注意
转到结尾 下载完整的示例代码。或通过 JupyterLite 或 Binder 在您的浏览器中运行此示例。
概率校准曲线#
在进行分类时,人们通常不仅希望预测类别标签,还希望预测相关的概率。此概率对预测提供某种程度的置信度。本示例演示了如何使用校准曲线(也称为可靠性图)来可视化预测概率的校准程度。还将演示未校准分类器的校准。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
数据集#
我们将使用一个包含 100,000 个样本和 20 个特征的合成二元分类数据集。在 20 个特征中,只有 2 个是有信息的,10 个是冗余的(信息特征的随机组合),其余 8 个是没有信息的(随机数)。在 100,000 个样本中,将有 1,000 个用于模型拟合,其余用于测试。
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(
n_samples=100_000, n_features=20, n_informative=2, n_redundant=10, random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.99, random_state=42
)
校准曲线#
高斯朴素贝叶斯#
首先,我们将比较
LogisticRegression(用作基线,因为通常情况下,由于使用了对数损失,适当正则化的逻辑回归默认情况下是经过良好校准的)未校准的
GaussianNBGaussianNB使用等距和 sigmoid 校准(参见 用户指南)
下面绘制了所有四种情况的校准曲线,其中 x 轴是每个 bin 的平均预测概率,y 轴是每个 bin 中正类别的分数。
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
from sklearn.calibration import CalibratedClassifierCV, CalibrationDisplay
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
lr = LogisticRegression(C=1.0)
gnb = GaussianNB()
gnb_isotonic = CalibratedClassifierCV(gnb, cv=2, method="isotonic")
gnb_sigmoid = CalibratedClassifierCV(gnb, cv=2, method="sigmoid")
clf_list = [
(lr, "Logistic"),
(gnb, "Naive Bayes"),
(gnb_isotonic, "Naive Bayes + Isotonic"),
(gnb_sigmoid, "Naive Bayes + Sigmoid"),
]
fig = plt.figure(figsize=(10, 10))
gs = GridSpec(4, 2)
colors = plt.get_cmap("Dark2")
ax_calibration_curve = fig.add_subplot(gs[:2, :2])
calibration_displays = {}
for i, (clf, name) in enumerate(clf_list):
clf.fit(X_train, y_train)
display = CalibrationDisplay.from_estimator(
clf,
X_test,
y_test,
n_bins=10,
name=name,
ax=ax_calibration_curve,
color=colors(i),
)
calibration_displays[name] = display
ax_calibration_curve.grid()
ax_calibration_curve.set_title("Calibration plots (Naive Bayes)")
# Add histogram
grid_positions = [(2, 0), (2, 1), (3, 0), (3, 1)]
for i, (_, name) in enumerate(clf_list):
row, col = grid_positions[i]
ax = fig.add_subplot(gs[row, col])
ax.hist(
calibration_displays[name].y_prob,
range=(0, 1),
bins=10,
label=name,
color=colors(i),
)
ax.set(title=name, xlabel="Mean predicted probability", ylabel="Count")
plt.tight_layout()
plt.show()
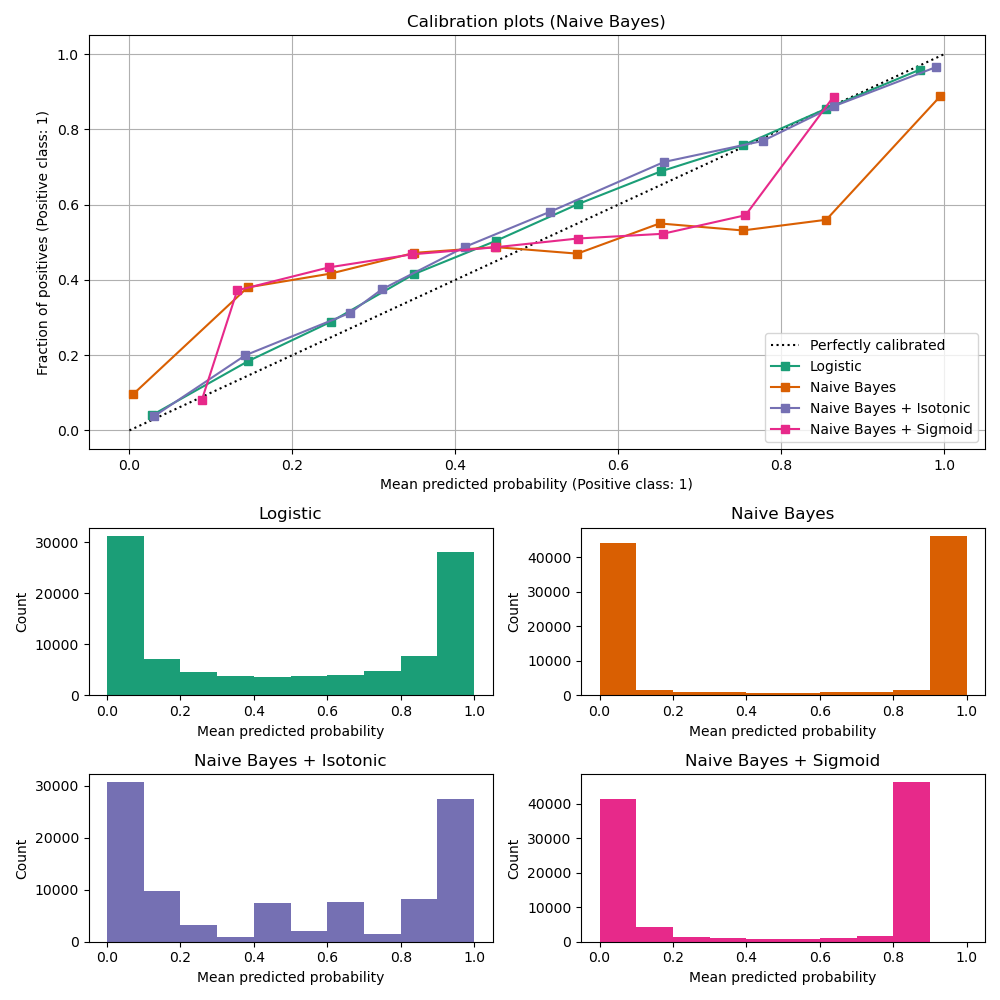
未校准的 GaussianNB 校准效果不佳,因为冗余特征违反了特征独立性的假设,导致分类器过于自信,这由典型的转置 sigmoid 曲线所示。使用 等距回归 对 GaussianNB 的概率进行校准可以解决这个问题,从接近对角线的校准曲线可以看出这一点。Sigmoid 回归 也略微提高了校准精度,尽管不如非参数等距回归强。这可以归因于我们拥有大量的校准数据,因此可以利用非参数模型的更大灵活性。
下面我们将进行定量分析,考虑几个分类指标:Brier 评分损失、对数损失、精确度、召回率、F1 分数 和 ROC AUC。
from collections import defaultdict
import pandas as pd
from sklearn.metrics import (
brier_score_loss,
f1_score,
log_loss,
precision_score,
recall_score,
roc_auc_score,
)
scores = defaultdict(list)
for i, (clf, name) in enumerate(clf_list):
clf.fit(X_train, y_train)
y_prob = clf.predict_proba(X_test)
y_pred = clf.predict(X_test)
scores["Classifier"].append(name)
for metric in [brier_score_loss, log_loss, roc_auc_score]:
score_name = metric.__name__.replace("_", " ").replace("score", "").capitalize()
scores[score_name].append(metric(y_test, y_prob[:, 1]))
for metric in [precision_score, recall_score, f1_score]:
score_name = metric.__name__.replace("_", " ").replace("score", "").capitalize()
scores[score_name].append(metric(y_test, y_pred))
score_df = pd.DataFrame(scores).set_index("Classifier")
score_df.round(decimals=3)
score_df
请注意,尽管校准改进了 Brier 评分损失(一个由校准项和细化项组成的指标)和 对数损失,但它并没有显著改变预测精度度量(精确度、召回率和 F1 分数)。这是因为校准不应显着改变决策阈值位置处的预测概率(在图上 x = 0.5 处)。但是,校准应该使预测概率更准确,因此对于在不确定性下做出分配决策更有用。此外,ROC AUC 根本不应该改变,因为校准是单调变换。实际上,没有排名指标会受到校准的影响。
线性支持向量机分类器#
接下来,我们将比较
未校准的
LinearSVC。由于 SVC 默认情况下不输出概率,因此我们通过应用最小-最大缩放将 decision_function 的输出简单地缩放为 [0, 1]。
import numpy as np
from sklearn.svm import LinearSVC
class NaivelyCalibratedLinearSVC(LinearSVC):
"""LinearSVC with `predict_proba` method that naively scales
`decision_function` output for binary classification."""
