注意
转到末尾 下载完整的示例代码。或者通过 JupyterLite 或 Binder 在您的浏览器中运行此示例。
scikit-learn 0.24 版本亮点#
我们高兴地宣布 scikit-learn 0.24 版本发布!添加了许多错误修复和改进,以及一些新的关键功能。我们在下面详细介绍了此版本的一些主要功能。有关所有更改的详尽列表,请参阅发行说明。
要安装最新版本(使用 pip)
pip install --upgrade scikit-learn
或使用 conda
conda install -c conda-forge scikit-learn
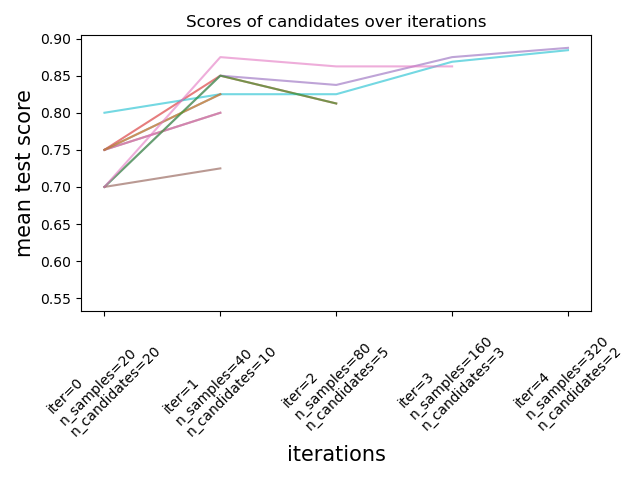
用于调整超参数的连续减半估计器#
连续减半是一种最先进的方法,现在可用于探索参数空间并识别其最佳组合。HalvingGridSearchCV 和 HalvingRandomSearchCV 可用作 GridSearchCV 和 RandomizedSearchCV 的直接替代。连续减半是一种迭代选择过程,如下图所示。第一次迭代使用少量资源运行,其中资源通常对应于训练样本的数量,但也可能是任意整数参数,例如随机森林中的n_estimators。只有一部分参数候选者被选中用于下一次迭代,下一次迭代将使用增加的资源量运行。只有一部分候选者将持续到迭代过程的结束,而最佳参数候选者是在最后一次迭代中得分最高的那个。
在用户指南中阅读更多内容(注意:连续减半估计器仍然是实验性的)。
import numpy as np
from scipy.stats import randint
from sklearn.experimental import enable_halving_search_cv # noqa
from sklearn.model_selection import HalvingRandomSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
rng = np.random.RandomState(0)
X, y = make_classification(n_samples=700, random_state=rng)
clf = RandomForestClassifier(n_estimators=10, random_state=rng)
param_dist = {
"max_depth": [3, None],
"max_features": randint(1, 11),
"min_samples_split": randint(2, 11),
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
}
rsh = HalvingRandomSearchCV(
estimator=clf, param_distributions=param_dist, factor=2, random_state=rng
)
rsh.fit(X, y)
rsh.best_params_
{'bootstrap': True, 'criterion': 'gini', 'max_depth': None, 'max_features': 10, 'min_samples_split': 10}
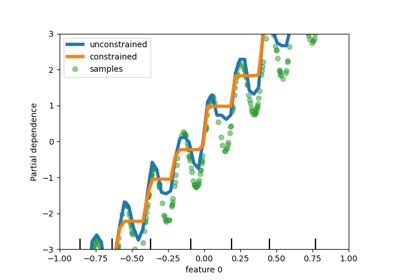
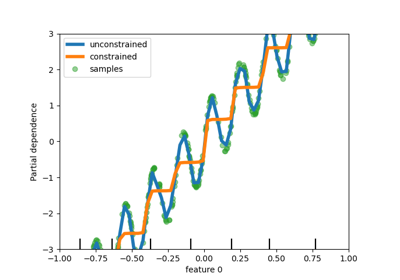
HistGradientBoosting 估计器对分类特征的原生支持#
HistGradientBoostingClassifier 和 HistGradientBoostingRegressor 现在对分类特征具有原生支持:它们可以考虑对无序分类数据的分割。在用户指南中阅读更多内容。
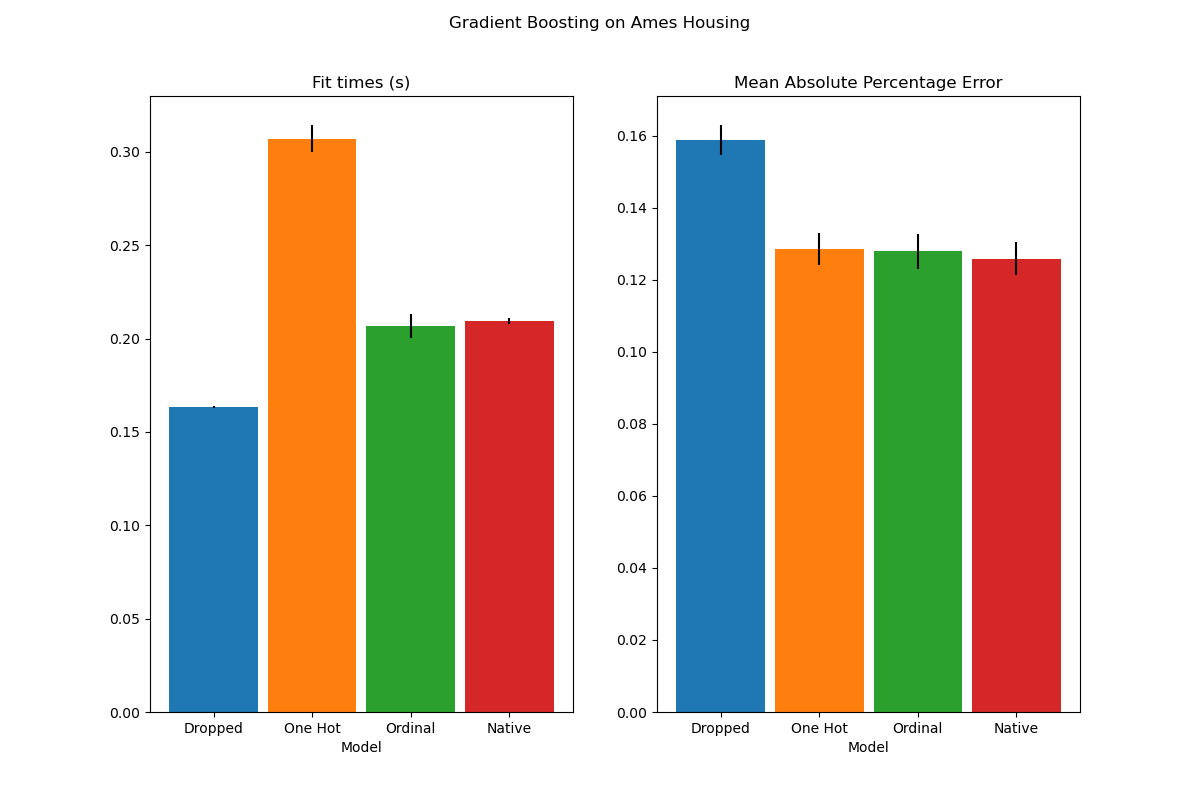
该图显示,对分类特征的新原生支持导致拟合时间与将类别视为有序数量(即简单地进行序数编码)的模型相当。原生支持也比独热编码和序数编码都更具表达力。但是,要使用新的categorical_features参数,仍然需要在这个示例中演示的管道内预处理数据。
HistGradientBoosting 估计器的性能改进#
