注意
转到结尾 下载完整的示例代码。或通过 JupyterLite 或 Binder 在浏览器中运行此示例
异常检测估计器的评估#
本示例比较了两种异常值检测算法,即局部异常因子 (Local Outlier Factor) (LOF) 和孤立森林 (Isolation Forest) (IForest),使用的是 sklearn.datasets 中提供的真实世界数据集。目标是展示不同的算法在不同的数据集上表现良好,并对比它们的训练速度和对超参数的敏感性。
这些算法在整个数据集上进行训练(无需标签),假设数据集包含异常值。
1. 使用真实标签计算ROC曲线,并使用RocCurveDisplay显示。
性能根据ROC-AUC进行评估。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
数据集预处理和模型训练#
不同的异常值检测模型需要不同的预处理。在存在分类变量的情况下,对于基于树的模型(例如IsolationForest),OrdinalEncoder通常是一个不错的策略,而基于邻居的模型(例如LocalOutlierFactor)则会受到序数编码引起的排序的影响。为了避免引入排序,应该使用OneHotEncoder。
基于邻居的模型可能还需要对数值特征进行缩放(例如,参见重新缩放对k-近邻模型的影响)。在存在异常值的情况下,一个不错的选择是使用RobustScaler。
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import IsolationForest
from sklearn.neighbors import LocalOutlierFactor
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import (
OneHotEncoder,
OrdinalEncoder,
RobustScaler,
)
def make_estimator(name, categorical_columns=None, iforest_kw=None, lof_kw=None):
"""Create an outlier detection estimator based on its name."""
if name == "LOF":
outlier_detector = LocalOutlierFactor(**(lof_kw or {}))
if categorical_columns is None:
preprocessor = RobustScaler()
else:
preprocessor = ColumnTransformer(
transformers=[("categorical", OneHotEncoder(), categorical_columns)],
remainder=RobustScaler(),
)
else: # name == "IForest"
outlier_detector = IsolationForest(**(iforest_kw or {}))
if categorical_columns is None:
preprocessor = None
else:
ordinal_encoder = OrdinalEncoder(
handle_unknown="use_encoded_value", unknown_value=-1
)
preprocessor = ColumnTransformer(
transformers=[
("categorical", ordinal_encoder, categorical_columns),
],
remainder="passthrough",
)
return make_pipeline(preprocessor, outlier_detector)
下面的fit_predict函数返回X的平均异常值分数。
from time import perf_counter
def fit_predict(estimator, X):
tic = perf_counter()
if estimator[-1].__class__.__name__ == "LocalOutlierFactor":
estimator.fit(X)
y_pred = estimator[-1].negative_outlier_factor_
else: # "IsolationForest"
y_pred = estimator.fit(X).decision_function(X)
toc = perf_counter()
print(f"Duration for {model_name}: {toc - tic:.2f} s")
return y_pred
在本示例的其余部分,我们每个部分处理一个数据集。加载数据后,目标被修改为包含两类:0代表内点,1代表异常值。由于scikit-learn文档的计算限制,某些数据集的样本大小使用分层的train_test_split进行了减少。
此外,我们设置n_neighbors以匹配预期的异常值数量expected_n_anomalies = n_samples * expected_anomaly_fraction。只要异常值的比例不是非常低,这是一个很好的启发式方法,原因是n_neighbors至少应该大于人口较少的集群中的样本数量(参见使用局部异常因子 (LOF) 进行异常值检测)。
KDDCup99 - SA数据集#
Kddcup 99数据集是使用封闭网络和人工注入的攻击生成的。SA数据集是通过简单地选择所有正常数据和大约3%的异常比例获得的子集。
import numpy as np
from sklearn.datasets import fetch_kddcup99
from sklearn.model_selection import train_test_split
X, y = fetch_kddcup99(
subset="SA", percent10=True, random_state=42, return_X_y=True, as_frame=True
)
y = (y != b"normal.").astype(np.int32)
X, _, y, _ = train_test_split(X, y, train_size=0.1, stratify=y, random_state=42)
n_samples, anomaly_frac = X.shape[0], y.mean()
print(f"{n_samples} datapoints with {y.sum()} anomalies ({anomaly_frac:.02%})")
10065 datapoints with 338 anomalies (3.36%)
SA数据集包含41个特征,其中3个是分类特征:“protocol_type”、“service”和“flag”。
y_true = {}
y_pred = {"LOF": {}, "IForest": {}}
model_names = ["LOF", "IForest"]
cat_columns = ["protocol_type", "service", "flag"]
y_true["KDDCup99 - SA"] = y
for model_name in model_names:
model = make_estimator(
name=model_name,
categorical_columns=cat_columns,
lof_kw={"n_neighbors": int(n_samples * anomaly_frac)},
iforest_kw={"random_state": 42},
)
y_pred[model_name]["KDDCup99 - SA"] = fit_predict(model, X)
Duration for LOF: 2.14 s
Duration for IForest: 0.31 s
森林覆盖类型数据集#
森林覆盖类型是一个多类数据集,目标是给定森林区域内主要的树种。它包含54个特征,其中一些(“Wilderness_Area”和“Soil_Type”)已经是二进制编码的。虽然最初是作为分类任务设计的,但可以将内点视为标注为2的样本,将异常值视为标注为4的样本。
from sklearn.datasets import fetch_covtype
X, y = fetch_covtype(return_X_y=True, as_frame=True)
s = (y == 2) + (y == 4)
X = X.loc[s]
y = y.loc[s]
y = (y != 2).astype(np.int32)
X, _, y, _ = train_test_split(X, y, train_size=0.05, stratify=y, random_state=42)
X_forestcover = X # save X for later use
n_samples, anomaly_frac = X.shape[0], y.mean()
print(f"{n_samples} datapoints with {y.sum()} anomalies ({anomaly_frac:.02%})")
14302 datapoints with 137 anomalies (0.96%)
y_true["forestcover"] = y
for model_name in model_names:
model = make_estimator(
name=model_name,
lof_kw={"n_neighbors": int(n_samples * anomaly_frac)},
iforest_kw={"random_state": 42},
)
y_pred[model_name]["forestcover"] = fit_predict(model, X)
Duration for LOF: 1.89 s
Duration for IForest: 0.26 s
Ames 房屋数据集#
