注意
转到结尾 下载完整的示例代码。或通过 JupyterLite 或 Binder 在浏览器中运行此示例
分位数回归#
此示例说明了分位数回归如何预测非平凡的条件分位数。
左图显示了误差分布为正态分布但方差非恒定(即具有异方差性)的情况。
右图显示了一个非对称误差分布的示例,即帕累托分布。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
数据集生成#
为了说明分位数回归的行为,我们将生成两个合成数据集。这两个数据集的真实生成随机过程将由相同的期望值组成,该期望值与单个特征x具有线性关系。
import numpy as np
rng = np.random.RandomState(42)
x = np.linspace(start=0, stop=10, num=100)
X = x[:, np.newaxis]
y_true_mean = 10 + 0.5 * x
我们将通过改变目标y的分布来创建两个后续问题,同时保持相同的期望值。
在第一种情况下,添加了异方差正态噪声;
在第二种情况下,添加了非对称帕累托噪声。
y_normal = y_true_mean + rng.normal(loc=0, scale=0.5 + 0.5 * x, size=x.shape[0])
a = 5
y_pareto = y_true_mean + 10 * (rng.pareto(a, size=x.shape[0]) - 1 / (a - 1))
让我们首先将数据集以及残差y - mean(y)的分布可视化。
import matplotlib.pyplot as plt
_, axs = plt.subplots(nrows=2, ncols=2, figsize=(15, 11), sharex="row", sharey="row")
axs[0, 0].plot(x, y_true_mean, label="True mean")
axs[0, 0].scatter(x, y_normal, color="black", alpha=0.5, label="Observations")
axs[1, 0].hist(y_true_mean - y_normal, edgecolor="black")
axs[0, 1].plot(x, y_true_mean, label="True mean")
axs[0, 1].scatter(x, y_pareto, color="black", alpha=0.5, label="Observations")
axs[1, 1].hist(y_true_mean - y_pareto, edgecolor="black")
axs[0, 0].set_title("Dataset with heteroscedastic Normal distributed targets")
axs[0, 1].set_title("Dataset with asymmetric Pareto distributed target")
axs[1, 0].set_title(
"Residuals distribution for heteroscedastic Normal distributed targets"
)
axs[1, 1].set_title("Residuals distribution for asymmetric Pareto distributed target")
axs[0, 0].legend()
axs[0, 1].legend()
axs[0, 0].set_ylabel("y")
axs[1, 0].set_ylabel("Counts")
axs[0, 1].set_xlabel("x")
axs[0, 0].set_xlabel("x")
axs[1, 0].set_xlabel("Residuals")
_ = axs[1, 1].set_xlabel("Residuals")
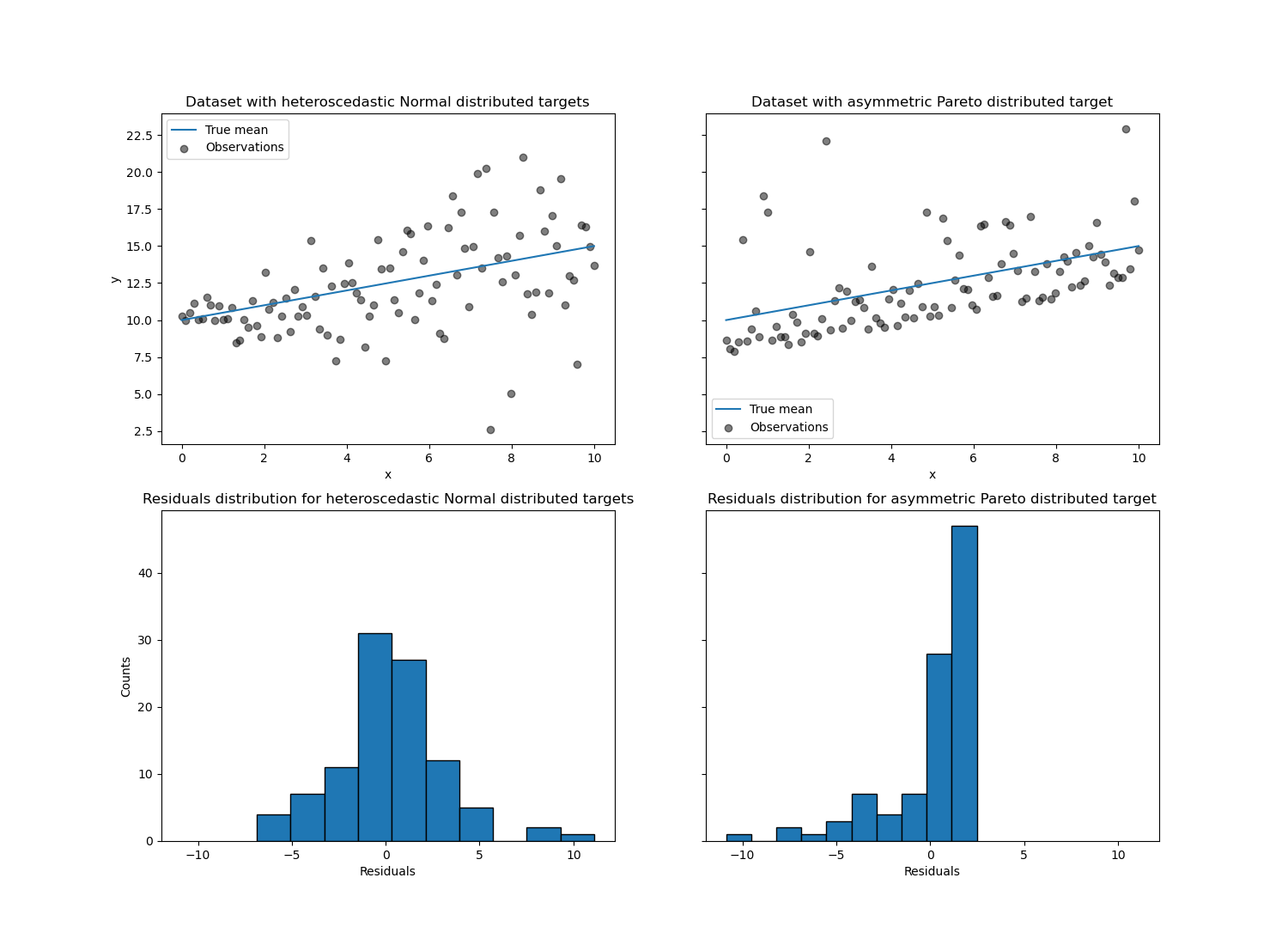
对于具有异方差正态分布的目标,我们观察到当特征x的值增加时,噪声的方差也在增加。
对于具有非对称帕累托分布的目标,我们观察到正残差是有界的。
这些类型的噪声目标使得通过LinearRegression进行估计效率较低,即我们需要更多数据才能获得稳定的结果,此外,大的异常值会对拟合系数产生巨大的影响。(换句话说:在方差恒定的情况下,普通最小二乘估计量随着样本量的增加而更快地收敛到真实系数。)
在这种非对称设置中,中位数或不同的分位数提供了额外的见解。最重要的是,中位数估计对异常值和重尾分布更为稳健。但请注意,极端分位数是由非常少的数点估计的。95% 分位数或多或少是由 5% 的最大值估计的,因此也对异常值有点敏感。
在本教程的其余部分,我们将展示如何在实践中使用QuantileRegressor 并了解拟合模型的特性。最后,我们将比较QuantileRegressor和LinearRegression。
拟合 QuantileRegressor#
在本节中,我们想估计条件中位数以及分别固定在 5% 和 95% 的低分位数和高分位数。因此,我们将得到三个线性模型,每个分位数一个。
我们将使用 5% 和 95% 的分位数来查找训练样本中超出中心 90% 区间的异常值。
from sklearn.linear_model import QuantileRegressor
quantiles = [0.05, 0.5, 0.95]
predictions = {}
out_bounds_predictions = np.zeros_like(y_true_mean, dtype=np.bool_)
for quantile in quantiles:
qr = QuantileRegressor(quantile=quantile, alpha=0)
y_pred = qr.fit(X, y_normal).predict(X)
predictions[quantile] = y_pred
if quantile == min(quantiles):
out_bounds_predictions = np.logical_or(
out_bounds_predictions, y_pred >= y_normal
)
elif quantile == max(quantiles):
out_bounds_predictions = np.logical_or(
out_bounds_predictions, y_pred <= y_normal
)
现在,我们可以绘制三个线性模型以及在中心 90% 区间内的样本和区间外的样本。
plt.plot(X, y_true_mean, color="black", linestyle="dashed", label="True mean")
for quantile, y_pred in predictions.items():
plt.plot(X, y_pred, label=f"Quantile: {quantile}")
plt.scatter(
x[out_bounds_predictions],
y_normal[out_bounds_predictions],
color="black",
marker="+",
alpha=0.5,
label="Outside interval",
)
plt.scatter(
x[~out_bounds_predictions],
y_normal[~out_bounds_predictions],
color="black",
alpha=0.5,
label="Inside interval",
)
plt.legend()
plt.xlabel("x")
plt.ylabel("y")
_ = plt.title("Quantiles of heteroscedastic Normal distributed target")
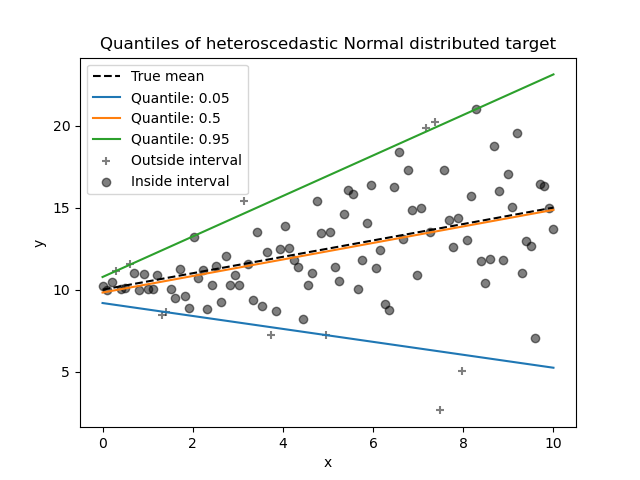
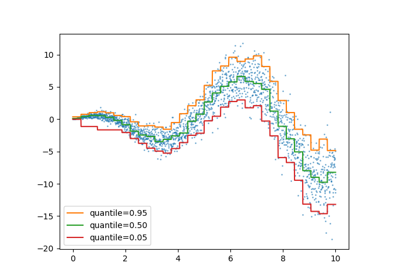
