注意
转到结尾 下载完整的示例代码。或者通过JupyterLite或Binder在浏览器中运行此示例
多类别AdaBoosted决策树#
此示例演示了Boosting如何提高多标签分类问题的预测准确性。它重现了Zhu等人[1]图1中描述的类似实验。
AdaBoost(自适应Boosting)的核心原理是对数据的重复重采样版本拟合一系列弱学习器(例如决策树)。每个样本都带有权重,该权重在每个训练步骤后都会进行调整,以便对错误分类的样本分配更高的权重。带替换的重采样过程考虑了分配给每个样本的权重。权重较高的样本在新数据集中被多次选择的可能性更大,而权重较低的样本被选择的可能性较小。这确保了算法的后续迭代重点关注难以分类的样本。
参考文献
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
创建数据集#
分类数据集是通过采用十维标准正态分布(\(x\) 在 \(R^{10}\) 中)并定义三个由嵌套同心十维球体分隔的类别来构建的,使得每个类别中的样本数量大致相等(\(\chi^2\) 分布的分位数)。
from sklearn.datasets import make_gaussian_quantiles
X, y = make_gaussian_quantiles(
n_samples=2_000, n_features=10, n_classes=3, random_state=1
)
我们将数据集分成两组:70%的样本用于训练,其余30%用于测试。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=0.7, random_state=42
)
训练AdaBoostClassifier#
我们训练了AdaBoostClassifier。该估计器利用Boosting来提高分类精度。Boosting是一种旨在训练弱学习器(即estimator)的方法,这些弱学习器从其前辈的错误中学习。
在这里,我们将弱学习器定义为DecisionTreeClassifier并将最大叶子数设置为8。在实际设置中,应调整此参数。我们将其设置为较低的值以限制示例的运行时间。
内置于AdaBoostClassifier中的SAMME算法然后使用当前弱学习器做出的正确或不正确的预测来更新用于训练后续弱学习器的样本权重。此外,弱学习器的权重是根据其在对训练样本进行分类中的准确性来计算的。弱学习器的权重决定了其对最终集成预测的影响。
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
weak_learner = DecisionTreeClassifier(max_leaf_nodes=8)
n_estimators = 300
adaboost_clf = AdaBoostClassifier(
estimator=weak_learner,
n_estimators=n_estimators,
random_state=42,
).fit(X_train, y_train)
分析#
AdaBoostClassifier的收敛性#
为了证明Boosting在提高准确性方面的有效性,我们将增强树的误分类误差与两个基线分数进行比较。第一个基线分数是从单个弱学习器(即DecisionTreeClassifier)获得的misclassification_error,作为参考点。第二个基线分数是从DummyClassifier获得的,它预测数据集中最普遍的类别。
from sklearn.dummy import DummyClassifier
from sklearn.metrics import accuracy_score
dummy_clf = DummyClassifier()
def misclassification_error(y_true, y_pred):
return 1 - accuracy_score(y_true, y_pred)
weak_learners_misclassification_error = misclassification_error(
y_test, weak_learner.fit(X_train, y_train).predict(X_test)
)
dummy_classifiers_misclassification_error = misclassification_error(
y_test, dummy_clf.fit(X_train, y_train).predict(X_test)
)
print(
"DecisionTreeClassifier's misclassification_error: "
f"{weak_learners_misclassification_error:.3f}"
)
print(
"DummyClassifier's misclassification_error: "
f"{dummy_classifiers_misclassification_error:.3f}"
)
DecisionTreeClassifier's misclassification_error: 0.475
DummyClassifier's misclassification_error: 0.692
训练DecisionTreeClassifier模型后,所达到的误差超过了通过猜测最频繁的类标签所能获得的预期值,正如DummyClassifier所做的那样。
现在,我们计算加性模型(DecisionTreeClassifier)在测试集上每次Boosting迭代的misclassification_error,即1 - accuracy,以评估其性能。