Ames 房屋数据集最初是一个回归数据集,目标是爱荷华州Ames市房屋的销售价格。在这里,我们将它转换为异常值检测问题,将价格超过70美元/平方英尺的房屋视为异常值。为了简化问题,我们删除了40到70美元/平方英尺之间的中间价格。
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
X, y = fetch_openml(name="ames_housing", version=1, return_X_y=True, as_frame=True)
y = y.div(X["Lot_Area"])
# None values in pandas 1.5.1 were mapped to np.nan in pandas 2.0.1
X["Misc_Feature"] = X["Misc_Feature"].cat.add_categories("NoInfo").fillna("NoInfo")
X["Mas_Vnr_Type"] = X["Mas_Vnr_Type"].cat.add_categories("NoInfo").fillna("NoInfo")
X.drop(columns="Lot_Area", inplace=True)
mask = (y < 40) | (y > 70)
X = X.loc[mask]
y = y.loc[mask]
y.hist(bins=20, edgecolor="black")
plt.xlabel("House price in USD/sqft")
_ = plt.title("Distribution of house prices in Ames")
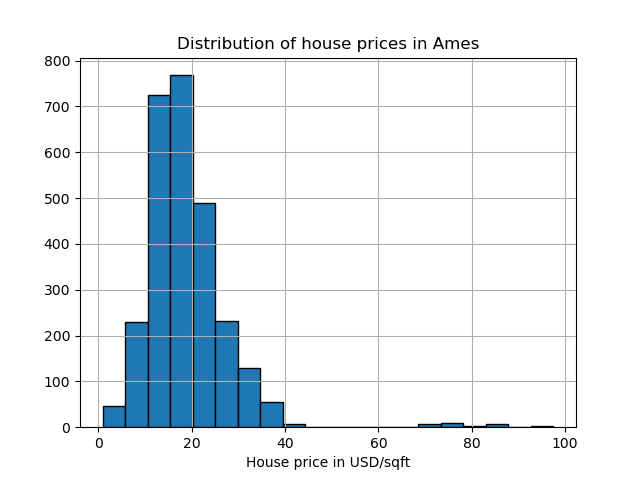
y = (y > 70).astype(np.int32)
n_samples, anomaly_frac = X.shape[0], y.mean()
print(f"{n_samples} datapoints with {y.sum()} anomalies ({anomaly_frac:.02%})")
2714 datapoints with 30 anomalies (1.11%)
该数据集包含46个分类特征。在这种情况下,使用make_column_selector来查找它们比手工传递列表更容易。
from sklearn.compose import make_column_selector as selector
categorical_columns_selector = selector(dtype_include="category")
cat_columns = categorical_columns_selector(X)
y_true["ames_housing"] = y
for model_name in model_names:
model = make_estimator(
name=model_name,
categorical_columns=cat_columns,
lof_kw={"n_neighbors": int(n_samples * anomaly_frac)},
iforest_kw={"random_state": 42},
)
y_pred[model_name]["ames_housing"] = fit_predict(model, X)
Duration for LOF: 0.93 s
Duration for IForest: 0.24 s
胎心图数据集#
胎心图数据集是一个关于胎儿胎心图的多类数据集,类别是胎儿心率 (FHR) 模式,用1到10的标签编码。在这里,我们将3类(少数类)设置为代表异常值。它包含30个数值特征,其中一些是二进制编码的,一些是连续的。
X, y = fetch_openml(name="cardiotocography", version=1, return_X_y=True, as_frame=False)
X_cardiotocography = X # save X for later use
s = y == "3"
y = s.astype(np.int32)
n_samples, anomaly_frac = X.shape[0], y.mean()
print(f"{n_samples} datapoints with {y.sum()} anomalies ({anomaly_frac:.02%})")
2126 datapoints with 53 anomalies (2.49%)
y_true["cardiotocography"] = y
for model_name in model_names:
model = make_estimator(
name=model_name,
lof_kw={"n_neighbors": int(n_samples * anomaly_frac)},
iforest_kw={"random_state": 42},
)
y_pred[model_name]["cardiotocography"] = fit_predict(model, X)
Duration for LOF: 0.06 s
Duration for IForest: 0.16 s
绘制和解释结果#
算法性能与在低假阳性率 (FPR) 值下真阳性率 (TPR) 的好坏有关。最好的算法的曲线位于图的左上方,曲线下面积 (AUC) 接近1。对角虚线表示对异常值和内点的随机分类。
import math
from sklearn.metrics import RocCurveDisplay
cols = 2
pos_label = 0 # mean 0 belongs to positive class
datasets_names = y_true.keys()
rows = math.ceil(len(datasets_names) / cols)
fig, axs = plt.subplots(nrows=rows, ncols=cols, squeeze=False, figsize=(10, rows * 4))
for ax, dataset_name in zip(axs.ravel(), datasets_names):
for model_idx, model_name in enumerate(model_names):
display = RocCurveDisplay.from_predictions(
y_true[dataset_name],
y_pred[model_name][dataset_name],
pos_label=pos_label,
name=model_name,
ax=ax,
plot_chance_level=(model_idx == len(model_names) - 1),
chance_level_kw={"linestyle": ":"},
)
ax.set_title(dataset_name)
_ = plt.tight_layout(pad=2.0) # spacing between subplots
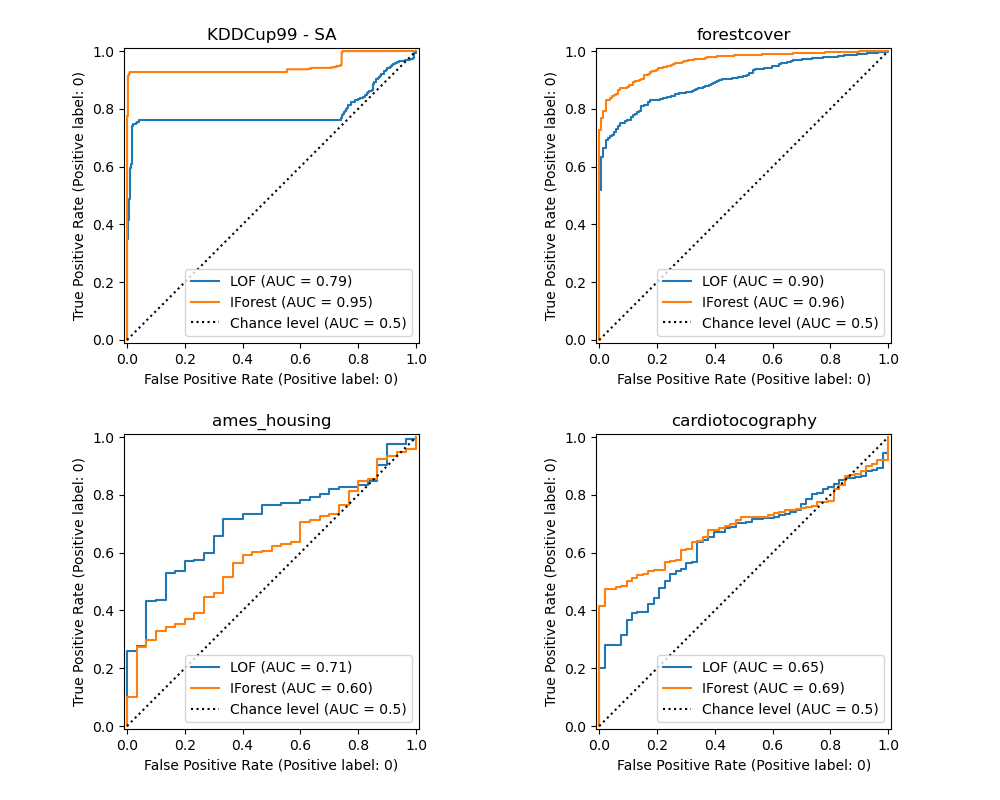
我们观察到,一旦调整了邻居的数量,LOF和IForest在森林覆盖和胎心图数据集上的ROC AUC方面表现相似。对于SA数据集,IForest的分数略好,而LOF在Ames房屋数据集上的表现明显优于IForest。
但是,请记住,在样本数量大的数据集上,孤立森林的训练速度往往比LOF快得多。LOF需要计算成对距离来寻找最近邻居,这对于观测数量具有二次复杂度。这使得这种方法在大型数据集上可能难以应用。
消融研究#
在本节中,我们将探讨超参数n_neighbors以及数值变量缩放对LOF模型的影响。这里我们使用森林覆盖类型数据集,因为二进制编码的类别引入了0到1之间的自然欧几里得距离尺度。然后,我们需要一种缩放方法来避免赋予非二进制特征特权,并且该方法对异常值足够稳健,以便寻找异常值的任务不会变得过于困难。
X = X_forestcover
y = y_true["forestcover"]
n_samples = X.shape[0]
n_neighbors_list = (n_samples * np.array([0.2, 0.02, 0.01, 0.001])).astype(np.int32)
model = make_pipeline(RobustScaler(), LocalOutlierFactor())
linestyles = ["solid", "dashed", "dashdot", ":", (5, (10, 3))]
fig, ax = plt.subplots()
for model_idx, (linestyle, n_neighbors) in enumerate(zip(linestyles, n_neighbors_list)):
model.set_params(localoutlierfactor__n_neighbors=n_neighbors)
model.fit(X)
y_pred = model[-1].negative_outlier_factor_
display = RocCurveDisplay.from_predictions(
y,
y_pred,
pos_label=pos_label,
name=f"n_neighbors = {n_neighbors}",
ax=ax,
plot_chance_level=(model_idx == len(n_neighbors_list) - 1),
chance_level_kw={"linestyle": (0, (1, 10))},
linestyle=linestyle,
linewidth=2,
)
_ = ax.set_title("RobustScaler with varying n_neighbors\non forestcover dataset")
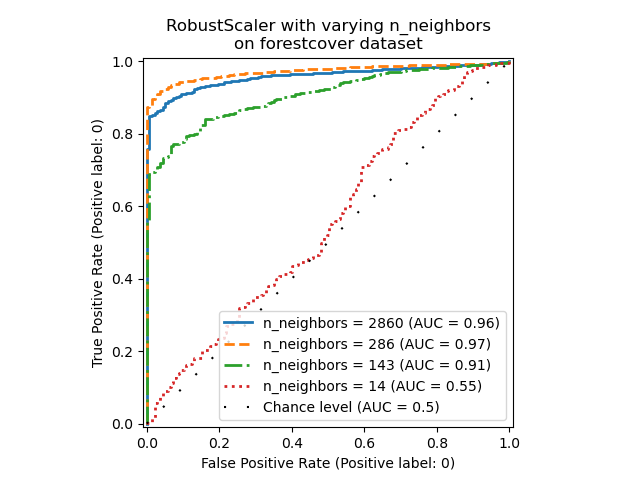
