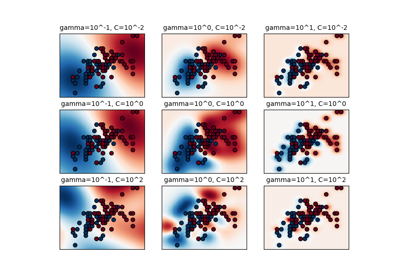
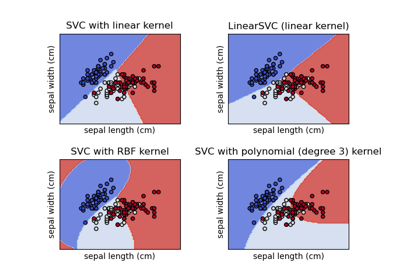
注意
转到结尾 下载完整的示例代码。或通过JupyterLite或Binder在您的浏览器中运行此示例。
使用不同的SVM核绘制分类边界#
此示例演示了SVC(支持向量分类器)中不同的核函数如何影响二元二维分类问题中的分类边界。
SVC的目标是找到一个超平面,通过最大化每个类别最外围数据点之间的边缘来有效地分离其训练数据中的类别。这是通过找到定义决策边界超平面的最佳权重向量\(w\)并最小化错误分类样本的铰链损失之和(由hinge_loss函数测量)来实现的。默认情况下,使用参数C=1应用正则化,这允许一定程度的错误分类容忍度。
如果数据在原始特征空间中不是线性可分的,则可以设置非线性核参数。根据核函数的不同,此过程涉及添加新特征或转换现有特征以丰富数据并可能为数据添加意义。当设置的核函数不是"linear"时,SVC会应用核技巧,该技巧使用核函数计算数据点对之间的相似性,而无需显式转换整个数据集。核技巧通过仅考虑所有数据点对之间的关系,超越了否则必要的整个数据集的矩阵变换。核函数使用两个向量的点积将两个向量(每对观测值)映射到它们的相似性。
然后可以使用核函数计算超平面,就好像数据集在更高维空间中表示一样。使用核函数而不是显式矩阵变换可以提高性能,因为核函数的时间复杂度为\(O({n}^2)\),而矩阵变换的缩放比例取决于所应用的特定变换。
在此示例中,我们比较支持向量机的最常用核类型:线性核函数("linear")、多项式核函数("poly")、径向基函数核函数("rbf")和sigmoid核函数("sigmoid")。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
创建数据集#
我们创建了一个包含16个样本和两个类别的二维分类数据集。我们用与它们各自目标匹配的颜色绘制样本。
import matplotlib.pyplot as plt
import numpy as np
X = np.array(
[
[0.4, -0.7],
[-1.5, -1.0],
[-1.4, -0.9],
[-1.3, -1.2],
[-1.1, -0.2],
[-1.2, -0.4],
[-0.5, 1.2],
[-1.5, 2.1],
[1.0, 1.0],
[1.3, 0.8],
[1.2, 0.5],
[0.2, -2.0],
[0.5, -2.4],
[0.2, -2.3],
[0.0, -2.7],
[1.3, 2.1],
]
)
y = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1])
# Plotting settings
fig, ax = plt.subplots(figsize=(4, 3))
x_min, x_max, y_min, y_max = -3, 3, -3, 3
ax.set(xlim=(x_min, x_max), ylim=(y_min, y_max))
# Plot samples by color and add legend
scatter = ax.scatter(X[:, 0], X[:, 1], s=150, c=y, label=y, edgecolors="k")
ax.legend(*scatter.legend_elements(), loc="upper right", title="Classes")
ax.set_title("Samples in two-dimensional feature space")
_ = plt.show()
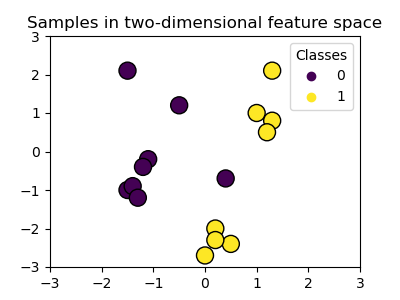
我们可以看到样本不能被直线清晰地分开。
训练SVC模型并绘制决策边界#
我们定义一个函数,该函数拟合一个SVC分类器,允许kernel参数作为输入,然后使用DecisionBoundaryDisplay绘制模型学习到的决策边界。
请注意,为了简单起见,在此示例中C参数设置为其默认值(C=1),并且所有核函数的gamma参数都设置为gamma=2,尽管线性核函数会自动忽略它。在实际的分类任务中,如果性能很重要,则强烈建议进行参数调整(例如,使用GridSearchCV),以捕捉数据中的不同结构。