def fit(self, X, y):
super().fit(X, y)
df = self.decision_function(X)
self.df_min_ = df.min()
self.df_max_ = df.max()
def predict_proba(self, X):
"""Min-max scale output of `decision_function` to [0, 1]."""
df = self.decision_function(X)
calibrated_df = (df - self.df_min_) / (self.df_max_ - self.df_min_)
proba_pos_class = np.clip(calibrated_df, 0, 1)
proba_neg_class = 1 - proba_pos_class
proba = np.c_[proba_neg_class, proba_pos_class]
return proba
lr = LogisticRegression(C=1.0)
svc = NaivelyCalibratedLinearSVC(max_iter=10_000)
svc_isotonic = CalibratedClassifierCV(svc, cv=2, method="isotonic")
svc_sigmoid = CalibratedClassifierCV(svc, cv=2, method="sigmoid")
clf_list = [
(lr, "Logistic"),
(svc, "SVC"),
(svc_isotonic, "SVC + Isotonic"),
(svc_sigmoid, "SVC + Sigmoid"),
]
fig = plt.figure(figsize=(10, 10))
gs = GridSpec(4, 2)
ax_calibration_curve = fig.add_subplot(gs[:2, :2])
calibration_displays = {}
for i, (clf, name) in enumerate(clf_list):
clf.fit(X_train, y_train)
display = CalibrationDisplay.from_estimator(
clf,
X_test,
y_test,
n_bins=10,
name=name,
ax=ax_calibration_curve,
color=colors(i),
)
calibration_displays[name] = display
ax_calibration_curve.grid()
ax_calibration_curve.set_title("Calibration plots (SVC)")
# Add histogram
grid_positions = [(2, 0), (2, 1), (3, 0), (3, 1)]
for i, (_, name) in enumerate(clf_list):
row, col = grid_positions[i]
ax = fig.add_subplot(gs[row, col])
