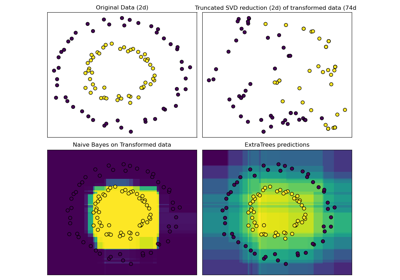
随机树嵌入#
- class sklearn.ensemble.RandomTreesEmbedding(n_estimators=100, *, max_depth=5, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_leaf_nodes=None, min_impurity_decrease=0.0, sparse_output=True, n_jobs=None, random_state=None, verbose=0, warm_start=False)[source]#
完全随机树的集成。
将数据集转换为高维稀疏表示的无监督转换。根据数据点被分到每棵树的哪个叶节点,对其进行编码。使用叶节点的独热编码,这将导致一个二进制编码,其中 1 的数量与森林中的树木数量相同。
结果表示的维数为
n_out <= n_estimators * max_leaf_nodes。如果max_leaf_nodes == None,则叶节点数最多为n_estimators * 2 ** max_depth。在 用户指南 中了解更多信息。
- 参数:
- n_estimatorsint,默认为 100
森林中树的数量。
0.22 版本中的变更:
n_estimators的默认值在 0.22 版本中从 10 更改为 100。- max_depthint,默认为 5
每棵树的最大深度。如果为 None,则节点会一直扩展,直到所有叶子节点都是纯净的,或者所有叶子节点包含的样本数少于 min_samples_split。
- min_samples_splitint 或 float,默认为 2
拆分内部节点所需的最小样本数。
如果为 int,则将
min_samples_split视为最小数量。如果为 float,则
min_samples_split是一个分数,而ceil(min_samples_split * n_samples)是每次拆分所需的最小样本数。
0.18 版本中的变更: 添加了表示分数的浮点值。
- min_samples_leafint 或 float,默认为 1
叶节点所需的最小样本数。只有当拆分点在任何深度上至少在左右分支中留下
min_samples_leaf个训练样本时,才会考虑该拆分点。这可能会使模型平滑,尤其是在回归中。如果为 int,则将
min_samples_leaf视为最小数量。如果为 float,则
min_samples_leaf是一个分数,而ceil(min_samples_leaf * n_samples)是每个节点所需的最小样本数。
0.18 版本中的变更: 添加了表示分数的浮点值。
- min_weight_fraction_leaffloat,默认为 0.0
叶节点所需的权重总和(所有输入样本的权重总和)的最小加权分数。如果未提供 sample_weight,则样本具有相同的权重。
- max_leaf_nodesint,默认为 None
以最佳优先的方式,使用
max_leaf_nodes增长树木。最佳节点定义为杂质的相对减少。如果为 None,则叶节点数量不限。- min_impurity_decreasefloat,默认为 0.0
如果此拆分导致杂质减少大于或等于此值,则将拆分节点。
加权杂质减少方程如下:
N_t / N * (impurity - N_t_R / N_t * right_impurity - N_t_L / N_t * left_impurity)
其中
N是样本总数,N_t是当前节点的样本数,N_t_L是左子节点的样本数,而N_t_R是右子节点的样本数。如果传递了
sample_weight,则N、N_t、N_t_R和N_t_L都指加权和。0.19 版本中添加。
- sparse_outputbool,默认为 True
是否返回稀疏 CSR 矩阵(作为默认行为),还是返回与密集管道运算符兼容的密集数组。
- n_jobsint,默认为 None
并行运行的作业数。
fit、transform、decision_path和apply都在树上并行化。除非在joblib.parallel_backend上下文中,None表示 1。-1表示使用所有处理器。更多详情,请参见 术语表。- random_stateint、RandomState 实例或 None,默认为 None
控制用于拟合树的随机
y的生成以及树节点上每个特征的分割抽取。详情请参见 术语表。- verboseint,默认为 0
控制拟合和预测时的详细程度。
- warm_startbool,默认为 False
设置为
True时,重用先前对 fit 的调用的解决方案,并将更多估计器添加到集成中;否则,只拟合一个全新的森林。详情请参见 术语表 和 拟合附加树。
- 属性:
- estimator_
ExtraTreeRegressor实例 用于创建拟合子估计器集合的子估计器模板。
1.2 版新增:
base_estimator_已重命名为estimator_。- estimators_
ExtraTreeRegressor实例列表 拟合的子估计器集合。
feature_importances_形状为 (n_features,) 的 ndarray基于杂质的特征重要性。
