注意
转到结尾 下载完整的示例代码。或通过JupyterLite或Binder在您的浏览器中运行此示例
普通最小二乘法示例#
此示例演示如何使用scikit-learn中称为LinearRegression的普通最小二乘法(OLS)模型。
为此,我们使用糖尿病数据集中的单个特征,并尝试使用此线性模型预测糖尿病进展情况。因此,我们加载糖尿病数据集并将其分成训练集和测试集。
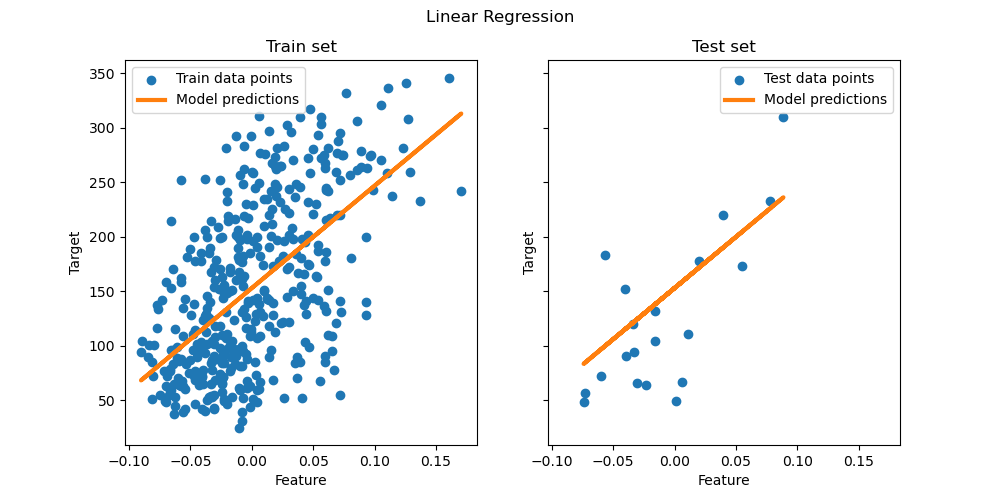
然后,我们在训练集上拟合模型,并在测试集上评估其性能,最后将结果可视化在测试集上。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
数据加载和准备#
加载糖尿病数据集。为简便起见,我们只保留数据中的单个特征。然后,我们将数据和目标分成训练集和测试集。
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
X, y = load_diabetes(return_X_y=True)
X = X[:, [2]] # Use only one feature
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=20, shuffle=False)
线性回归模型#
我们创建一个线性回归模型,并在训练数据上拟合它。请注意,默认情况下,模型会添加一个截距。我们可以通过设置fit_intercept参数来控制此行为。
from sklearn.linear_model import LinearRegression
regressor = LinearRegression().fit(X_train, y_train)
模型评估#
我们使用均方误差和决定系数来评估模型在测试集上的性能。
from sklearn.metrics import mean_squared_error, r2_score
y_pred = regressor.predict(X_test)
print(f"Mean squared error: {mean_squared_error(y_test, y_pred):.2f}")
print(f"Coefficient of determination: {r2_score(y_test, y_pred):.2f}")
Mean squared error: 2548.07
Coefficient of determination: 0.47
绘制结果#
最后,我们将训练数据和测试数据的结果可视化。
import matplotlib.pyplot as plt
fig, ax = plt.subplots(ncols=2, figsize=(10, 5), sharex=True, sharey=True)
ax[0].scatter(X_train, y_train, label="Train data points")
ax[0].plot(
X_train,
regressor.predict(X_train),
linewidth=3,
color="tab:orange",
label="Model predictions",
)
ax[0].set(xlabel="Feature", ylabel="Target", title="Train set")
ax[0].legend()
ax[1].scatter(X_test, y_test, label="Test data points")
ax[1].plot(X_test, y_pred, linewidth=3, color="tab:orange", label="Model predictions")
ax[1].set(xlabel="Feature", ylabel="Target", title="Test set")
ax[1].legend()
fig.suptitle("Linear Regression")
plt.show()
结论#
训练后的模型对应于最小化训练数据上预测目标值和真实目标值之间均方误差的估计器。因此,我们获得了给定数据条件下目标条件均值的估计器。
请注意,在更高维度下,仅最小化平方误差可能会导致过拟合。因此,通常使用正则化技术来防止此问题,例如Ridge或Lasso中实现的那些技术。
脚本的总运行时间:(0分钟0.205秒)
相关示例