注意
转到末尾 下载完整的示例代码。或通过JupyterLite或Binder在浏览器中运行此示例
最近邻回归#
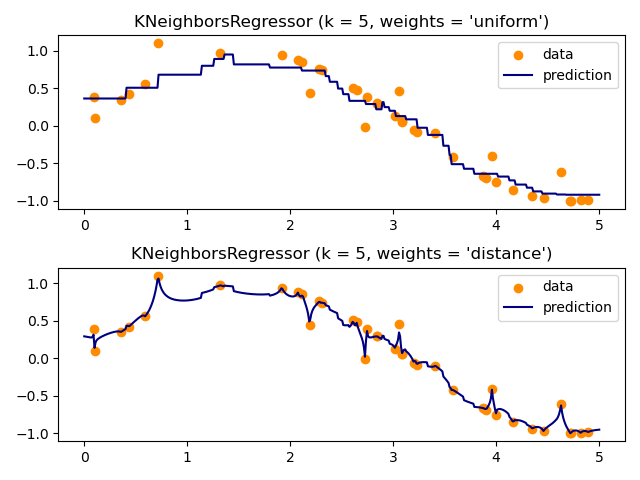
演示使用k-最近邻解决回归问题,以及使用质心和常数权重对目标进行插值。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
生成样本数据#
这里我们生成一些数据点来训练模型。我们还在整个训练数据的范围内生成数据,以可视化模型在该整个区域中的反应方式。
import matplotlib.pyplot as plt
import numpy as np
from sklearn import neighbors
rng = np.random.RandomState(0)
X_train = np.sort(5 * rng.rand(40, 1), axis=0)
X_test = np.linspace(0, 5, 500)[:, np.newaxis]
y = np.sin(X_train).ravel()
# Add noise to targets
y[::5] += 1 * (0.5 - np.random.rand(8))
拟合回归模型#
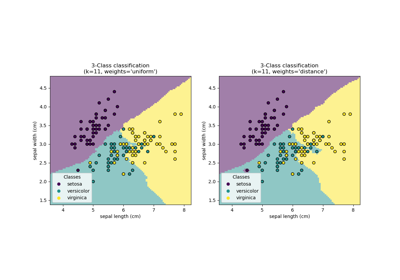
在这里,我们训练一个模型并可视化预测中uniform和distance权重如何影响预测值。
n_neighbors = 5
for i, weights in enumerate(["uniform", "distance"]):
knn = neighbors.KNeighborsRegressor(n_neighbors, weights=weights)
y_ = knn.fit(X_train, y).predict(X_test)
plt.subplot(2, 1, i + 1)
plt.scatter(X_train, y, color="darkorange", label="data")
plt.plot(X_test, y_, color="navy", label="prediction")
plt.axis("tight")
plt.legend()
plt.title("KNeighborsRegressor (k = %i, weights = '%s')" % (n_neighbors, weights))
plt.tight_layout()
plt.show()
脚本的总运行时间:(0分钟0.220秒)
相关示例