- n_features_in_int
在 拟合期间看到的特征数。
0.24 版新增。
- feature_names_in_形状为 (
n_features_in_,) 的 ndarray 在 拟合期间看到的特征名称。仅当
X的特征名称全部为字符串时才定义。1.0 版新增。
- n_outputs_int
执行
fit时的输出数。- one_hot_encoder_OneHotEncoder 实例
用于创建稀疏嵌入的独热编码器。
estimators_samples_数组列表每个基础估计器的抽取样本子集。
- estimator_
另请参见
ExtraTreesClassifier额外树分类器。
ExtraTreesRegressor额外树回归器。
RandomForestClassifier随机森林分类器。
RandomForestRegressor随机森林回归器。
sklearn.tree.ExtraTreeClassifier极端随机树分类器。
sklearn.tree.ExtraTreeRegressor极端随机树回归器。
参考文献
[1]P. Geurts, D. Ernst., and L. Wehenkel, “Extremely randomized trees”, Machine Learning, 63(1), 3-42, 2006。
[2]Moosmann, F. and Triggs, B. and Jurie, F. “Fast discriminative visual codebooks using randomized clustering forests” NIPS 2007
示例
>>> from sklearn.ensemble import RandomTreesEmbedding >>> X = [[0,0], [1,0], [0,1], [-1,0], [0,-1]] >>> random_trees = RandomTreesEmbedding( ... n_estimators=5, random_state=0, max_depth=1).fit(X) >>> X_sparse_embedding = random_trees.transform(X) >>> X_sparse_embedding.toarray() array([[0., 1., 1., 0., 1., 0., 0., 1., 1., 0.], [0., 1., 1., 0., 1., 0., 0., 1., 1., 0.], [0., 1., 0., 1., 0., 1., 0., 1., 0., 1.], [1., 0., 1., 0., 1., 0., 1., 0., 1., 0.], [0., 1., 1., 0., 1., 0., 0., 1., 1., 0.]])
- apply(X)[source]#
将森林中的树应用于 X,返回叶索引。
- 参数:
- X形状为 (n_samples, n_features) 的{类数组、稀疏矩阵}
输入样本。内部,其 dtype 将转换为
dtype=np.float32。如果提供稀疏矩阵,它将转换为稀疏csr_matrix。
- 返回:
- X_leaves形状为 (n_samples, n_estimators) 的 ndarray
对于 X 中的每个数据点 x 和森林中的每棵树,返回 x 最终所在的叶的索引。
- decision_path(X)[source]#
返回森林中的决策路径。
0.18 版新增。
- 参数:
- X形状为 (n_samples, n_features) 的{类数组、稀疏矩阵}
输入样本。内部,其 dtype 将转换为
dtype=np.float32。如果提供稀疏矩阵,它将转换为稀疏csr_matrix。
- 返回:
- indicator形状为 (n_samples, n_nodes) 的稀疏矩阵
返回一个节点指示矩阵,其中非零元素表示样本经过这些节点。该矩阵采用 CSR 格式。
- n_nodes_ptr形状为 (n_estimators + 1,) 的 ndarray
indicator[n_nodes_ptr[i]:n_nodes_ptr[i+1]] 中的列给出了第 i 个估计器的指示值。
- property estimators_samples_#
每个基础估计器的抽取样本子集。
返回一个动态生成的索引列表,用于识别用于拟合集成每个成员的样本,即袋内样本。
注意:为了减少对象内存占用而不存储采样数据,该列表在每次调用该属性时都会重新创建。因此,获取属性的速度可能比预期慢。
- property feature_importances_#
基于杂质的特征重要性。
值越高,特征越重要。特征的重要性计算为该特征带来的标准(归一化)总减少量。它也称为基尼重要性。
警告:对于高基数特征(许多唯一值),基于杂质的特征重要性可能会产生误导。请参见
sklearn.inspection.permutation_importance作为替代方法。- 返回:
- feature_importances_形状为 (n_features,) 的 ndarray
此数组的值之和为 1,除非所有树都是仅由根节点组成的单节点树,在这种情况下,它将是一个全零数组。
