注意
转到结尾 下载完整的示例代码。或通过JupyterLite或Binder在您的浏览器中运行此示例
使用高斯过程回归(GPR)预测莫纳罗亚数据集上的CO2水平#
此示例基于“机器学习的高斯过程”[1]的第5.4.3节。它说明了使用对数边际似然梯度上升进行复杂核工程和超参数优化的示例。数据包括在夏威夷莫纳罗亚天文台收集的1958年至2001年间的月平均大气CO2浓度(以百万分之几(ppm)表示)。目标是将CO2浓度建模为时间\(t\)的函数,并推断2001年以后的年份。
参考文献
print(__doc__)
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
构建数据集#
我们将从收集空气样本的莫纳罗亚天文台获取数据集。我们有兴趣估计CO2浓度并将其推断到未来几年。首先,我们将可从OpenML获得的原始数据集加载为pandas数据框。一旦fetch_openml添加对它的原生支持,这将被Polars替换。
from sklearn.datasets import fetch_openml
co2 = fetch_openml(data_id=41187, as_frame=True)
co2.frame.head()
首先,我们处理原始数据框以创建日期列并将其与CO2列一起选择。
import polars as pl
co2_data = pl.DataFrame(co2.frame[["year", "month", "day", "co2"]]).select(
pl.date("year", "month", "day"), "co2"
)
co2_data.head()
co2_data["date"].min(), co2_data["date"].max()
(datetime.date(1958, 3, 29), datetime.date(2001, 12, 29))
我们看到我们从1958年3月到2001年12月的一些日期获得了CO2浓度。我们可以绘制这些原始信息以更好地理解。
import matplotlib.pyplot as plt
plt.plot(co2_data["date"], co2_data["co2"])
plt.xlabel("date")
plt.ylabel("CO$_2$ concentration (ppm)")
_ = plt.title("Raw air samples measurements from the Mauna Loa Observatory")
我们将通过取月平均值并删除未收集测量的月份来预处理数据集。这种处理将对数据产生平滑效果。
co2_data = (
co2_data.sort(by="date")
.group_by_dynamic("date", every="1mo")
.agg(pl.col("co2").mean())
.drop_nulls()
)
plt.plot(co2_data["date"], co2_data["co2"])
plt.xlabel("date")
plt.ylabel("Monthly average of CO$_2$ concentration (ppm)")
_ = plt.title(
"Monthly average of air samples measurements\nfrom the Mauna Loa Observatory"
)
本例中的想法是根据日期预测CO2浓度。我们也对推断2001年以后的年份感兴趣。
第一步,我们将划分要估计的数据和目标。数据是日期,我们将将其转换为数字。
X = co2_data.select(
pl.col("date").dt.year() + pl.col("date").dt.month() / 12
).to_numpy()
y = co2_data["co2"].to_numpy()
设计合适的核#
为了设计与高斯过程一起使用的核,我们可以对现有数据进行一些假设。我们观察到它们具有几个特征:我们看到长期上升趋势、明显的季节性变化和一些较小的不规则性。我们可以使用不同的适当内核来捕获这些特征。
首先,可以使用具有较大长度尺度参数的径向基函数(RBF)核拟合长期上升趋势。具有较大长度尺度的RBF核强制该分量平滑。不会强制执行趋势增加,以便为我们的模型提供一定程度的自由度。特定的长度尺度和幅度是自由超参数。
季节性变化由具有固定周期性(1年)的周期性指数正弦平方核解释。控制其平滑度的该周期性分量的长度尺度是一个自由参数。为了允许偏离精确周期性,取与RBF核的乘积。该RBF分量的长度尺度控制衰减时间,是另一个自由参数。这种类型的核也称为局部周期性核。
from sklearn.gaussian_process.kernels import ExpSineSquared
seasonal_kernel = (
2.0**2
* RBF(length_scale=100.0)
* ExpSineSquared(length_scale=1.0, periodicity=1.0, periodicity_bounds="fixed")
)
较小的不规则性将由有理二次核分量来解释,其长度尺度和α参数(量化长度尺度的弥散性)将被确定。有理二次核等效于具有多个长度尺度的RBF核,并且将更好地适应不同的不规则性。
from sklearn.gaussian_process.kernels import RationalQuadratic
irregularities_kernel = 0.5**2 * RationalQuadratic(length_scale=1.0, alpha=1.0)