在DecisionBoundaryDisplay中设置response_method="predict"会根据其预测类别为区域着色。使用response_method="decision_function"允许我们绘制决策边界及其两侧的边缘。最后,训练期间使用的支持向量(始终位于边缘上)通过训练好的SVC的support_vectors_属性识别,并绘制出来。
from sklearn import svm
from sklearn.inspection import DecisionBoundaryDisplay
def plot_training_data_with_decision_boundary(
kernel, ax=None, long_title=True, support_vectors=True
):
# Train the SVC
clf = svm.SVC(kernel=kernel, gamma=2).fit(X, y)
# Settings for plotting
if ax is None:
_, ax = plt.subplots(figsize=(4, 3))
x_min, x_max, y_min, y_max = -3, 3, -3, 3
ax.set(xlim=(x_min, x_max), ylim=(y_min, y_max))
# Plot decision boundary and margins
common_params = {"estimator": clf, "X": X, "ax": ax}
DecisionBoundaryDisplay.from_estimator(
**common_params,
response_method="predict",
plot_method="pcolormesh",
alpha=0.3,
)
DecisionBoundaryDisplay.from_estimator(
**common_params,
response_method="decision_function",
plot_method="contour",
levels=[-1, 0, 1],
colors=["k", "k", "k"],
linestyles=["--", "-", "--"],
)
if support_vectors:
# Plot bigger circles around samples that serve as support vectors
ax.scatter(
clf.support_vectors_[:, 0],
clf.support_vectors_[:, 1],
s=150,
facecolors="none",
edgecolors="k",
)
# Plot samples by color and add legend
ax.scatter(X[:, 0], X[:, 1], c=y, s=30, edgecolors="k")
ax.legend(*scatter.legend_elements(), loc="upper right", title="Classes")
if long_title:
ax.set_title(f" Decision boundaries of {kernel} kernel in SVC")
else:
ax.set_title(kernel)
if ax is None:
plt.show()
线性核#
线性核是输入样本的点积
然后将其应用于数据集中的任意两个数据点(样本)的组合。两点的点积决定了这两点之间的cosine_similarity。值越高,点越相似。
plot_training_data_with_decision_boundary("linear")
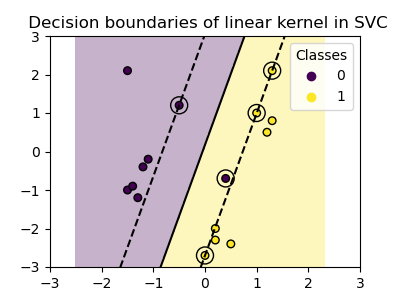
在线性核上训练SVC会产生一个未转换的特征空间,其中超平面和边缘是直线。由于线性核的表达能力不足,训练好的类别并没有完美地捕捉训练数据。
多项式核#
多项式核改变了相似性的概念。核函数定义为
其中,\({d}\) 表示多项式的阶数(degree),\({\gamma}\)(gamma)控制每个训练样本对决策边界的的影响,\({r}\) 是偏置项(coef0),用于向上或向下移动数据。这里,我们使用核函数中多项式阶数的默认值(degree=3)。当coef0=0(默认值)时,数据只会被转换,不会添加额外的维度。使用多项式核等效于创建PolynomialFeatures,然后用线性核在转换后的数据上拟合一个SVC,尽管对于大多数数据集来说,这种替代方法计算成本很高。