ensemble.HistGradientBoostingRegressor 和 ensemble.HistGradientBoostingClassifier 在调用fit期间的内存占用量已大大减少。此外,直方图初始化现在并行进行,这导致速度略有提高。在基准测试页面中查看更多信息。
新的自训练元估计器#
基于Yarowski 算法的新自训练实现现在可以与任何实现predict_proba的分类器一起使用。子分类器将充当半监督分类器,允许它从未标记的数据中学习。在用户指南中阅读更多内容。
import numpy as np
from sklearn import datasets
from sklearn.semi_supervised import SelfTrainingClassifier
from sklearn.svm import SVC
rng = np.random.RandomState(42)
iris = datasets.load_iris()
random_unlabeled_points = rng.rand(iris.target.shape[0]) < 0.3
iris.target[random_unlabeled_points] = -1
svc = SVC(probability=True, gamma="auto")
self_training_model = SelfTrainingClassifier(svc)
self_training_model.fit(iris.data, iris.target)
新的 SequentialFeatureSelector 变换器#
现在可以使用一种新的迭代变换器来选择特征:SequentialFeatureSelector。顺序特征选择可以一次添加一个特征(前向选择)或从可用特征列表中删除特征(后向选择),基于交叉验证分数最大化。参见用户指南。
from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True, as_frame=True)
feature_names = X.columns
knn = KNeighborsClassifier(n_neighbors=3)
sfs = SequentialFeatureSelector(knn, n_features_to_select=2)
sfs.fit(X, y)
print(
"Features selected by forward sequential selection: "
f"{feature_names[sfs.get_support()].tolist()}"
)
Features selected by forward sequential selection: ['sepal length (cm)', 'petal width (cm)']
新的 PolynomialCountSketch 核近似函数#
新的PolynomialCountSketch 在与线性模型一起使用时,可以逼近特征空间的多项式展开,但比PolynomialFeatures 使用更少的内存。
from sklearn.datasets import fetch_covtype
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.kernel_approximation import PolynomialCountSketch
from sklearn.linear_model import LogisticRegression
X, y = fetch_covtype(return_X_y=True)
pipe = make_pipeline(
MinMaxScaler(),
PolynomialCountSketch(degree=2, n_components=300),
LogisticRegression(max_iter=1000),
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=5000, test_size=10000, random_state=42
)
pipe.fit(X_train, y_train).score(X_test, y_test)
0.7307
作为比较,以下是相同数据的线性基线得分。
