2.3. 聚类#
可以使用模块 sklearn.cluster 对未标记数据进行聚类。
每个聚类算法都有两种变体:一个类,它实现 fit 方法来学习训练数据的聚类;一个函数,它在给定训练数据的情况下,返回一个整数标签数组,对应于不同的聚类。对于类,训练数据的标签可以在 labels_ 属性中找到。
2.3.1. 聚类方法概述#
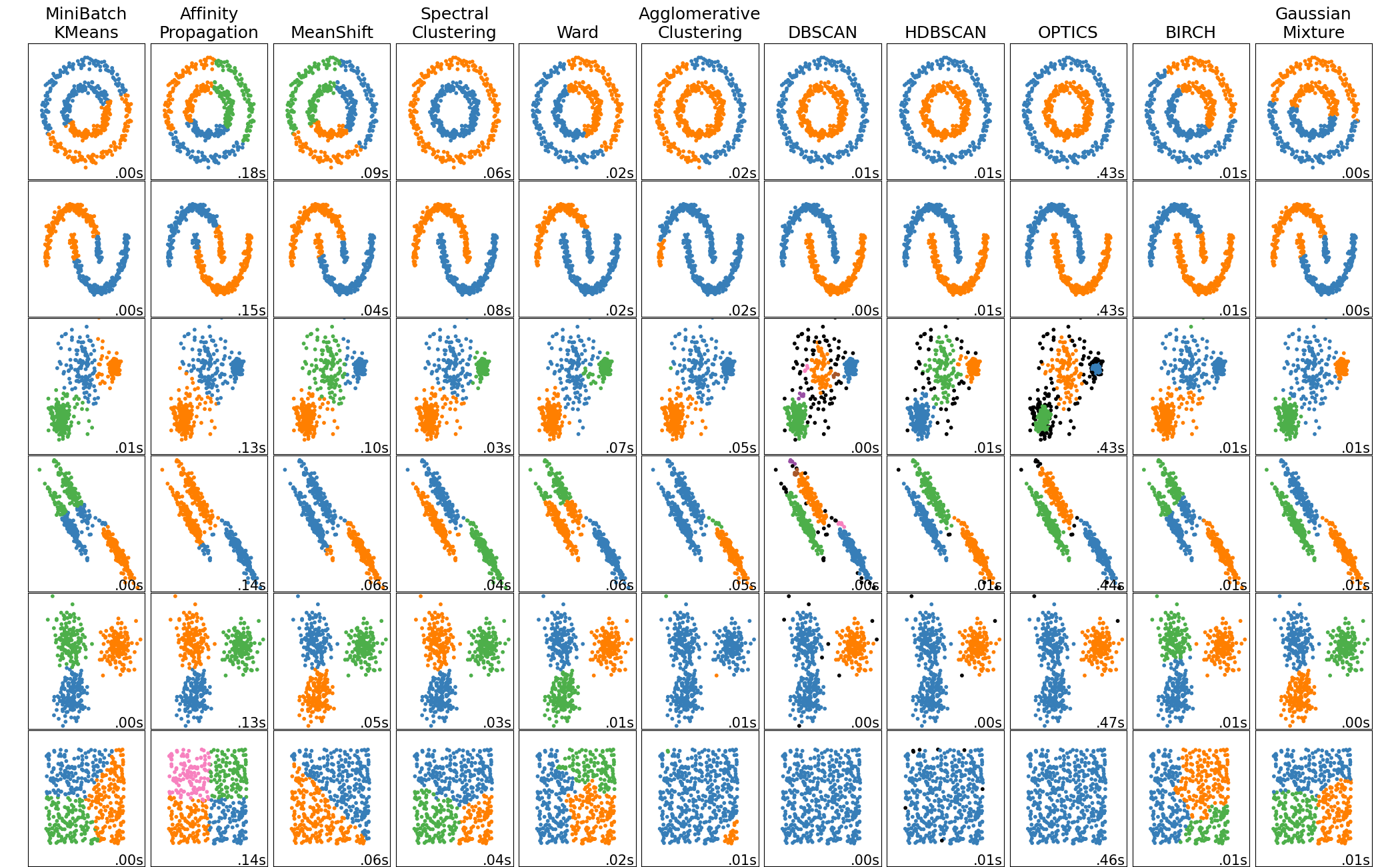
scikit-learn 中聚类算法的比较#
方法名称 |
参数 |
可扩展性 |
用例 |
几何形状(使用的度量) |
|---|---|---|---|---|
聚类数量 |
非常大的 |
通用用途,均匀的簇大小,平面几何形状,不是太多簇,归纳式 |
点之间的距离 |
|
阻尼系数,样本偏好 |
n_samples 情况下不可扩展 |
许多簇,簇大小不均匀,非平面几何形状,归纳式 |
图距离(例如,最近邻图) |
|
带宽 |
n_samples 情况下不可扩展 |
许多簇,簇大小不均匀,非平面几何形状,归纳式 |
点之间的距离 |
|
聚类数量 |
中等 |
少量簇,均匀的簇大小,非平面几何形状,转导式 |
图距离(例如,最近邻图) |
|
聚类数量或距离阈值 |
大的 |
许多簇,可能存在连接约束,转导式 |
点之间的距离 |
|
聚类数量或距离阈值、链接类型、距离 |
大的 |
许多簇,可能存在连接约束,非欧几里得距离,转导式 |
任何成对距离 |
|
邻域大小 |
非常大的 |
非平面几何形状,簇大小不均匀,异常值去除,转导式 |
最近点之间的距离 |
|
最小簇成员数,最小点邻居数 |
大的 |
非平面几何形状,簇大小不均匀,异常值去除,转导式,层次式,可变簇密度 |
最近点之间的距离 |
|
最小簇成员数 |
非常大的 |
非平面几何形状,簇大小不均匀,可变簇密度,异常值去除,转导式 |
点之间的距离 |
|
许多 |
不可扩展 |
平面几何形状,适合密度估计,归纳式 |
到中心的马氏距离 |
|
分支因子,阈值,可选全局聚类器。 |
较大的 |
大型数据集,异常值去除,数据降维,归纳法 |
