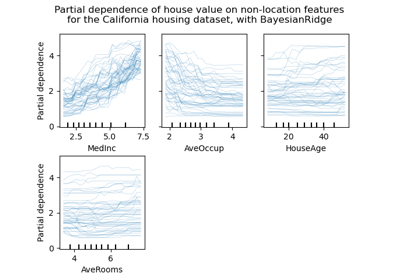
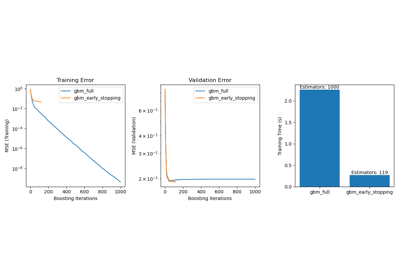
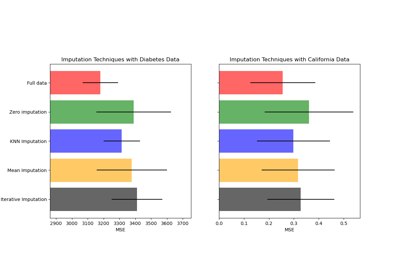
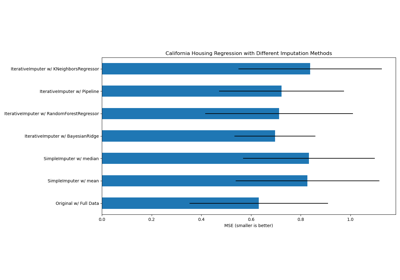
获取加州房价数据集#
- sklearn.datasets.fetch_california_housing(*, data_home=None, download_if_missing=True, return_X_y=False, as_frame=False, n_retries=3, delay=1.0)[source]#
加载加州房价数据集(回归)。
样本总数
20640
维度
8
特征
实数
目标值
实数 0.15 - 5.
更多信息请参见用户指南。
- 参数:
- data_homestr 或 path-like 对象,默认为 None
指定数据集的另一个下载和缓存文件夹。默认情况下,所有 scikit-learn 数据都存储在 ‘~/scikit_learn_data’ 子文件夹中。
- download_if_missingbool,默认为 True
如果为 False,则如果数据在本地不可用,则引发 OSError,而不是尝试从源站点下载数据。
- return_X_ybool,默认为 False
如果为 True,则返回
(data.data, data.target)而不是 Bunch 对象。版本 0.20 中新增。
- as_framebool,默认为 False
如果为 True,则数据是一个 pandas DataFrame,包含具有适当数据类型(数值型、字符串型或分类型)的列。目标值是一个 pandas DataFrame 或 Series,具体取决于 target_columns 的数量。
版本 0.23 中新增。
- n_retriesint,默认为 3
遇到 HTTP 错误时的重试次数。
版本 1.5 中新增。
- delayfloat,默认为 1.0
两次重试之间的秒数。
版本 1.5 中新增。
- 返回值:
- dataset
Bunch 字典状对象,具有以下属性。
- datandarray,形状 (20640, 8)
每一行对应于按顺序排列的 8 个特征值。如果
as_frame为 True,则data是一个 pandas 对象。- target形状为 (20640,) 的 numpy 数组
每个值对应于以 100,000 为单位的平均房价。如果
as_frame为 True,则target是一个 pandas 对象。- feature_names长度为 8 的列表
数据集使用的有序特征名称数组。
- DESCRstr
加州房价数据集的描述。
- framepandas DataFrame
仅当
as_frame=True时存在。包含data和target的 DataFrame。版本 0.23 中新增。
- (data, target)如果
return_X_y为 True,则为元组 包含两个 ndarray 的元组。第一个包含形状为 (n_samples, n_features) 的二维数组,其中每一行表示一个样本,每一列表示特征。第二个形状为 (n_samples,) 的 ndarray 包含目标样本。
版本 0.20 中新增。
- dataset
备注
此数据集包含 20,640 个样本和 9 个特征。
示例
>>> from sklearn.datasets import fetch_california_housing >>> housing = fetch_california_housing() >>> print(housing.data.shape, housing.target.shape) (20640, 8) (20640,) >>> print(housing.feature_names[0:6]) ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup']