注意
转到结尾 下载完整的示例代码。或者通过JupyterLite或Binder在浏览器中运行此示例
谱双聚类算法演示#
此示例演示如何生成棋盘数据集并使用SpectralBiclustering算法对其进行双聚类。谱双聚类算法专门设计用于通过同时考虑矩阵的行(样本)和列(特征)来聚类数据。它旨在识别样本之间的模式以及样本子集内的模式,从而允许检测数据中的局部结构。这使得谱双聚类特别适合于特征顺序或排列固定的数据集,例如图像、时间序列或基因组。
数据生成后,会进行混洗,然后传递给谱双聚类算法。然后重新排列混洗矩阵的行和列,以绘制找到的双聚类。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
生成样本数据#
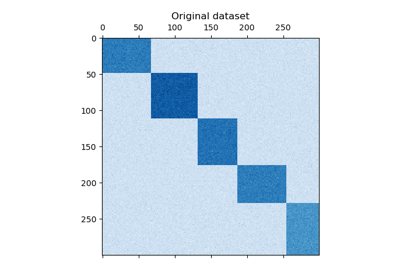
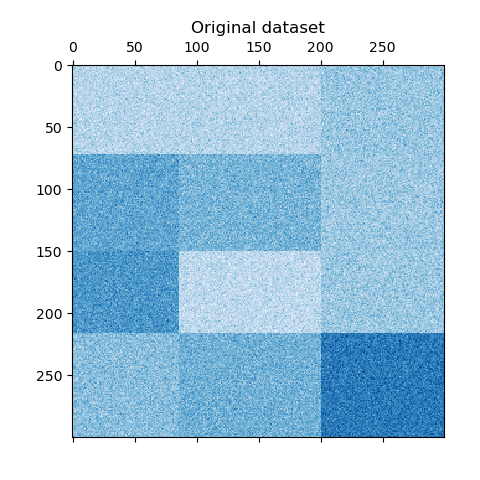
我们使用make_checkerboard函数生成样本数据。shape=(300, 300)中的每个像素都用其颜色表示来自均匀分布的值。噪声是从正态分布中添加的,其中为noise选择的数值是标准差。
正如您所看到的,数据分布在12个聚类单元上,并且相对容易区分。
from matplotlib import pyplot as plt
from sklearn.datasets import make_checkerboard
n_clusters = (4, 3)
data, rows, columns = make_checkerboard(
shape=(300, 300), n_clusters=n_clusters, noise=10, shuffle=False, random_state=42
)
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Original dataset")
_ = plt.show()
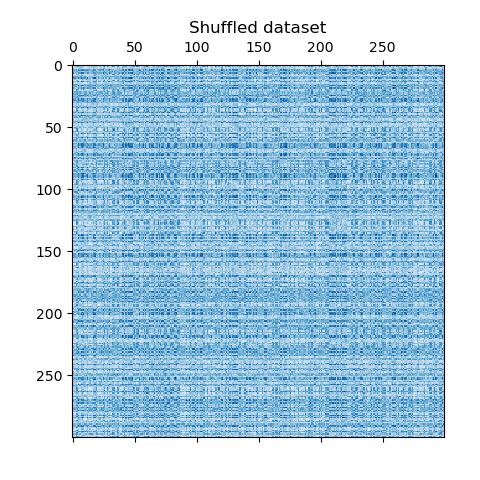
我们对数据进行混洗,目标是之后使用SpectralBiclustering对其进行重构。
import numpy as np
# Creating lists of shuffled row and column indices
rng = np.random.RandomState(0)
row_idx_shuffled = rng.permutation(data.shape[0])
col_idx_shuffled = rng.permutation(data.shape[1])
我们重新定义混洗后的数据并对其进行绘制。我们观察到我们丢失了原始数据矩阵的结构。
data = data[row_idx_shuffled][:, col_idx_shuffled]
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Shuffled dataset")
_ = plt.show()
拟合SpectralBiclustering#
我们拟合模型并将获得的聚类与真实情况进行比较。请注意,在创建模型时,我们指定了与创建数据集时使用的相同数量的聚类(n_clusters = (4, 3)),这将有助于获得良好的结果。
from sklearn.cluster import SpectralBiclustering
from sklearn.metrics import consensus_score
model = SpectralBiclustering(n_clusters=n_clusters, method="log", random_state=0)
model.fit(data)
# Compute the similarity of two sets of biclusters
score = consensus_score(
model.biclusters_, (rows[:, row_idx_shuffled], columns[:, col_idx_shuffled])
)
print(f"consensus score: {score:.1f}")
consensus score: 1.0
分数介于0和1之间,其中1对应于完美的匹配。它显示了双聚类的质量。
绘制结果#
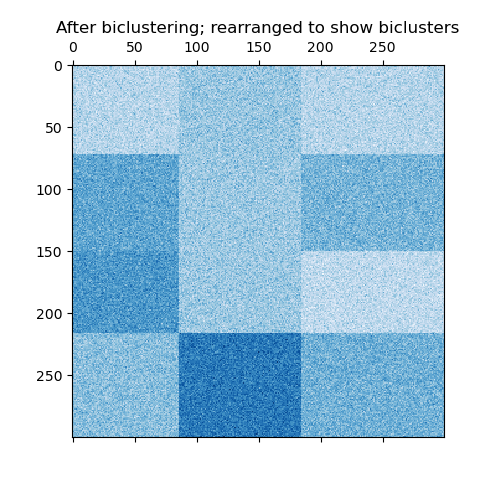
现在,我们根据SpectralBiclustering模型分配的行和列标签按升序重新排列数据,然后再次绘制。 row_labels_范围从0到3,而column_labels_范围从0到2,表示每行共有4个聚类,每列共有3个聚类。
# Reordering first the rows and then the columns.
reordered_rows = data[np.argsort(model.row_labels_)]
reordered_data = reordered_rows[:, np.argsort(model.column_labels_)]
plt.matshow(reordered_data, cmap=plt.cm.Blues)
plt.title("After biclustering; rearranged to show biclusters")
_ = plt.show()
最后一步,我们想演示模型分配的行标签和列标签之间的关系。因此,我们使用numpy.outer创建一个网格,它采用排序后的row_labels_和column_labels_,并为每个标签加1,以确保标签从1而不是0开始,以便更好地可视化。
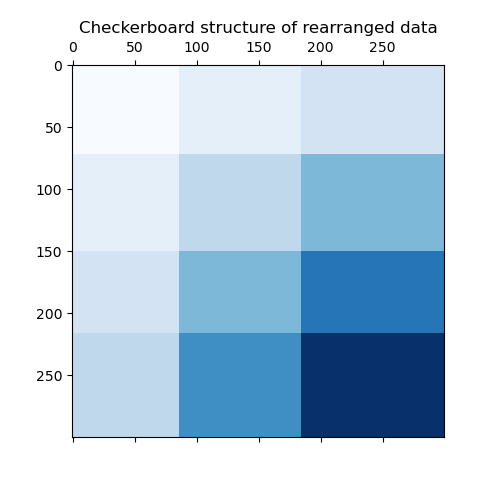
行和列标签向量的外积显示了棋盘结构的表示,其中行和列标签的不同组合由不同深浅的蓝色表示。
脚本总运行时间:(0分钟0.576秒)
相关示例