plot_training_data_with_decision_boundary("poly")
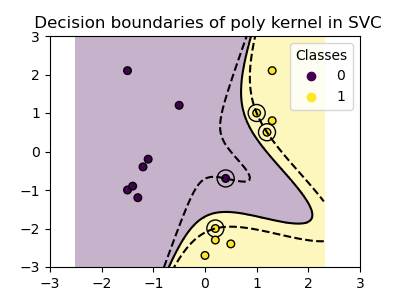
具有gamma=2`的多项式核能够很好地适应训练数据,导致超平面两侧的边界相应弯曲。
RBF 核#
径向基函数 (RBF) 核,也称为高斯核,是 scikit-learn 中支持向量机的默认核。它测量无限维空间中两个数据点之间的相似性,然后通过多数投票法进行分类。核函数定义为
其中,\({\gamma}\)(gamma)控制每个训练样本对决策边界的的影响。
两个点之间的欧几里得距离\(\|\mathbf{x}_1 - \mathbf{x}_2\|^2\) 越大,核函数越接近于零。这意味着距离较远的两个点越可能不相似。
plot_training_data_with_decision_boundary("rbf")
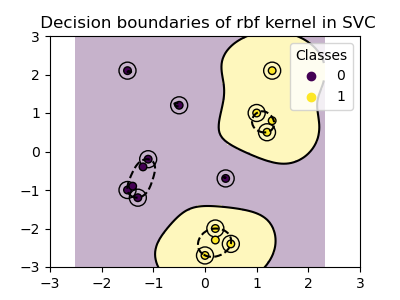
在图中,我们可以看到决策边界如何倾向于收缩到彼此靠近的数据点周围。
Sigmoid 核#
Sigmoid 核函数定义为
其中,核系数\({\gamma}\)(gamma)控制每个训练样本对决策边界的的影响,\({r}\) 是偏置项(coef0),用于向上或向下移动数据。
在 Sigmoid 核中,两个数据点之间的相似性使用双曲正切函数 (\(\tanh\)) 计算。核函数缩放并可能移动两个点 (\(\mathbf{x}_1\) 和 \(\mathbf{x}_2\)) 的点积。
plot_training_data_with_decision_boundary("sigmoid")
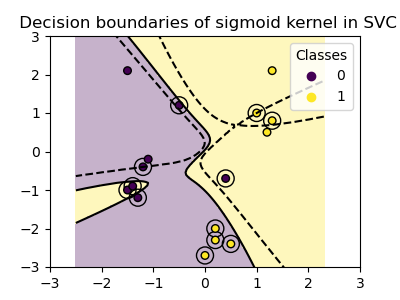
我们可以看到,使用 Sigmoid 核获得的决策边界看起来是弯曲且不规则的。决策边界试图通过拟合 S 形曲线来分离类别,从而产生一个复杂的边界,可能无法很好地泛化到未见的数据。从这个例子中可以看出,Sigmoid 核在处理具有 S 形形状的数据时具有非常具体的用例。在这个例子中,仔细的微调可能会找到更易于泛化的决策边界。由于其特殊性,Sigmoid 核在实践中比其他核更少使用。
结论#
在这个例子中,我们可视化了使用提供的训练数据集训练的决策边界。这些图直观地演示了不同的核如何利用训练数据来确定分类边界。
超平面和边界虽然是间接计算的,但可以想象成变换特征空间中的平面。然而,在图中,它们相对于原始特征空间表示,导致多项式、RBF 和 Sigmoid 核的决策边界弯曲。
请注意,这些图没有评估各个核的准确性或质量。它们的目的是提供对不同核如何使用训练数据的直观理解。
为了进行全面的评估,建议使用诸如GridSearchCV 等技术对SVC 参数进行微调,以捕捉数据中的潜在结构。
XOR 数据集#
一个经典的线性不可分数据集的例子是 XOR 模式。这里我们演示了不同的核在这种数据集上的工作方式。
xx, yy = np.meshgrid(np.linspace(-3, 3, 500), np.linspace(-3, 3, 500))
np.random.seed(0)
X = np.random.randn(300, 2)
y = np.logical_xor(X[:, 0] > 0, X[:, 1] > 0)
_, ax = plt.subplots(2, 2, figsize=(8, 8))
args = dict(long_title=False, support_vectors=False)
plot_training_data_with_decision_boundary("linear", ax[0, 0], **args)
plot_training_data_with_decision_boundary("poly", ax[0, 1], **args)
plot_training_data_with_decision_boundary("rbf", ax[1, 0], **args)
plot_training_data_with_decision_boundary("sigmoid", ax[1, 1], **args)
plt.show()
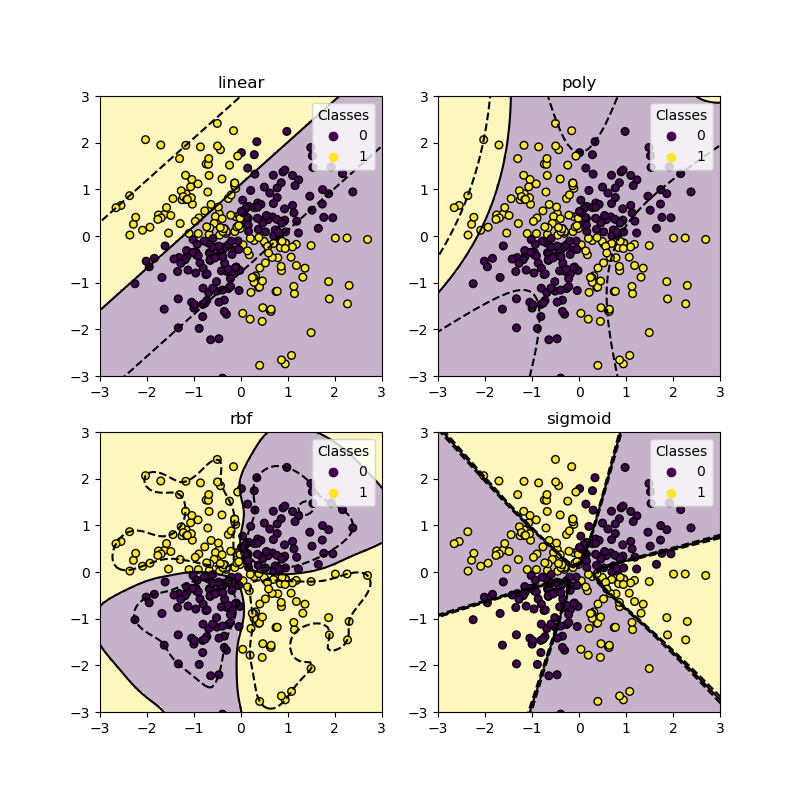
从上面的图中可以看出,只有rbf核才能为上述数据集找到合理的决策边界。
脚本总运行时间:(0 分钟 1.378 秒)
相关示例