- fit(X, y=None, sample_weight=None)[source]#
拟合估计器。
- 参数:
- X形状为 (n_samples, n_features) 的{类数组、稀疏矩阵}
输入样本。为获得最大效率,请使用
dtype=np.float32。也支持稀疏矩阵,为获得最大效率,请使用稀疏csc_matrix。- y忽略
未使用,根据惯例保留以保持 API 一致性。
- sample_weight形状为 (n_samples,) 的类数组,默认值为 None
样本权重。如果为 None,则样本权重相等。在搜索每个节点的分割时,将忽略那些会创建净权重为零或负的子节点的分割。在分类情况下,如果分割会导致任何单个类别在任一子节点中具有负权重,则也会忽略该分割。
- 返回:
- self对象
返回实例本身。
- fit_transform(X, y=None, sample_weight=None)[source]#
拟合估计器并转换数据集。
- 参数:
- X形状为 (n_samples, n_features) 的{类数组、稀疏矩阵}
用于构建森林的输入数据。为获得最大效率,请使用
dtype=np.float32。- y忽略
未使用,根据惯例保留以保持 API 一致性。
- sample_weight形状为 (n_samples,) 的类数组,默认值为 None
样本权重。如果为 None,则样本权重相等。在搜索每个节点的分割时,将忽略那些会创建净权重为零或负的子节点的分割。在分类情况下,如果分割会导致任何单个类别在任一子节点中具有负权重,则也会忽略该分割。
- 返回:
- X_transformed形状为 (n_samples, n_out) 的稀疏矩阵
转换后的数据集。
- get_feature_names_out(input_features=None)[source]#
获取转换后的输出特征名称。
- 参数:
- input_featuresstr 数组或 None,默认为 None
仅用于使用在
fit中看到的名称验证特征名称。
- 返回:
- feature_names_outstr 对象的 ndarray
转换后的特征名称,格式为
randomtreesembedding_{tree}_{leaf},其中tree是用于生成叶节点的树,leaf是该树中叶节点的索引。请注意,节点索引方案用于索引具有子节点(分割节点)和叶节点的节点。只有后者才能作为输出特征出现。因此,输出特征名称中存在缺失索引。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看 用户指南,了解路由机制的工作原理。
- 返回:
- routingMetadataRequest
一个
MetadataRequest封装了路由信息。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deep布尔值,默认为 True
如果为 True,则将返回此估计器和包含的作为估计器的子对象的参数。
- 返回:
- params字典
参数名称与其值的映射。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') RandomTreesEmbedding[source]#
请求传递给
fit方法的元数据。请注意,只有在
enable_metadata_routing=True时(请参阅sklearn.set_config)此方法才相关。请参阅 用户指南,了解路由机制的工作原理。每个参数的选项为
True:请求元数据,如果提供则传递给fit。如果未提供元数据,则忽略请求。False:不请求元数据,元估计器不会将其传递给fit。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:元数据应使用此给定的别名而不是原始名称传递给元估计器。
默认值(
sklearn.utils.metadata_routing.UNCHANGED)保留现有请求。这允许您更改某些参数的请求,而其他参数则保持不变。版本 1.3 中新增。
注意
仅当此估计器用作元估计器的子估计器(例如,在
Pipeline中使用)时,此方法才相关。否则,它没有任何效果。- 参数:
- sample_weightstr、True、False 或 None,默认为 sklearn.utils.metadata_routing.UNCHANGED
fit中sample_weight参数的元数据路由。
- 返回:
- self对象
更新后的对象。
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用此 API 的示例,请参阅 Introducing the set_output API。
- 参数:
- transform{"default","pandas","polars"},默认为 None
配置
transform和fit_transform的输出。"default":转换器的默认输出格式"pandas":DataFrame 输出"polars":Polars 输出None:转换配置保持不变
版本 1.4 中新增:
"polars"选项已添加。
- 返回:
- self估计器实例
估计器实例。