注意
访问结尾 下载完整的示例代码。或者通过 JupyterLite 或 Binder 在您的浏览器中运行此示例。
梯度提升中的分类特征支持#
本例将比较不同类别特征编码策略下HistGradientBoostingRegressor的训练时间和预测性能。我们将评估以下几种策略:
丢弃类别特征
使用
OneHotEncoder进行独热编码使用
OrdinalEncoder,将类别视为有序的、等距的量
我们将使用Ames Iowa Housing数据集,该数据集包含数值和类别特征,目标是房屋销售价格。
参见直方图梯度提升树中的特征,了解HistGradientBoostingRegressor的其他一些特征。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
加载Ames Housing数据集#
首先,我们将Ames Housing数据作为pandas DataFrame加载。特征既可以是分类的,也可以是数值的。
from sklearn.datasets import fetch_openml
X, y = fetch_openml(data_id=42165, as_frame=True, return_X_y=True)
# Select only a subset of features of X to make the example faster to run
categorical_columns_subset = [
"BldgType",
"GarageFinish",
"LotConfig",
"Functional",
"MasVnrType",
"HouseStyle",
"FireplaceQu",
"ExterCond",
"ExterQual",
"PoolQC",
]
numerical_columns_subset = [
"3SsnPorch",
"Fireplaces",
"BsmtHalfBath",
"HalfBath",
"GarageCars",
"TotRmsAbvGrd",
"BsmtFinSF1",
"BsmtFinSF2",
"GrLivArea",
"ScreenPorch",
]
X = X[categorical_columns_subset + numerical_columns_subset]
X[categorical_columns_subset] = X[categorical_columns_subset].astype("category")
categorical_columns = X.select_dtypes(include="category").columns
n_categorical_features = len(categorical_columns)
n_numerical_features = X.select_dtypes(include="number").shape[1]
print(f"Number of samples: {X.shape[0]}")
print(f"Number of features: {X.shape[1]}")
print(f"Number of categorical features: {n_categorical_features}")
print(f"Number of numerical features: {n_numerical_features}")
Number of samples: 1460
Number of features: 20
Number of categorical features: 10
Number of numerical features: 10
丢弃类别特征的梯度提升估算器#
作为基线,我们创建一个丢弃类别特征的估算器。
from sklearn.compose import make_column_selector, make_column_transformer
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.pipeline import make_pipeline
dropper = make_column_transformer(
("drop", make_column_selector(dtype_include="category")), remainder="passthrough"
)
hist_dropped = make_pipeline(dropper, HistGradientBoostingRegressor(random_state=42))
使用独热编码的梯度提升估算器#
接下来,我们创建一个管道,对类别特征进行独热编码,并将其余数值数据直接传递。
from sklearn.preprocessing import OneHotEncoder
one_hot_encoder = make_column_transformer(
(
OneHotEncoder(sparse_output=False, handle_unknown="ignore"),
make_column_selector(dtype_include="category"),
),
remainder="passthrough",
)
hist_one_hot = make_pipeline(
one_hot_encoder, HistGradientBoostingRegressor(random_state=42)
)
使用序数编码的梯度提升估算器#
接下来,我们创建一个管道,将类别特征视为有序量,即类别将编码为0、1、2等,并视为连续特征。
import numpy as np
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = make_column_transformer(
(
OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=np.nan),
make_column_selector(dtype_include="category"),
),
remainder="passthrough",
# Use short feature names to make it easier to specify the categorical
# variables in the HistGradientBoostingRegressor in the next step
# of the pipeline.
verbose_feature_names_out=False,
)
hist_ordinal = make_pipeline(
ordinal_encoder, HistGradientBoostingRegressor(random_state=42)
)
使用原生类别支持的梯度提升估算器#
现在,我们创建一个HistGradientBoostingRegressor估算器,它将原生处理类别特征。此估算器不会将类别特征视为有序量。我们将categorical_features="from_dtype"设置为使具有类别dtype的特征被视为类别特征。
此估算器与前一个估算器的主要区别在于,在此估算器中,我们让HistGradientBoostingRegressor根据DataFrame列的dtypes检测哪些特征是类别特征。
hist_native = HistGradientBoostingRegressor(
random_state=42, categorical_features="from_dtype"
)
模型比较#
最后,我们使用交叉验证评估模型。在这里,我们比较模型在mean_absolute_percentage_error和拟合时间方面的性能。
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_validate
scoring = "neg_mean_absolute_percentage_error"
n_cv_folds = 3
dropped_result = cross_validate(hist_dropped, X, y, cv=n_cv_folds, scoring=scoring)
one_hot_result = cross_validate(hist_one_hot, X, y, cv=n_cv_folds, scoring=scoring)
ordinal_result = cross_validate(hist_ordinal, X, y, cv=n_cv_folds, scoring=scoring)
native_result = cross_validate(hist_native, X, y, cv=n_cv_folds, scoring=scoring)
def plot_results(figure_title):
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 8))
plot_info = [
("fit_time", "Fit times (s)", ax1, None),
("test_score", "Mean Absolute Percentage Error", ax2, None),
]
x, width = np.arange(4), 0.9
for key, title, ax, y_limit in plot_info:
items = [
dropped_result[key],
one_hot_result[key],
ordinal_result[key],
native_result[key],
]
mape_cv_mean = [np.mean(np.abs(item)) for item in items]
mape_cv_std = [np.std(item) for item in items]
ax.bar(
x=x,
height=mape_cv_mean,
width=width,
yerr=mape_cv_std,
color=["C0", "C1", "C2", "C3"],
)
ax.set(
xlabel="Model",
title=title,
xticks=x,
xticklabels=["Dropped", "One Hot", "Ordinal", "Native"],
ylim=y_limit,
)
fig.suptitle(figure_title)
plot_results("Gradient Boosting on Ames Housing")
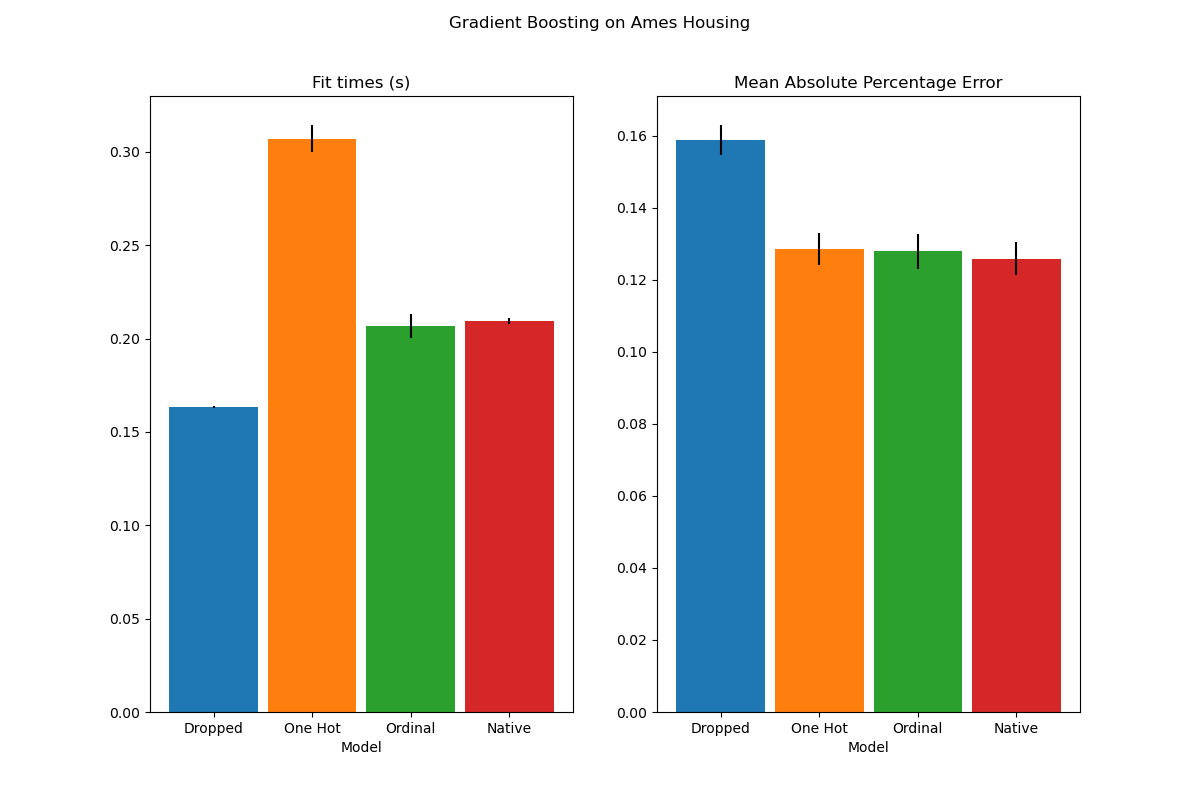
我们可以看到,使用独热编码数据的模型慢得多。这是可以预料的,因为独热编码为每个类别值(每个类别特征)创建了一个附加特征,因此在拟合过程中需要考虑更多的分割点。理论上,我们预计原生处理类别特征的速度会略慢于将类别视为有序量('Ordinal'),因为原生处理需要对类别进行排序。但是,当类别数量较少时,拟合时间应该接近,这在实践中并不总是能体现出来。
在预测性能方面,丢弃类别特征会导致性能下降。使用类别特征的三个模型具有相当的误差率,原生处理略有优势。
限制分割数量#
通常,可以预期从独热编码数据中获得较差的预测结果,尤其是在限制树的深度或节点数量时:使用独热编码数据,需要更多的分割点,即更大的深度,才能恢复可以使用原生处理在一个分割点获得的等效分割。
当类别被视为序数时,情况也是如此:如果类别是A..F,最佳分割是ACF - BDE,则独热编码模型需要3个分割点(左节点中每个类别一个),而非原生的序数模型需要4个分割点:1个分割点用于隔离A,1个分割点用于隔离F,以及2个分割点用于将C与BCDE隔离。
模型性能在实践中差异的大小将取决于数据集和树的灵活性。
为了说明这一点,让我们重新运行相同的分析,使用欠拟合模型,其中我们通过限制树的数量和每棵树的深度来人为地限制总分割数量。
for pipe in (hist_dropped, hist_one_hot, hist_ordinal, hist_native):
if pipe is hist_native:
# The native model does not use a pipeline so, we can set the parameters
# directly.
pipe.set_params(max_depth=3, max_iter=15)
else:
pipe.set_params(
histgradientboostingregressor__max_depth=3,
histgradientboostingregressor__max_iter=15,
)
dropped_result = cross_validate(hist_dropped, X, y, cv=n_cv_folds, scoring=scoring)
one_hot_result = cross_validate(hist_one_hot, X, y, cv=n_cv_folds, scoring=scoring)
ordinal_result = cross_validate(hist_ordinal, X, y, cv=n_cv_folds, scoring=scoring)
native_result = cross_validate(hist_native, X, y, cv=n_cv_folds, scoring=scoring)
plot_results("Gradient Boosting on Ames Housing (few and small trees)")
plt.show()
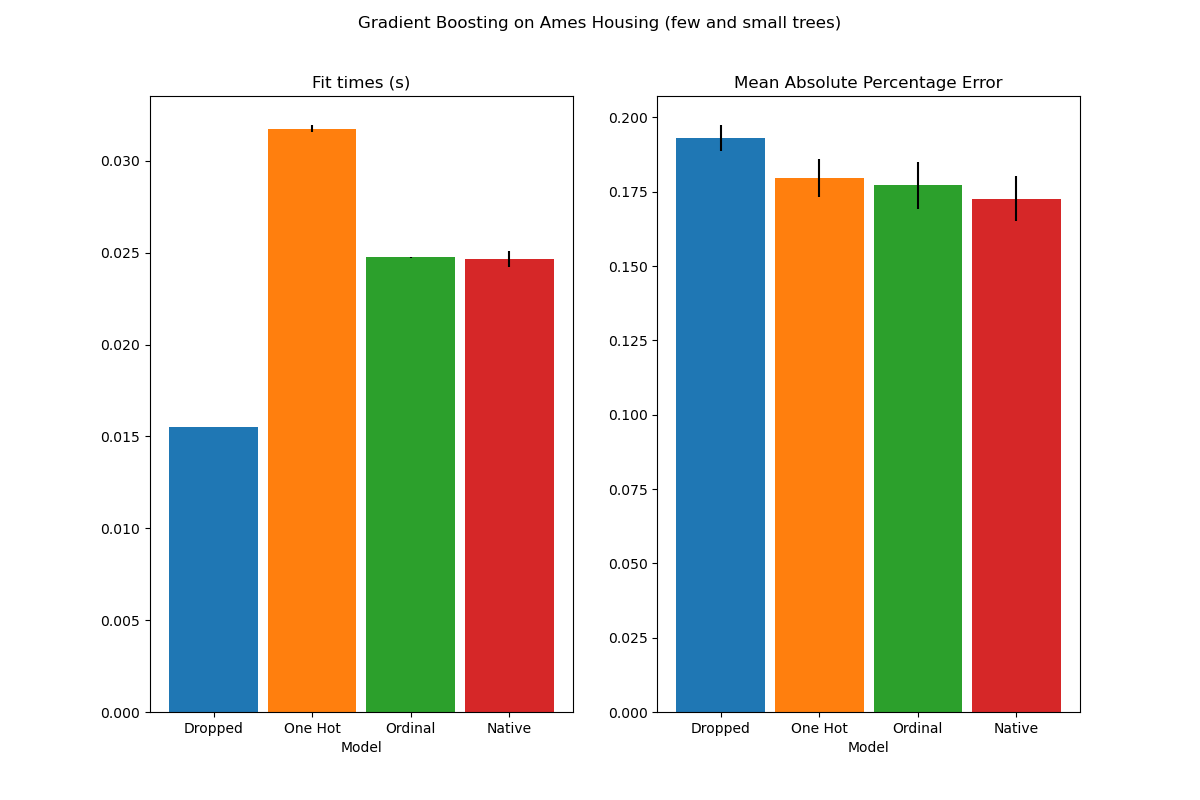
这些欠拟合模型的结果证实了我们之前的直觉:当分割预算受限时,原生的类别处理策略性能最佳。另外两种策略(独热编码和将类别视为序数值)导致的误差值与完全丢弃类别特征的基线模型相当。
脚本总运行时间:(0分钟3.502秒)
相关示例