我们观察到,邻居的数量对模型的性能有很大影响。如果能够访问(至少一部分)真实标签,那么对n_neighbors进行相应的调整非常重要。n_neighbors值的一个便捷选择方法是探索与预期污染程度数量级相同的数值。
from sklearn.preprocessing import MinMaxScaler, SplineTransformer, StandardScaler
preprocessor_list = [
None,
RobustScaler(),
StandardScaler(),
MinMaxScaler(),
SplineTransformer(),
]
expected_anomaly_fraction = 0.02
lof = LocalOutlierFactor(n_neighbors=int(n_samples * expected_anomaly_fraction))
fig, ax = plt.subplots()
for model_idx, (linestyle, preprocessor) in enumerate(
zip(linestyles, preprocessor_list)
):
model = make_pipeline(preprocessor, lof)
model.fit(X)
y_pred = model[-1].negative_outlier_factor_
display = RocCurveDisplay.from_predictions(
y,
y_pred,
pos_label=pos_label,
name=str(preprocessor).split("(")[0],
ax=ax,
plot_chance_level=(model_idx == len(preprocessor_list) - 1),
chance_level_kw={"linestyle": (0, (1, 10))},
linestyle=linestyle,
linewidth=2,
)
_ = ax.set_title("Fixed n_neighbors with varying preprocessing\non forestcover dataset")
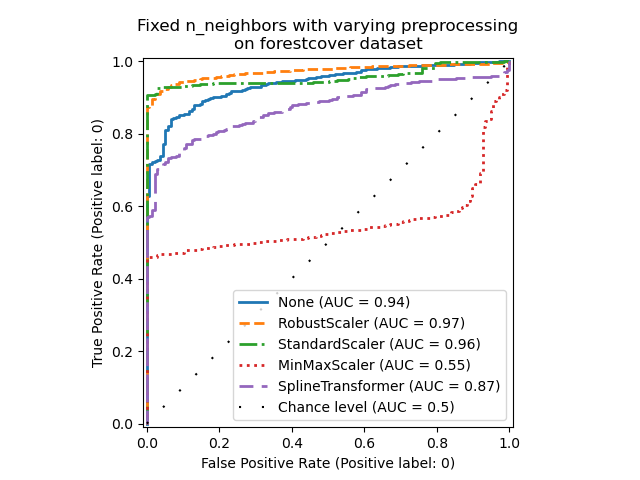
一方面,RobustScaler默认情况下使用四分位距 (IQR) 来独立缩放每个特征,IQR 是数据第25个和第75个百分位数之间的范围。它通过减去中位数来对数据进行中心化,然后通过除以IQR来进行缩放。IQR 对异常值具有鲁棒性:与范围、均值和标准差相比,中位数和四分位距受极值的影响较小。此外,与StandardScaler相反,RobustScaler不会压缩边缘异常值。
另一方面,MinMaxScaler单独缩放每个特征,使其范围映射到零到一之间的范围。如果数据中存在异常值,它们可能会将其偏向最小值或最大值,从而导致具有较大边缘异常值的数据分布完全不同:所有非异常值都可能因此而几乎完全坍缩在一起。
我们还评估了根本没有预处理(通过向管道传递None),StandardScaler和SplineTransformer。有关更多详细信息,请参阅其各自的文档。
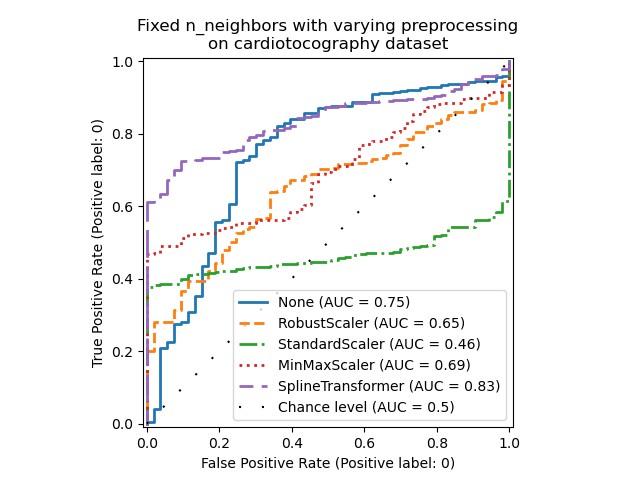
请注意,最佳预处理取决于数据集,如下所示。
X = X_cardiotocography
y = y_true["cardiotocography"]
n_samples, expected_anomaly_fraction = X.shape[0], 0.025
lof = LocalOutlierFactor(n_neighbors=int(n_samples * expected_anomaly_fraction))
fig, ax = plt.subplots()
for model_idx, (linestyle, preprocessor) in enumerate(
zip(linestyles, preprocessor_list)
):
model = make_pipeline(preprocessor, lof)
model.fit(X)
y_pred = model[-1].negative_outlier_factor_
display = RocCurveDisplay.from_predictions(
y,
y_pred,
pos_label=pos_label,
name=str(preprocessor).split("(")[0],
ax=ax,
plot_chance_level=(model_idx == len(preprocessor_list) - 1),
chance_level_kw={"linestyle": (0, (1, 10))},
linestyle=linestyle,
linewidth=2,
)
ax.set_title(
"Fixed n_neighbors with varying preprocessing\non cardiotocography dataset"
)
plt.show()
脚本总运行时间:(0 分钟 52.650 秒)
相关示例