注意
转到末尾 下载完整的示例代码。或通过JupyterLite或Binder在浏览器中运行此示例
scikit-learn 1.3 的发行亮点#
我们很高兴地宣布 scikit-learn 1.3 的发布!添加了许多错误修复和改进,以及一些新的关键功能。我们将在下面详细介绍此版本的一些主要功能。**有关所有更改的详尽列表**,请参阅发行说明。
要安装最新版本(使用pip)
pip install --upgrade scikit-learn
或使用 conda
conda install -c conda-forge scikit-learn
元数据路由#
我们正在引入一种新的元数据路由方式,例如sample_weight,这将影响元估计器(例如pipeline.Pipeline和model_selection.GridSearchCV)如何路由元数据。虽然此版本的代码库中已包含此功能的基础架构,但工作仍在进行中,并非所有元估计器都支持此新功能。您可以在元数据路由用户指南中阅读有关此功能的更多信息。请注意,此功能仍在开发中,并且尚未在大多数元估计器中实现。
第三方开发者现在就可以开始将其整合到他们的元估计器中。更多详情,请参见元数据路由开发者指南。
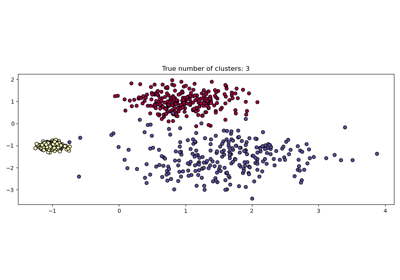
HDBSCAN:基于层次密度聚类#
最初托管在 scikit-learn-contrib 仓库中,cluster.HDBSCAN已被吸纳到 scikit-learn 中。它缺少原始实现中的一些功能,这些功能将在未来的版本中添加。通过对多个 epsilon 值同时执行 cluster.DBSCAN 的修改版本,cluster.HDBSCAN 能够找到不同密度的集群,使其比 cluster.DBSCAN 更能适应参数选择。更多详情请参见用户指南。
import numpy as np
from sklearn.cluster import HDBSCAN
from sklearn.datasets import load_digits
from sklearn.metrics import v_measure_score
X, true_labels = load_digits(return_X_y=True)
print(f"number of digits: {len(np.unique(true_labels))}")
hdbscan = HDBSCAN(min_cluster_size=15).fit(X)
non_noisy_labels = hdbscan.labels_[hdbscan.labels_ != -1]
print(f"number of clusters found: {len(np.unique(non_noisy_labels))}")
print(v_measure_score(true_labels[hdbscan.labels_ != -1], non_noisy_labels))
number of digits: 10
number of clusters found: 11
0.9694898472080092
TargetEncoder:一种新的类别编码策略#
preprocessing.TargetEncoder 非常适合高基数的分类特征,它基于对属于该类别的观测目标值的收缩估计来编码类别。更多详情请参见用户指南。
import numpy as np
from sklearn.preprocessing import TargetEncoder
X = np.array([["cat"] * 30 + ["dog"] * 20 + ["snake"] * 38], dtype=object).T
y = [90.3] * 30 + [20.4] * 20 + [21.2] * 38
enc = TargetEncoder(random_state=0)
X_trans = enc.fit_transform(X, y)
enc.encodings_
[array([90.3, 20.4, 21.2])]
决策树中的缺失值支持#
tree.DecisionTreeClassifier 和 tree.DecisionTreeRegressor 类现在支持缺失值。对于非缺失数据的每个潜在阈值,分割器将评估所有缺失值都进入左节点或右节点的分割。更多详情请参见用户指南,或参见直方图梯度提升树中的功能,了解此功能在HistGradientBoostingRegressor中的用例示例。
import numpy as np
from sklearn.tree import DecisionTreeClassifier
X = np.array([0, 1, 6, np.nan]).reshape(-1, 1)
y = [0, 0, 1, 1]
tree = DecisionTreeClassifier(random_state=0).fit(X, y)
tree.predict(X)
array([0, 0, 1, 1])
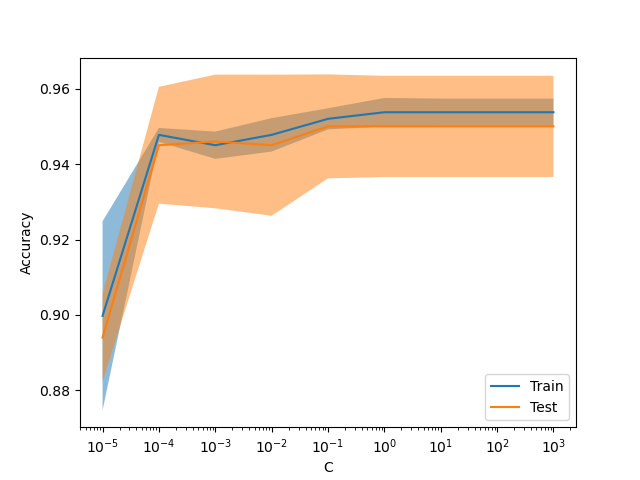
新的显示 ValidationCurveDisplay#
model_selection.ValidationCurveDisplay 现在可用于绘制 model_selection.validation_curve 的结果。
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import ValidationCurveDisplay
X, y = make_classification(1000, 10, random_state=0)
_ = ValidationCurveDisplay.from_estimator(
LogisticRegression(),
X,
y,
param_name="C",
param_range=np.geomspace(1e-5, 1e3, num=9),
score_type="both",
score_name="Accuracy",
)
梯度提升的 Gamma 损失#
ensemble.HistGradientBoostingRegressor 类通过 loss="gamma" 支持 Gamma 偏差损失函数。此损失函数可用于对具有右偏分布的严格正目标进行建模。
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_low_rank_matrix
from sklearn.ensemble import HistGradientBoostingRegressor
n_samples, n_features = 500, 10
rng = np.random.RandomState(0)
X = make_low_rank_matrix(n_samples, n_features, random_state=rng)
coef = rng.uniform(low=-10, high=20, size=n_features)
y = rng.gamma(shape=2, scale=np.exp(X @ coef) / 2)
gbdt = HistGradientBoostingRegressor(loss="gamma")
cross_val_score(gbdt, X, y).mean()
np.float64(0.46858513287221654)
在 OrdinalEncoder 中分组不常出现的类别#
与 preprocessing.OneHotEncoder 类似,preprocessing.OrdinalEncoder 类现在支持将不常出现的类别聚合到每个特征的单个输出中。启用收集不常出现类别的参数是 min_frequency 和 max_categories。更多详情请参见用户指南。
from sklearn.preprocessing import OrdinalEncoder
import numpy as np
X = np.array(
[["dog"] * 5 + ["cat"] * 20 + ["rabbit"] * 10 + ["snake"] * 3], dtype=object
).T
enc = OrdinalEncoder(min_frequency=6).fit(X)
enc.infrequent_categories_
[array(['dog', 'snake'], dtype=object)]
脚本总运行时间:(0 分钟 1.544 秒)
相关示例