ax.hist(
calibration_displays[name].y_prob,
range=(0, 1),
bins=10,
label=name,
color=colors(i),
)
ax.set(title=name, xlabel="Mean predicted probability", ylabel="Count")
plt.tight_layout()
plt.show()
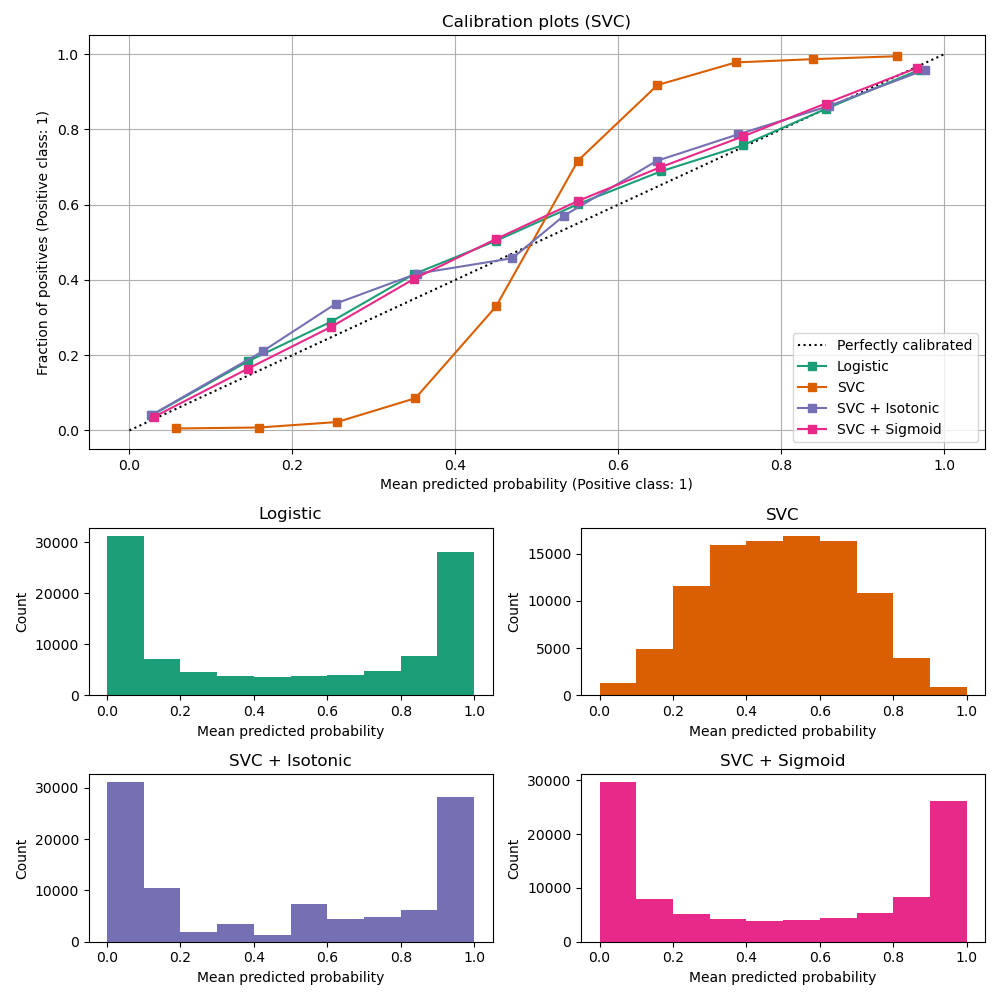
与GaussianNB表现相反,LinearSVC的校准曲线呈S形,这通常是欠自信分类器的特征。对于LinearSVC,这是由铰链损失的边缘属性引起的,该属性侧重于靠近决策边界的样本(支持向量)。远离决策边界的样本不会影响铰链损失。因此,LinearSVC不尝试分离高置信度区域中的样本是合理的。这导致在0和1附近校准曲线更平坦,并且在Niculescu-Mizil & Caruana[1]中使用各种数据集进行了实证证明。
两种校准方法(S形和等距)都可以解决这个问题,并产生类似的结果。
和前面一样,我们展示了Brier评分损失、对数损失、精确率、召回率、F1分数和ROC AUC。
scores = defaultdict(list)
for i, (clf, name) in enumerate(clf_list):
clf.fit(X_train, y_train)
y_prob = clf.predict_proba(X_test)
y_pred = clf.predict(X_test)
scores["Classifier"].append(name)
for metric in [brier_score_loss, log_loss, roc_auc_score]:
score_name = metric.__name__.replace("_", " ").replace("score", "").capitalize()
scores[score_name].append(metric(y_test, y_prob[:, 1]))
for metric in [precision_score, recall_score, f1_score]:
score_name = metric.__name__.replace("_", " ").replace("score", "").capitalize()
scores[score_name].append(metric(y_test, y_pred))
score_df = pd.DataFrame(scores).set_index("Classifier")
score_df.round(decimals=3)
score_df
与上面的GaussianNB一样,校准提高了Brier评分损失和对数损失,但并没有显著改变预测精度指标(精确率、召回率和F1分数)。
总结#
参数化S形校准可以处理基分类器的校准曲线为S形的情况(例如,对于LinearSVC),但不能处理其为反S形的情况(例如,GaussianNB)。非参数等距校准可以处理这两种情况,但可能需要更多数据才能产生良好的结果。
参考文献#
脚本总运行时间:(0分钟2.241秒)
相关示例