注意
转到末尾 下载完整的示例代码。或者通过 JupyterLite 或 Binder 在您的浏览器中运行此示例
递归特征消除#
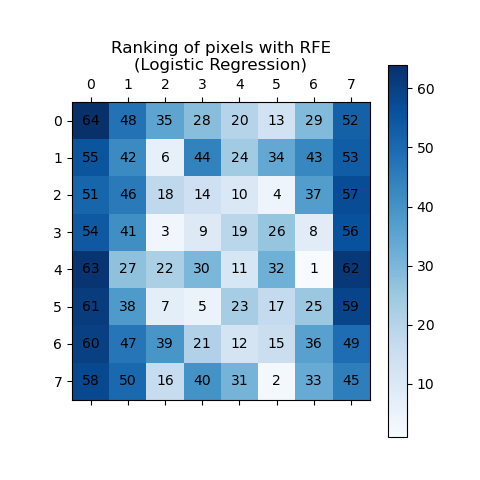
此示例演示如何使用递归特征消除(RFE)来确定各个像素对分类手写数字的重要性。RFE 递归地移除最不重要的特征,根据其重要性分配等级,其中较高的 ranking_ 值表示较低的重要性。为了清晰起见,使用蓝色阴影和像素注释来可视化等级。正如预期的那样,图像中心位置的像素往往比边缘附近的像素更具预测性。
注意
另请参见 带交叉验证的递归特征消除
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
# Load the digits dataset
digits = load_digits()
X = digits.images.reshape((len(digits.images), -1))
y = digits.target
pipe = Pipeline(
[
("scaler", MinMaxScaler()),
("rfe", RFE(estimator=LogisticRegression(), n_features_to_select=1, step=1)),
]
)
pipe.fit(X, y)
ranking = pipe.named_steps["rfe"].ranking_.reshape(digits.images[0].shape)
# Plot pixel ranking
plt.matshow(ranking, cmap=plt.cm.Blues)
# Add annotations for pixel numbers
for i in range(ranking.shape[0]):
for j in range(ranking.shape[1]):
plt.text(j, i, str(ranking[i, j]), ha="center", va="center", color="black")
plt.colorbar()
plt.title("Ranking of pixels with RFE\n(Logistic Regression)")
plt.show()
脚本总运行时间:(0 分钟 3.104 秒)
相关示例