n_features + n_features_missing_indicator) 的类数组
要还原为原始数据的插补数据。它必须是插补数据和缺失指示符掩码的增强数组。
- 返回值:
- X_original形状为 (n_samples, n_features) 的ndarray
原始的
X,其中缺失值与插补前相同。
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用 API 的示例,请参阅Introducing the set_output API。
- 参数:
- transform{"default", "pandas", "polars"}, default=None
配置
transform和fit_transform的输出。"default":转换器的默认输出格式"pandas":DataFrame 输出"polars":Polars 输出None:转换配置保持不变
版本 1.4 中新增: 添加了
"polars"选项。
- 返回值:
- self估计器实例
估计器实例。