点之间的欧几里得距离 |
|
聚类数量 |
非常大的 |
通用型,簇大小均匀,平面几何,无空簇,归纳法,层次聚类 |
点之间的距离 |
当簇具有特定形状(例如非平面流形)且标准欧几里得距离不是合适的度量时,非平面几何聚类非常有用。这种情况出现在上图的前两行。
高斯混合模型常用于聚类,在文档的另一章节(专门介绍混合模型)中进行了描述。K均值可以看作是每个分量具有相等协方差的高斯混合模型的特例。
2.3.2. K均值算法#
KMeans算法通过尝试将样本分成n个方差相等的组来聚类数据,从而最小化一个称为*惯性*或簇内平方和(见下文)的标准。此算法要求指定簇的数量。它可以很好地扩展到大量样本,并且已在许多不同领域的广泛应用领域中使用。
K均值算法将一组\(N\)个样本\(X\)划分为\(K\)个不相交的簇\(C\),每个簇由簇中样本的均值\(\mu_j\)描述。这些均值通常被称为簇“质心”;需要注意的是,它们通常不是来自\(X\)的点,尽管它们位于相同的空间中。
K均值算法旨在选择使**惯性**或**簇内平方和准则**最小化的质心
惯性可以被认为是衡量簇内部一致性的指标。它有一些缺点
惯性假设簇是凸的且各向同性的,但情况并非总是如此。它对细长的簇或形状不规则的流形响应不佳。
惯性不是归一化度量:我们只知道较低的值更好,零是最优的。但在非常高维的空间中,欧几里得距离往往会膨胀(这是所谓的“维度灾难”的一个例子)。在k均值聚类之前运行降维算法,例如主成分分析 (PCA),可以减轻这个问题并加快计算速度。
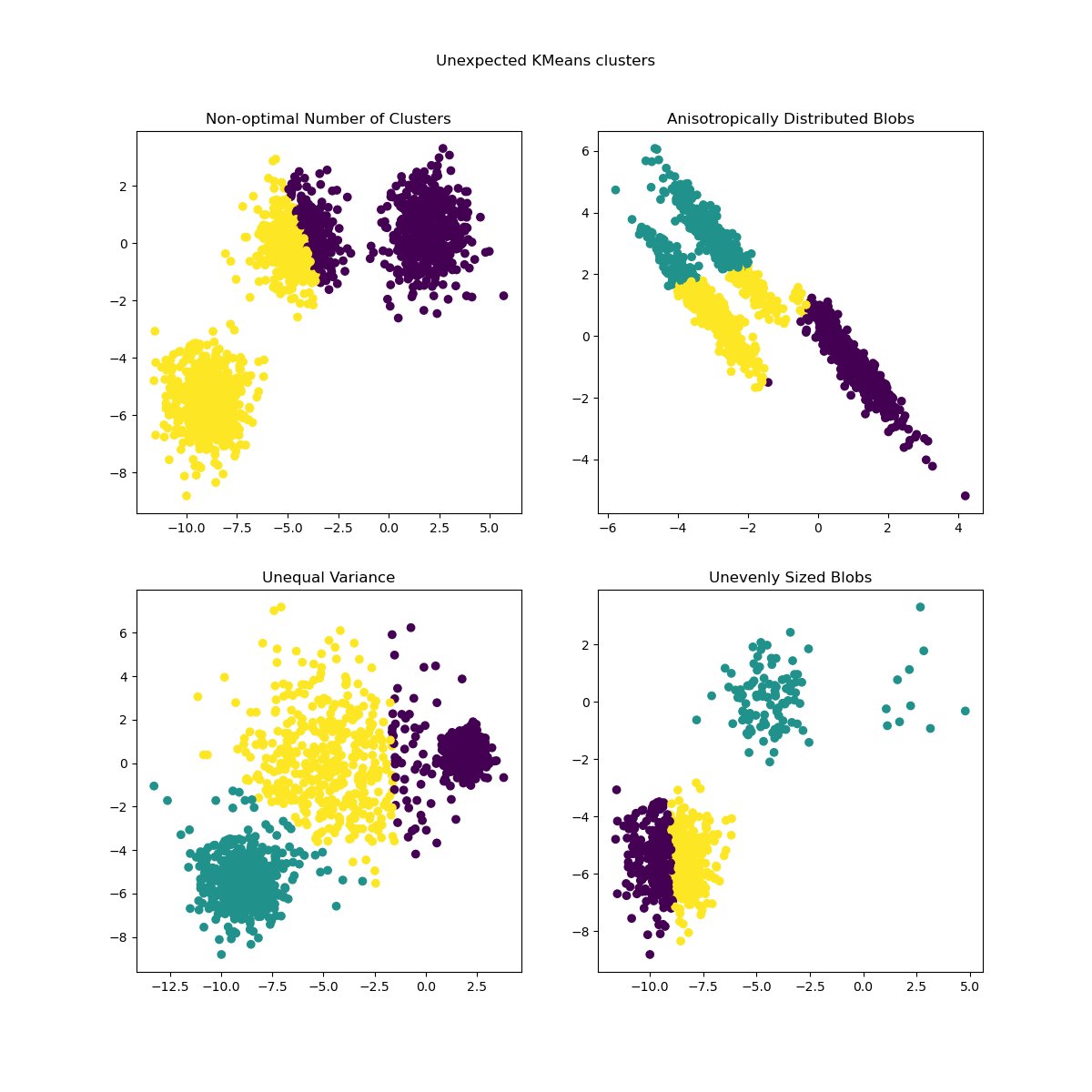
有关上述问题的更详细描述以及如何解决这些问题,请参阅示例K均值算法假设的演示和使用轮廓分析选择K均值聚类中的簇数。
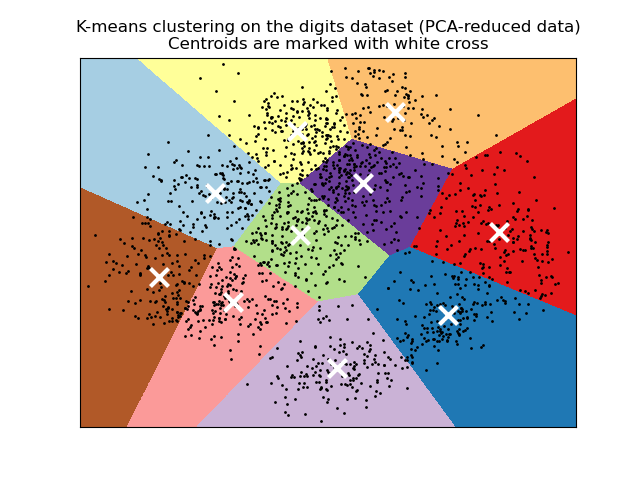
K均值算法通常被称为劳埃德算法。简单来说,该算法有三个步骤。第一步选择初始质心,最基本的方法是从数据集\(X\)中选择\(k\)个样本。初始化后,K均值算法包括在另外两个步骤之间循环。第一步将每个样本分配给与其最近的质心。第二步通过取分配给每个先前质心的所有样本的平均值来创建新的质心。计算旧质心和新质心之间的差异,并且算法重复最后两个步骤,直到该值小于阈值。换句话说,它重复直到质心不再显著移动。
K均值算法等价于具有小的、全相等的对角协方差矩阵的期望最大化算法。
该算法也可以通过Voronoi图的概念来理解。首先使用当前质心计算点的Voronoi图。Voronoi图中的每个段都成为一个单独的簇。其次,将质心更新为每个段的均值。然后算法重复此过程,直到满足停止条件。通常,当目标函数在迭代之间的相对减少小于给定的容差值时,算法停止。在本实现中并非如此:当质心的移动小于容差时,迭代停止。
如果给定足够的时间,K均值算法将始终收敛,但是这可能是局部最小值。这高度依赖于质心的初始化。因此,计算通常会进行多次,并使用不同的质心初始化。一种帮助解决此问题的方法是k-means++初始化方案,该方案已在scikit-learn中实现(使用init='k-means++'参数)。这将质心初始化为(通常)彼此远离,从而可能比随机初始化产生更好的结果,如参考中所示。有关比较不同初始化方案的详细示例,请参阅手写数字数据上的K均值聚类演示。
K-means++也可以独立调用来为其他聚类算法选择种子,详情和示例用法请参见sklearn.cluster.kmeans_plusplus。
该算法支持样本权重,可以通过参数sample_weight给出。这允许在计算簇中心和惯性值时为某些样本分配更大的权重。例如,为样本分配权重2等效于将该样本的副本添加到数据集\(X\)中。
示例
使用K均值算法对文本文档进行聚类:基于稀疏数据的
KMeans和MiniBatchKMeans的文本文档聚类K-means++初始化示例:使用K-means++为其他聚类算法选择种子。
2.3.2.1. 低级并行化#
基于 Cython 的 OpenMP 并行处理使 KMeans 获益良多。少量数据(256 个样本)会并行处理,这也有助于降低内存占用。有关如何控制线程数量的更多详细信息,请参阅我们的 并行处理 说明。
示例
K 均值假设演示:演示 K 均值何时直观有效,何时无效。
K 均值聚类在手写数字数据上的演示:手写数字聚类。
参考文献#
“k-means++:仔细播种的优势” Arthur,David 和 Sergei Vassilvitskii,《第十八届年度 ACM-SIAM 离散算法研讨会论文集》,工业与应用数学学会 (2007)
2.3.2.2. Mini Batch K 均值#
MiniBatchKMeans 是 KMeans 算法的一个变体,它使用小批量来减少计算时间,同时仍然尝试优化相同的目标函数。小批量是输入数据的子集,在每次训练迭代中随机抽取。这些小批量大大减少了收敛到局部解所需的计算量。与其他减少 K 均值收敛时间的算法相比,小批量 K 均值产生的结果通常只比标准算法略差。
该算法迭代两个主要步骤,类似于普通 K 均值。第一步,从数据集中随机抽取 \(b\) 个样本,形成一个小批量。然后将其分配给最近的质心。第二步,更新质心。与 K 均值相比,这是基于每个样本进行的。对于小批量中的每个样本,通过取样本及其之前分配给该质心的所有样本的流平均值来更新分配的质心。这具有随着时间的推移降低质心变化率的效果。重复这些步骤,直到收敛或达到预定的迭代次数。
MiniBatchKMeans 的收敛速度快于 KMeans,但结果质量会降低。实际上,正如示例和引用的参考文献所示,这种质量差异可能非常小。
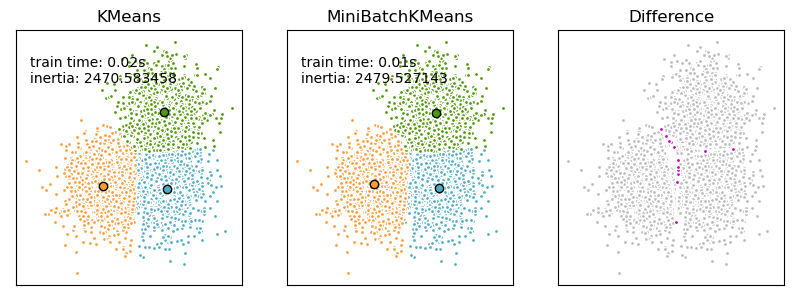
示例
使用K均值算法对文本文档进行聚类:基于稀疏数据的
KMeans和MiniBatchKMeans的文本文档聚类
参考文献#
“Web 规模 K 均值聚类” D. Sculley,《第 19 届国际万维网会议论文集》(2010)
2.3.3. 亲和传播#
AffinityPropagation 通过在样本对之间发送消息直到收敛来创建聚类。然后使用少量示例来描述数据集,这些示例被识别为最能代表其他样本的示例。样本对之间发送的消息表示一个样本成为另一个样本示例的适用性,这会根据其他样本对的值进行更新。此更新会迭代进行,直到收敛,此时选择最终示例,从而给出最终聚类。
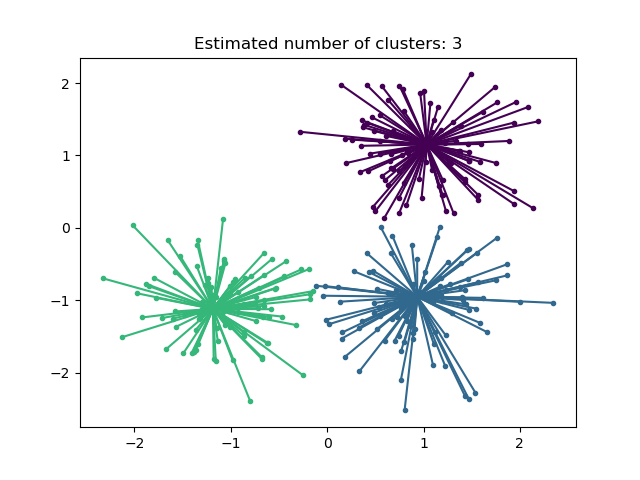
亲和传播很有趣,因为它根据提供的数据选择聚类的数量。为此,两个重要的参数是 *preference*(控制使用的示例数量)和 *damping factor*(抑制责任和可用性消息以避免更新这些消息时的数值振荡)。
亲和传播的主要缺点是其复杂性。该算法的时间复杂度为 \(O(N^2 T)\) 数量级,其中 \(N\) 是样本数,\(T\) 是直到收敛的迭代次数。此外,如果使用密集相似性矩阵,则内存复杂度为 \(O(N^2)\) 数量级,但如果使用稀疏相似性矩阵,则可以降低。这使得亲和传播最适合小型到中型数据集。
算法描述#
点之间发送的消息属于两类。第一类是责任\(r(i, k)\),它代表样本\(k\) 作为样本\(i\) 的示例的累积证据。第二类是可用性\(a(i, k)\),它代表样本\(i\) 选择样本\(k\) 作为其示例的累积证据,并考虑了\(k\) 应作为其他所有样本的示例的值。通过这种方式,如果样本 (1) 与许多样本足够相似,并且 (2) 被许多样本选择为自身的代表,则样本会选择示例。
更正式地说,样本\(k\) 作为样本\(i\) 的示例的责任由下式给出:
其中\(s(i, k)\) 是样本\(i\) 和\(k\) 之间的相似度。样本\(k\) 作为样本\(i\) 的示例的可用性由下式给出:
首先,\(r\) 和\(a\) 的所有值都设置为零,并且每个迭代的计算都持续到收敛。如上所述,为了避免更新消息时出现数值振荡,将阻尼因子\(\lambda\) 引入迭代过程:
其中\(t\) 表示迭代次数。
示例
亲和传播聚类算法演示:在具有 3 个类别的合成二维数据集上进行亲和传播。
可视化股票市场结构:在金融时间序列上使用亲和传播来查找公司群体。
2.3.4. 均值漂移#
MeanShift 聚类旨在发现样本平滑密度中的 *团块*。它是一种基于质心的算法,其工作原理是将质心的候选值更新为给定区域内点的均值。然后在后处理阶段过滤这些候选值以消除接近重复的值,从而形成最终的质心集。
数学细节#
使用称为爬山法的技术迭代调整质心候选的位置,该技术查找估计概率密度的局部最大值。对于迭代\(t\) 的质心候选\(x\),根据以下等式更新候选:
其中\(m\) 是为每个质心计算的 *均值漂移* 向量,该向量指向点密度最大增加的区域。为了计算\(m\),我们将\(N(x)\) 定义为在\(x\) 周围给定距离内的样本邻域。然后使用以下等式计算\(m\),有效地将质心更新为其邻域内样本的均值:
通常,\(m\) 的等式取决于用于密度估计的核。通用公式是:
在我们的实现中,如果\(x\) 足够小,则\(K(x)\) 等于 1,否则等于 0。有效地,\(K(y - x)\) 指示\(y\) 是否在\(x\) 的邻域内。
该算法自动设置聚类数量,而不是依赖于参数bandwidth,该参数决定了搜索区域的大小。可以手动设置此参数,但可以使用提供的estimate_bandwidth 函数进行估计,如果未设置带宽,则会调用此函数。
该算法的可扩展性不高,因为它在算法执行过程中需要多次最近邻搜索。该算法保证收敛,但是当质心的变化很小时,算法将停止迭代。
通过为给定样本查找最近的质心来标记新样本。
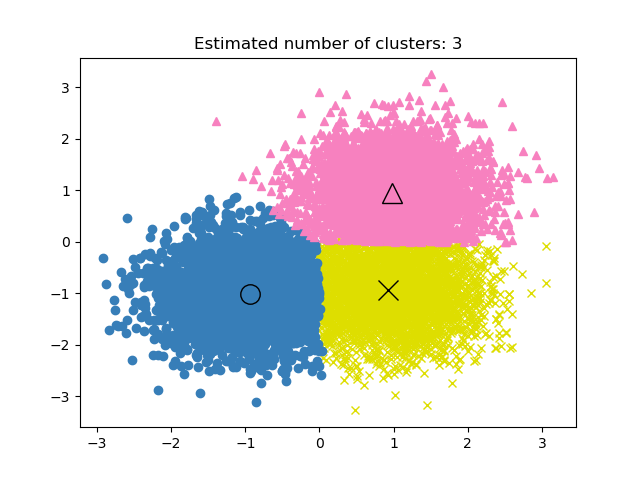
示例
均值漂移聚类算法演示:在具有 3 个类别的合成二维数据集上进行均值漂移聚类。
参考文献#
“均值漂移:一种强大的特征空间分析方法” D. Comaniciu 和 P. Meer,*IEEE 模式分析与机器智能汇刊* (2002)
2.3.5. 谱聚类#
SpectralClustering 对样本之间的亲和矩阵进行低维嵌入,然后对低维空间中特征向量的分量进行聚类(例如,通过 KMeans)。如果亲和矩阵是稀疏的并且使用 amg 求解器来解决特征值问题,则它在计算上特别高效(注意,amg 求解器需要安装 pyamg 模块)。
当前版本的 SpectralClustering 需要预先指定聚类数量。它适用于少量聚类,但不建议用于大量聚类。
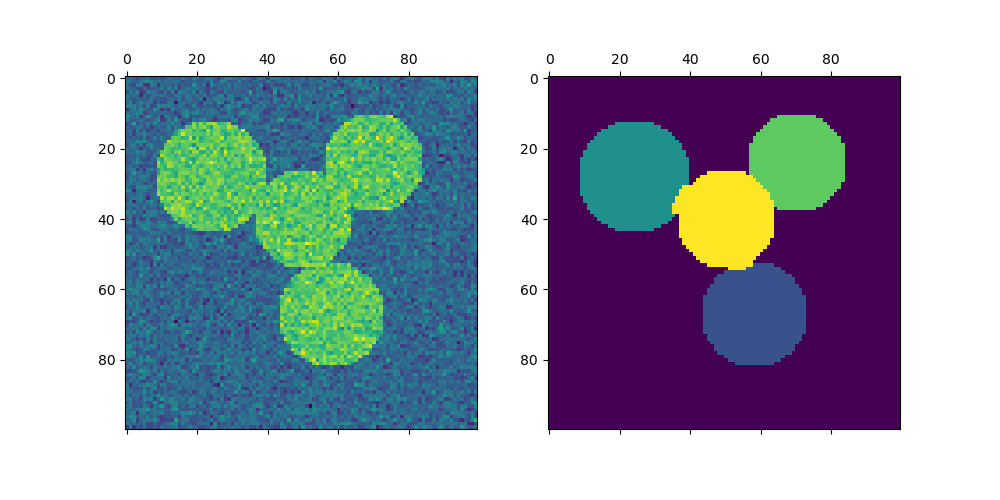
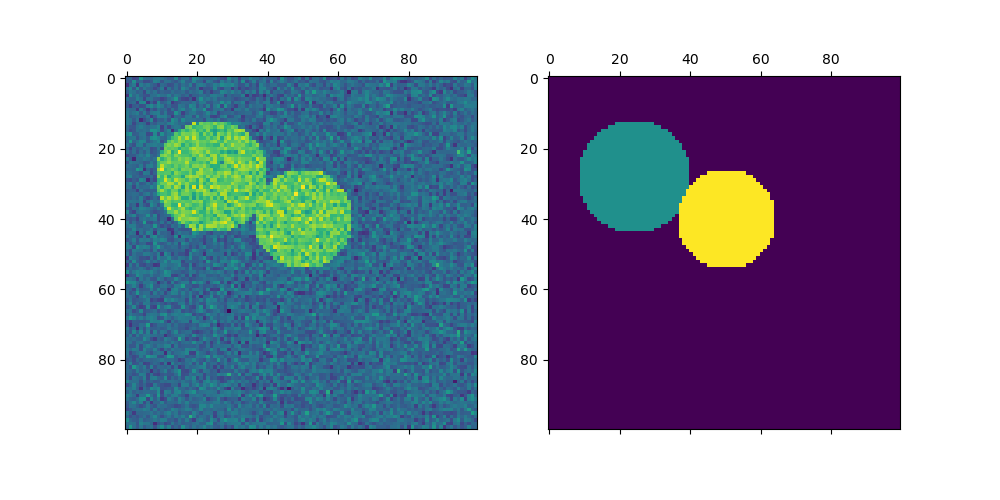
对于两个集群,谱聚类解决了相似图上归一化割问题的凸松弛问题:将图分成两部分,使得被切割边的权重与每个集群内部边的权重相比很小。当处理图像时,此标准尤其重要,其中图顶点是像素,相似图的边的权重使用图像梯度的函数计算。
警告
将距离转换为良好的相似性
请注意,如果相似矩阵的值分布不佳,例如存在负值或距离矩阵而不是相似性矩阵,则谱问题将是奇异的,问题无法求解。在这种情况下,建议对矩阵的条目应用变换。例如,在带符号距离矩阵的情况下,通常应用热核。
similarity = np.exp(-beta * distance / distance.std())
有关此类应用的示例,请参见示例。
示例
用于图像分割的谱聚类:使用谱聚类从噪声背景中分割对象。
将希腊硬币图片分割成区域:谱聚类将硬币图像分割成区域。
2.3.5.1. 不同的标签分配策略#
可以使用不同的标签分配策略,对应于SpectralClustering的assign_labels参数。"kmeans"策略可以匹配更精细的细节,但可能不稳定。特别是,除非控制random_state,否则它可能在每次运行时不可重现,因为它取决于随机初始化。另一种"discretize"策略是100%可重现的,但往往会创建形状相当均匀和几何的区域。最近添加的"cluster_qr"选项是一种确定性替代方案,它往往会在下面的示例应用程序中创建视觉上最佳的划分。
|
|
|
|---|---|---|
|
|
|



参考文献#
“多类谱聚类” Stella X. Yu,Jianbo Shi,2003
“简单、直接且高效的多路谱聚类” Anil Damle,Victor Minden,Lexing Ying,2019
2.3.5.2. 谱聚类图#
谱聚类也可用于通过其谱嵌入来划分图。在这种情况下,亲和矩阵是图的邻接矩阵,并且谱聚类以affinity='precomputed'初始化。
>>> from sklearn.cluster import SpectralClustering
>>> sc = SpectralClustering(3, affinity='precomputed', n_init=100,
