注意
转到结尾 下载完整的示例代码。或通过JupyterLite或Binder在您的浏览器中运行此示例
混淆矩阵#
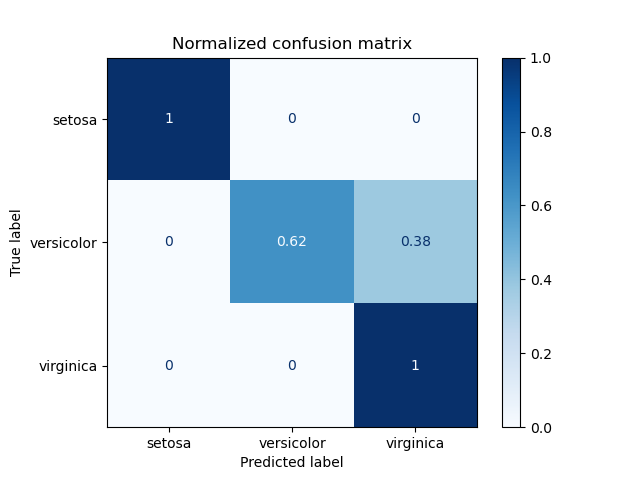
混淆矩阵使用示例,用于评估分类器在鸢尾花数据集上的输出质量。对角线元素表示预测标签等于真实标签的点数,而非对角线元素表示分类器错误标记的那些点。混淆矩阵的对角线值越高越好,表示许多预测正确。
这些图显示了有和没有按类支持大小(每个类中的元素数量)归一化的混淆矩阵。如果存在类不平衡,这种归一化对于更直观地了解哪些类被错误分类可能很有趣。
这里的结果并不理想,因为我们选择的正则化参数C不是最佳的。在实际应用中,此参数通常使用调整估计器的超参数来选择。
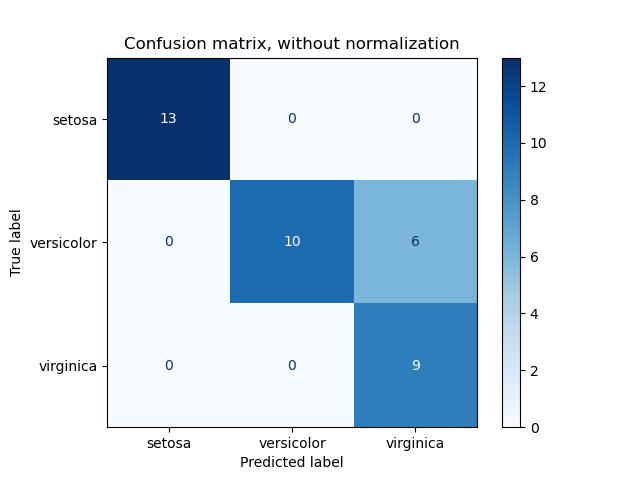
Confusion matrix, without normalization
[[13 0 0]
[ 0 10 6]
[ 0 0 9]]
Normalized confusion matrix
[[1. 0. 0. ]
[0. 0.62 0.38]
[0. 0. 1. ]]
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, svm
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.model_selection import train_test_split
# import some data to play with
iris = datasets.load_iris()
X = iris.data
y = iris.target
class_names = iris.target_names
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# Run classifier, using a model that is too regularized (C too low) to see
# the impact on the results
classifier = svm.SVC(kernel="linear", C=0.01).fit(X_train, y_train)
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
titles_options = [
("Confusion matrix, without normalization", None),
("Normalized confusion matrix", "true"),
]
for title, normalize in titles_options:
disp = ConfusionMatrixDisplay.from_estimator(
classifier,
X_test,
y_test,
display_labels=class_names,
cmap=plt.cm.Blues,
normalize=normalize,
)
disp.ax_.set_title(title)
print(title)
print(disp.confusion_matrix)
plt.show()
脚本总运行时间:(0分钟0.196秒)
相关示例