由于噪声仍然是正态分布的,特别是对称的,因此真实的条件均值和真实的条件中位数重合。事实上,我们看到估计的中位数几乎达到了真实的均值。我们观察到具有递增噪声方差对 5% 和 95% 分位数的影响:这些分位数的斜率非常不同,并且它们之间的区间随着x的增加而变宽。
为了更好地理解 5% 和 95% 分位数估计量的含义,可以计算在预测分位数上方和下方的样本数量(在上图中用十字表示),考虑到我们共有 100 个样本。
我们可以使用非对称帕累托分布的目标重复相同的实验。
quantiles = [0.05, 0.5, 0.95]
predictions = {}
out_bounds_predictions = np.zeros_like(y_true_mean, dtype=np.bool_)
for quantile in quantiles:
qr = QuantileRegressor(quantile=quantile, alpha=0)
y_pred = qr.fit(X, y_pareto).predict(X)
predictions[quantile] = y_pred
if quantile == min(quantiles):
out_bounds_predictions = np.logical_or(
out_bounds_predictions, y_pred >= y_pareto
)
elif quantile == max(quantiles):
out_bounds_predictions = np.logical_or(
out_bounds_predictions, y_pred <= y_pareto
)
plt.plot(X, y_true_mean, color="black", linestyle="dashed", label="True mean")
for quantile, y_pred in predictions.items():
plt.plot(X, y_pred, label=f"Quantile: {quantile}")
plt.scatter(
x[out_bounds_predictions],
y_pareto[out_bounds_predictions],
color="black",
marker="+",
alpha=0.5,
label="Outside interval",
)
plt.scatter(
x[~out_bounds_predictions],
y_pareto[~out_bounds_predictions],
color="black",
alpha=0.5,
label="Inside interval",
)
plt.legend()
plt.xlabel("x")
plt.ylabel("y")
_ = plt.title("Quantiles of asymmetric Pareto distributed target")
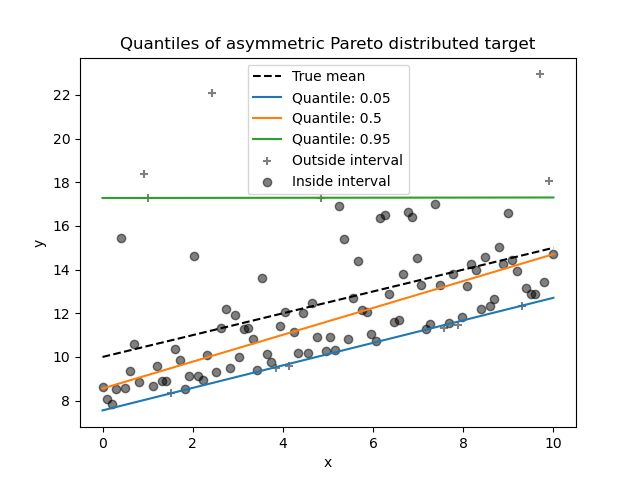
由于噪声分布的不对称性,我们观察到真实的均值和估计的条件中位数是不同的。我们还观察到每个分位数模型具有不同的参数以更好地拟合所需的分位数。请注意,理想情况下,在这种情况下,所有分位数都将是平行的,这在具有更多数据点或不太极端的分位数(例如 10% 和 90%)时将更加明显。
比较 QuantileRegressor 和 LinearRegression#
在本节中,我们将详细讨论QuantileRegressor 和LinearRegression 所最小化的误差方面的差异。
事实上,LinearRegression 是一种最小二乘法,它最小化训练目标和预测目标之间的均方误差 (MSE)。相比之下,QuantileRegressor 当 quantile=0.5 时,则最小化平均绝对误差 (MAE)。
让我们首先根据均方误差和平均绝对误差计算这些模型的训练误差。我们将使用非对称帕累托分布的目标变量来使问题更有趣一些,因为均值和中位数并不相等。
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error
linear_regression = LinearRegression()
quantile_regression = QuantileRegressor(quantile=0.5, alpha=0)
y_pred_lr = linear_regression.fit(X, y_pareto).predict(X)
y_pred_qr = quantile_regression.fit(X, y_pareto).predict(X)
print(
f"""Training error (in-sample performance)
{linear_regression.__class__.__name__}:
MAE = {mean_absolute_error(y_pareto, y_pred_lr):.3f}
MSE = {mean_squared_error(y_pareto, y_pred_lr):.3f}
{quantile_regression.__class__.__name__}:
MAE = {mean_absolute_error(y_pareto, y_pred_qr):.3f}
MSE = {mean_squared_error(y_pareto, y_pred_qr):.3f}
"""
)
Training error (in-sample performance)
LinearRegression:
MAE = 1.805
MSE = 6.486
QuantileRegressor:
MAE = 1.670
MSE = 7.025
在训练集上,我们可以看到 QuantileRegressor 的 MAE 低于 LinearRegression。 与此相反,LinearRegression 的 MSE 低于 QuantileRegressor。 这些结果证实了 MAE 是 QuantileRegressor 最小化的损失函数,而 MSE 是 LinearRegression 最小化的损失函数。
我们可以通过查看交叉验证获得的测试误差来进行类似的评估。
from sklearn.model_selection import cross_validate
cv_results_lr = cross_validate(
linear_regression,
X,
y_pareto,
cv=3,
scoring=["neg_mean_absolute_error", "neg_mean_squared_error"],
)
cv_results_qr = cross_validate(
quantile_regression,
X,
y_pareto,
cv=3,
scoring=["neg_mean_absolute_error", "neg_mean_squared_error"],
)
print(
f"""Test error (cross-validated performance)
{linear_regression.__class__.__name__}:
MAE = {-cv_results_lr["test_neg_mean_absolute_error"].mean():.3f}
MSE = {-cv_results_lr["test_neg_mean_squared_error"].mean():.3f}
{quantile_regression.__class__.__name__}:
MAE = {-cv_results_qr["test_neg_mean_absolute_error"].mean():.3f}
MSE = {-cv_results_qr["test_neg_mean_squared_error"].mean():.3f}
"""
)
Test error (cross-validated performance)
LinearRegression:
MAE = 1.732
MSE = 6.690
QuantileRegressor:
MAE = 1.679
MSE = 7.129
我们在样本外评估中得出了类似的结论。
脚本总运行时间:(0 分钟 0.588 秒)
相关示例