我们使用staged_predict,它进行的迭代次数与拟合估计器的数量一样多(即对应于n_estimators)。在迭代n时,AdaBoost的预测仅使用前n个弱学习器。我们将这些预测与真实预测y_test进行比较,因此,我们得出关于将新的弱学习器添加到链中是否有益(或无益)的结论。
我们绘制不同阶段的误分类误差。
import matplotlib.pyplot as plt
import pandas as pd
boosting_errors = pd.DataFrame(
{
"Number of trees": range(1, n_estimators + 1),
"AdaBoost": [
misclassification_error(y_test, y_pred)
for y_pred in adaboost_clf.staged_predict(X_test)
],
}
).set_index("Number of trees")
ax = boosting_errors.plot()
ax.set_ylabel("Misclassification error on test set")
ax.set_title("Convergence of AdaBoost algorithm")
plt.plot(
[boosting_errors.index.min(), boosting_errors.index.max()],
[weak_learners_misclassification_error, weak_learners_misclassification_error],
color="tab:orange",
linestyle="dashed",
)
plt.plot(
[boosting_errors.index.min(), boosting_errors.index.max()],
[
dummy_classifiers_misclassification_error,
dummy_classifiers_misclassification_error,
],
color="c",
linestyle="dotted",
)
plt.legend(["AdaBoost", "DecisionTreeClassifier", "DummyClassifier"], loc=1)
plt.show()
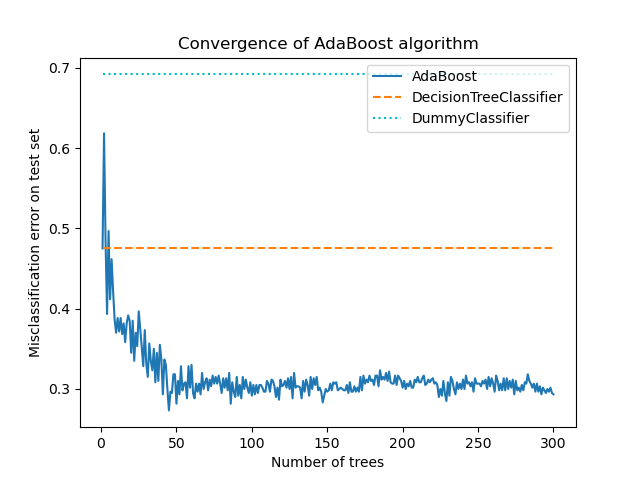
该图显示了每次Boosting迭代后测试集上的误分类误差。我们看到,增强树的误差在50次迭代后收敛到大约0.3的误差,这表明与单个树相比,准确性显著提高,如图中虚线所示。
由于SAMME算法使用弱学习器的离散输出训练提升模型,因此误分类错误会发生抖动。
AdaBoostClassifier的收敛主要受学习率(即learning_rate)、使用的弱学习器数量(n_estimators)以及弱学习器的表达能力(例如max_leaf_nodes)的影响。
弱学习器的错误和权重#
如前所述,AdaBoost是一种前向逐步加性模型。现在我们重点关注弱学习器的赋权与其统计性能之间的关系。
我们使用拟合的AdaBoostClassifier的属性estimator_errors_和estimator_weights_来研究这种联系。
weak_learners_info = pd.DataFrame(
{
"Number of trees": range(1, n_estimators + 1),
"Errors": adaboost_clf.estimator_errors_,
"Weights": adaboost_clf.estimator_weights_,
}
).set_index("Number of trees")
axs = weak_learners_info.plot(
subplots=True, layout=(1, 2), figsize=(10, 4), legend=False, color="tab:blue"
)
axs[0, 0].set_ylabel("Train error")
axs[0, 0].set_title("Weak learner's training error")
axs[0, 1].set_ylabel("Weight")
axs[0, 1].set_title("Weak learner's weight")
fig = axs[0, 0].get_figure()
fig.suptitle("Weak learner's errors and weights for the AdaBoostClassifier")
fig.tight_layout()
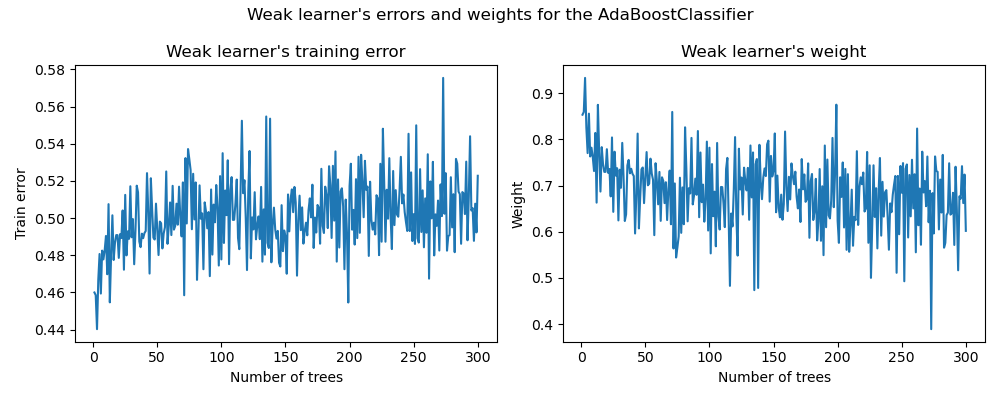
左图显示了在每次提升迭代中每个弱学习器在重新加权的训练集上的加权错误。右图显示了与每个弱学习器相关的权重,这些权重随后用于进行最终加性模型的预测。
我们可以看到,弱学习器的错误是权重的倒数。这意味着我们的加性模型会通过增加其对最终决策的影响来更多地信任犯错较少的弱学习器(在训练集上)。事实上,这正是 AdaBoost 中每次迭代后更新基估计器权重的公式。
数学细节#
与在阶段\(m\)训练的弱学习器相关的权重与其误分类错误成反比,因此
其中\(\alpha^{(m)}\)和\(err^{(m)}\)分别是第\(m\)个弱学习器的权重和错误,\(K\)是分类问题中的类别数。
另一个有趣的观察结果归结于模型的第一个弱学习器比提升链中后来的弱学习器犯的错误更少。
这种观察背后的直觉如下:由于样本重新加权,后来的分类器被迫尝试对更困难或更嘈杂的样本进行分类,并忽略已经很好分类的样本。因此,训练集上的整体误差将会增加。这就是为什么弱学习器的权重被构建为抵消性能较差的弱学习器。
脚本总运行时间:(0 分钟 5.002 秒)
相关示例