注意
转到结尾 下载完整的示例代码。或者通过JupyterLite或Binder在您的浏览器中运行此示例。
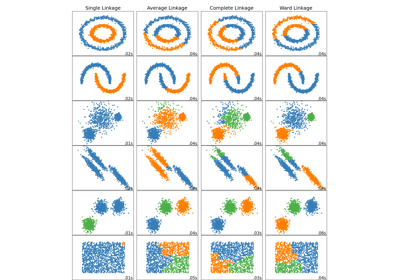
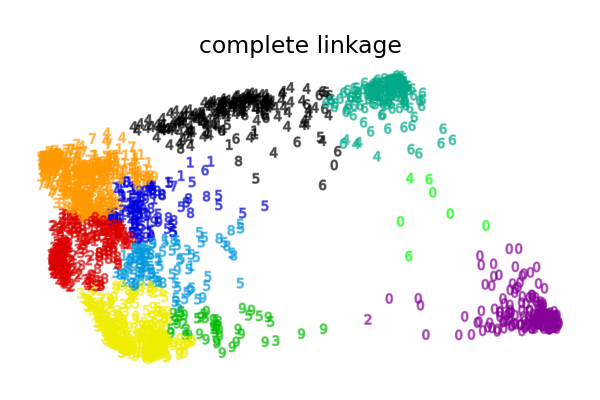
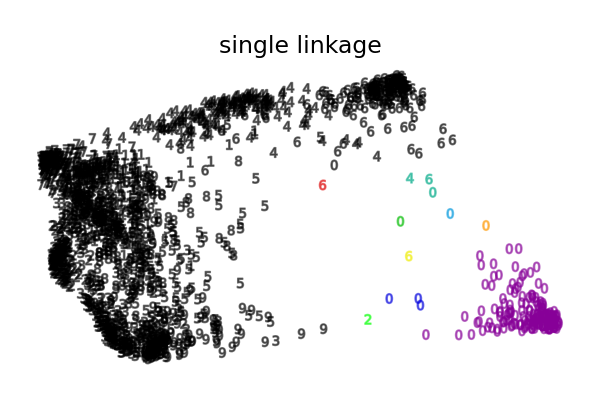
数字二维嵌入上的各种凝聚层次聚类#
此示例说明了在数字数据集的二维嵌入上进行凝聚层次聚类的各种链接选项。
本示例的目标是直观地展示这些指标的行为,而不是为数字找到良好的聚类。这就是为什么本示例在二维嵌入上进行。
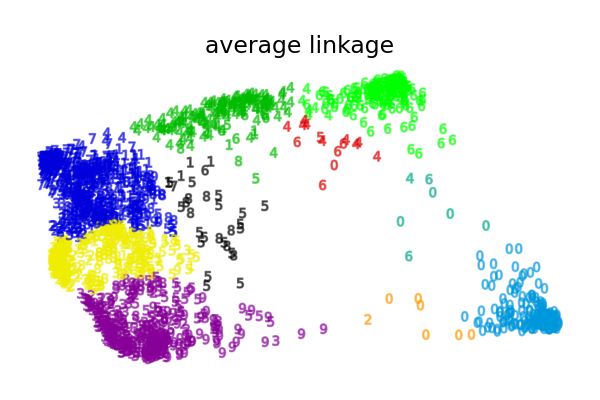
本示例向我们展示了凝聚层次聚类的“富者愈富”行为,这种行为往往会产生大小不一的聚类。
这种行为在平均连接策略中尤为明显,最终会产生几个包含少量数据点的聚类。
单连接的情况更具病理性,一个非常大的聚类覆盖了大多数数字,一个中等大小(干净)的聚类包含大部分数字0,所有其他聚类都来自边缘周围的噪声点。
其他连接策略导致更均匀分布的聚类,因此不太可能对数据集的随机重采样敏感。

Computing embedding
Done.
ward : 0.06s
average : 0.05s
complete : 0.05s
single : 0.02s
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
from time import time
import numpy as np
from matplotlib import pyplot as plt
from sklearn import datasets, manifold
digits = datasets.load_digits()
X, y = digits.data, digits.target
n_samples, n_features = X.shape
np.random.seed(0)
# ----------------------------------------------------------------------
# Visualize the clustering
def plot_clustering(X_red, labels, title=None):
x_min, x_max = np.min(X_red, axis=0), np.max(X_red, axis=0)
X_red = (X_red - x_min) / (x_max - x_min)
plt.figure(figsize=(6, 4))
for digit in digits.target_names:
plt.scatter(
*X_red[y == digit].T,
marker=f"${digit}$",
s=50,
c=plt.cm.nipy_spectral(labels[y == digit] / 10),
alpha=0.5,
)
plt.xticks([])
plt.yticks([])
if title is not None:
plt.title(title, size=17)
plt.axis("off")
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
# ----------------------------------------------------------------------
# 2D embedding of the digits dataset
print("Computing embedding")
X_red = manifold.SpectralEmbedding(n_components=2).fit_transform(X)
print("Done.")
from sklearn.cluster import AgglomerativeClustering
for linkage in ("ward", "average", "complete", "single"):
clustering = AgglomerativeClustering(linkage=linkage, n_clusters=10)
t0 = time()
clustering.fit(X_red)
print("%s :\t%.2fs" % (linkage, time() - t0))
plot_clustering(X_red, clustering.labels_, "%s linkage" % linkage)
plt.show()
脚本总运行时间:(0分钟1.583秒)
相关示例