注意
转到结尾 下载完整的示例代码。或通过JupyterLite或Binder在浏览器中运行此示例
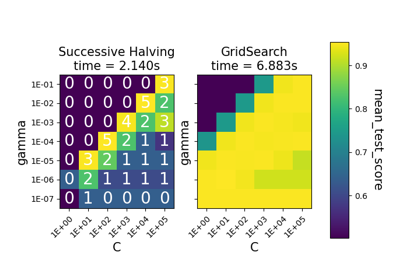
逐次减半迭代#
此示例说明了逐次减半搜索(HalvingGridSearchCV 和 HalvingRandomSearchCV)如何迭代地从多个候选参数组合中选择最佳参数组合。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy.stats import randint
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.experimental import enable_halving_search_cv # noqa
from sklearn.model_selection import HalvingRandomSearchCV
我们首先定义参数空间并训练一个HalvingRandomSearchCV实例。
rng = np.random.RandomState(0)
X, y = datasets.make_classification(n_samples=400, n_features=12, random_state=rng)
clf = RandomForestClassifier(n_estimators=20, random_state=rng)
param_dist = {
"max_depth": [3, None],
"max_features": randint(1, 6),
"min_samples_split": randint(2, 11),
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
}
rsh = HalvingRandomSearchCV(
estimator=clf, param_distributions=param_dist, factor=2, random_state=rng
)
rsh.fit(X, y)
现在我们可以使用搜索估计器的cv_results_属性来检查和绘制搜索的演变过程。
results = pd.DataFrame(rsh.cv_results_)
results["params_str"] = results.params.apply(str)
results.drop_duplicates(subset=("params_str", "iter"), inplace=True)
mean_scores = results.pivot(
index="iter", columns="params_str", values="mean_test_score"
)
ax = mean_scores.plot(legend=False, alpha=0.6)
labels = [
f"iter={i}\nn_samples={rsh.n_resources_[i]}\nn_candidates={rsh.n_candidates_[i]}"
for i in range(rsh.n_iterations_)
]
ax.set_xticks(range(rsh.n_iterations_))
ax.set_xticklabels(labels, rotation=45, multialignment="left")
ax.set_title("Scores of candidates over iterations")
ax.set_ylabel("mean test score", fontsize=15)
ax.set_xlabel("iterations", fontsize=15)
plt.tight_layout()
plt.show()
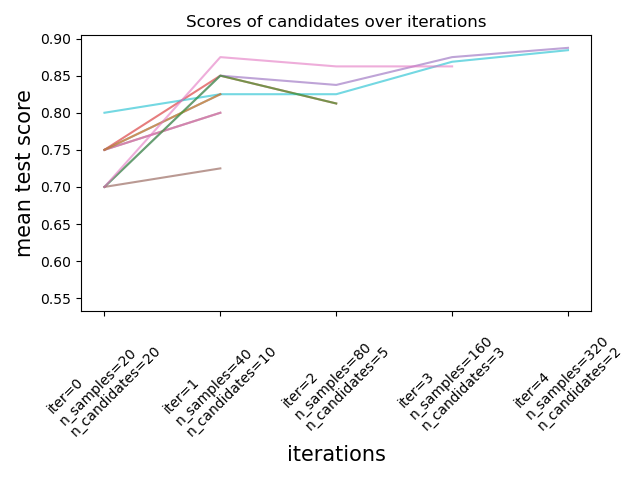
每次迭代的候选数量和资源量#
在第一次迭代中,使用少量资源。这里的资源是指估计器训练所使用的样本数量。所有候选参数都会被评估。
在第二次迭代中,只有最佳一半的候选参数会被评估。分配的资源数量加倍:候选参数会在两倍数量的样本上进行评估。
这个过程会重复进行,直到最后一次迭代,只剩下2个候选参数。最佳候选参数是在最后一次迭代中得分最高的候选参数。
脚本总运行时间:(0分钟5.725秒)
相关示例