linear_baseline = make_pipeline(MinMaxScaler(), LogisticRegression(max_iter=1000))
linear_baseline.fit(X_train, y_train).score(X_test, y_test)
0.714
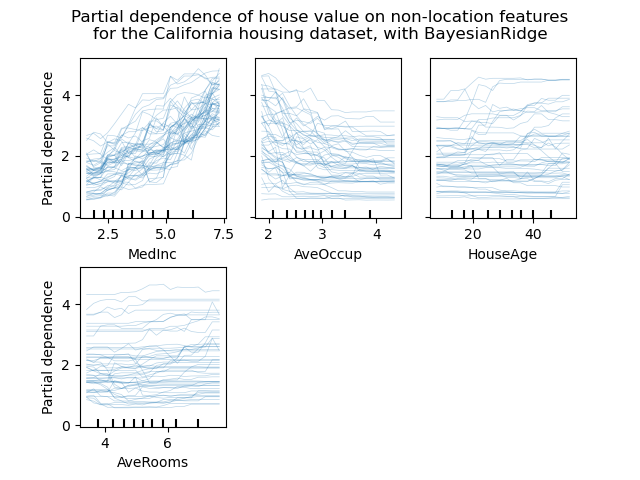
个体条件期望图#
一种新的偏依赖图可用:个体条件期望 (ICE) 图。ICE 图分别为每个样本可视化预测对特征的依赖性,每个样本一条线。参见用户指南
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import fetch_california_housing
# from sklearn.inspection import plot_partial_dependence
from sklearn.inspection import PartialDependenceDisplay
X, y = fetch_california_housing(return_X_y=True, as_frame=True)
features = ["MedInc", "AveOccup", "HouseAge", "AveRooms"]
est = RandomForestRegressor(n_estimators=10)
est.fit(X, y)
# plot_partial_dependence has been removed in version 1.2. From 1.2, use
# PartialDependenceDisplay instead.
# display = plot_partial_dependence(
display = PartialDependenceDisplay.from_estimator(
est,
X,
features,
kind="individual",
subsample=50,
n_jobs=3,
grid_resolution=20,
random_state=0,
)
display.figure_.suptitle(
"Partial dependence of house value on non-location features\n"
"for the California housing dataset, with BayesianRidge"
)
display.figure_.subplots_adjust(hspace=0.3)
DecisionTreeRegressor 的新泊松分裂准则#
泊松回归估计的集成从 0.23 版开始继续。 DecisionTreeRegressor 现在支持新的 'poisson' 分裂准则。如果您的目标是计数或频率,则设置 criterion="poisson" 可能是一个不错的选择。
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
import numpy as np
n_samples, n_features = 1000, 20
rng = np.random.RandomState(0)
X = rng.randn(n_samples, n_features)
# positive integer target correlated with X[:, 5] with many zeros:
y = rng.poisson(lam=np.exp(X[:, 5]) / 2)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=rng)
regressor = DecisionTreeRegressor(criterion="poisson", random_state=0)
regressor.fit(X_train, y_train)
新的文档改进#
为了不断提高对机器学习实践的理解,我们添加了新的示例和文档页面。
关于常见陷阱和推荐实践 的新章节。
一个说明如何统计比较模型性能(使用
GridSearchCV评估)的示例。关于如何解释线性模型的系数 的示例。
一个示例,比较主成分回归和偏最小二乘法。
脚本总运行时间:(0 分钟 13.709 秒)
相关示例