最后,数据集中的噪声可以用一个由RBF核贡献(应解释相关的噪声分量,例如局部天气现象)和白核贡献(用于白噪声)组成的核来解释。相对幅度和RBF的长度尺度是进一步的自由参数。
from sklearn.gaussian_process.kernels import WhiteKernel
noise_kernel = 0.1**2 * RBF(length_scale=0.1) + WhiteKernel(
noise_level=0.1**2, noise_level_bounds=(1e-5, 1e5)
)
因此,我们的最终核是所有先前核的加和。
co2_kernel = (
long_term_trend_kernel + seasonal_kernel + irregularities_kernel + noise_kernel
)
co2_kernel
50**2 * RBF(length_scale=50) + 2**2 * RBF(length_scale=100) * ExpSineSquared(length_scale=1, periodicity=1) + 0.5**2 * RationalQuadratic(alpha=1, length_scale=1) + 0.1**2 * RBF(length_scale=0.1) + WhiteKernel(noise_level=0.01)
模型拟合和外推#
现在,我们可以使用高斯过程回归器并拟合可用数据。为了遵循文献中的示例,我们将从目标中减去均值。我们可以使用normalize_y=True。但是,这样做也会缩放目标(将y除以其标准差)。因此,不同核的超参数将具有不同的含义,因为它们不会以ppm表示。
from sklearn.gaussian_process import GaussianProcessRegressor
y_mean = y.mean()
gaussian_process = GaussianProcessRegressor(kernel=co2_kernel, normalize_y=False)
gaussian_process.fit(X, y - y_mean)
现在,我们将使用高斯过程来预测
训练数据以检查拟合的优度;
未来数据以查看模型完成的外推。
因此,我们从1958年到本月创建合成数据。此外,我们需要添加在训练期间计算的减去均值。
import datetime
import numpy as np
today = datetime.datetime.now()
current_month = today.year + today.month / 12
X_test = np.linspace(start=1958, stop=current_month, num=1_000).reshape(-1, 1)
mean_y_pred, std_y_pred = gaussian_process.predict(X_test, return_std=True)
mean_y_pred += y_mean
plt.plot(X, y, color="black", linestyle="dashed", label="Measurements")
plt.plot(X_test, mean_y_pred, color="tab:blue", alpha=0.4, label="Gaussian process")
plt.fill_between(
X_test.ravel(),
mean_y_pred - std_y_pred,
mean_y_pred + std_y_pred,
color="tab:blue",
alpha=0.2,
)
plt.legend()
plt.xlabel("Year")
plt.ylabel("Monthly average of CO$_2$ concentration (ppm)")
_ = plt.title(
"Monthly average of air samples measurements\nfrom the Mauna Loa Observatory"
)
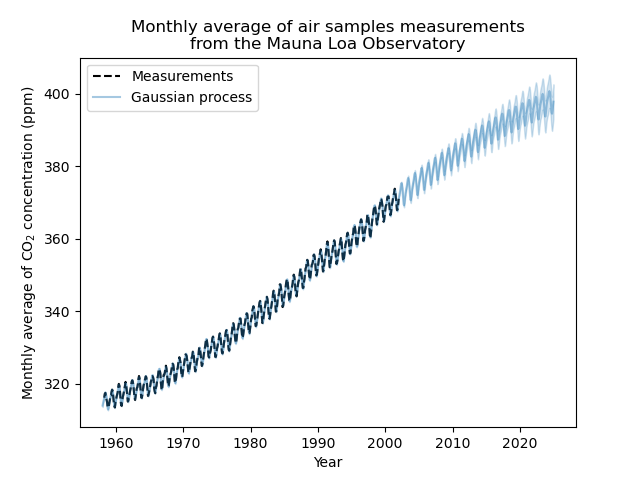
我们的拟合模型能够正确拟合先前的数据并自信地推断到未来几年。
核超参数解释#
现在,我们可以看看核的超参数。
gaussian_process.kernel_
44.8**2 * RBF(length_scale=51.6) + 2.64**2 * RBF(length_scale=91.5) * ExpSineSquared(length_scale=1.48, periodicity=1) + 0.536**2 * RationalQuadratic(alpha=2.89, length_scale=0.968) + 0.188**2 * RBF(length_scale=0.122) + WhiteKernel(noise_level=0.0367)
因此,大部分目标信号(减去均值后)可以用一个长期上升趋势来解释,该趋势约为 45 ppm,长度尺度约为 52 年。周期性分量的幅度约为 2.6 ppm,衰减时间约为 90 年,长度尺度约为 1.5。较长的衰减时间表明我们有一个非常接近季节性周期性的分量。相关噪声的幅度约为 0.2 ppm,长度尺度约为 0.12 年,白噪声贡献约为 0.04 ppm。因此,总体噪声水平非常小,表明该模型可以很好地解释数据。
脚本总运行时间:(0 分钟 4.251 秒)
相关示例