... assign_labels='discretize')
>>> sc.fit_predict(adjacency_matrix)
参考文献#
“谱聚类教程” Ulrike von Luxburg,2007
“归一化割和图像分割” Jianbo Shi,Jitendra Malik,2000
“谱分割的随机游走视图” Marina Meila,Jianbo Shi,2001
“关于谱聚类:分析和算法” Andrew Y. Ng,Michael I. Jordan,Yair Weiss,2001
“用于随机块划分流图挑战的预处理谱聚类” David Zhuzhunashvili,Andrew Knyazev
2.3.6. 层次聚类#
层次聚类是一类通用的聚类算法,它通过连续合并或分割聚类来构建嵌套聚类。这种聚类层次结构表示为树(或树状图)。树的根是包含所有样本的唯一集群,叶子是只有一个样本的集群。有关更多详细信息,请参见维基百科页面。
AgglomerativeClustering对象使用自下而上的方法执行层次聚类:每个观测值都从属于它自己的集群,并且集群会连续合并在一起。连接标准决定用于合并策略的度量。
**Ward**最小化所有集群内平方差之和。这是一种最小化方差的方法,从这个意义上说,它类似于k-means目标函数,但采用凝聚层次方法。
**最大**或**完全连接**最小化成对集群观测值之间的最大距离。
**平均连接**最小化成对集群所有观测值之间距离的平均值。
**单连接**最小化成对集群最接近的观测值之间的距离。
AgglomerativeClustering与连接矩阵一起使用时也可以扩展到大量样本,但在样本之间没有添加连接约束时计算成本很高:它在每一步都考虑所有可能的合并。
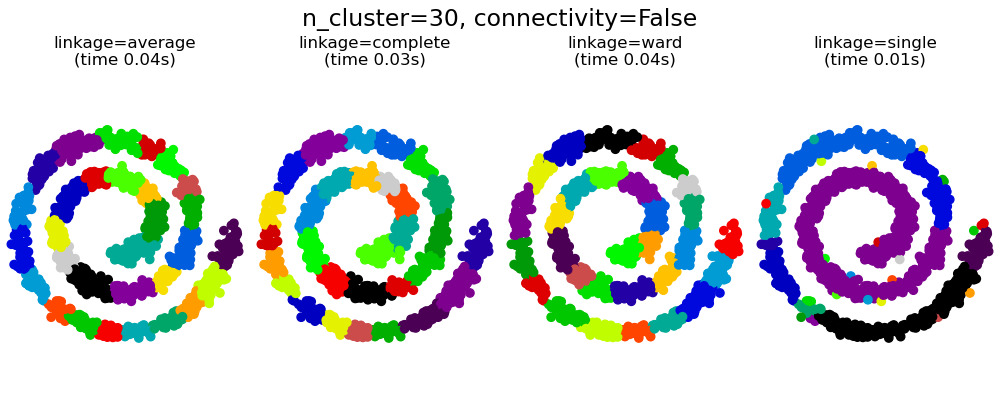
2.3.6.1. 不同的连接类型:Ward、complete、average 和 single linkage#
AgglomerativeClustering 支持 Ward、single、average 和 complete 连接策略。
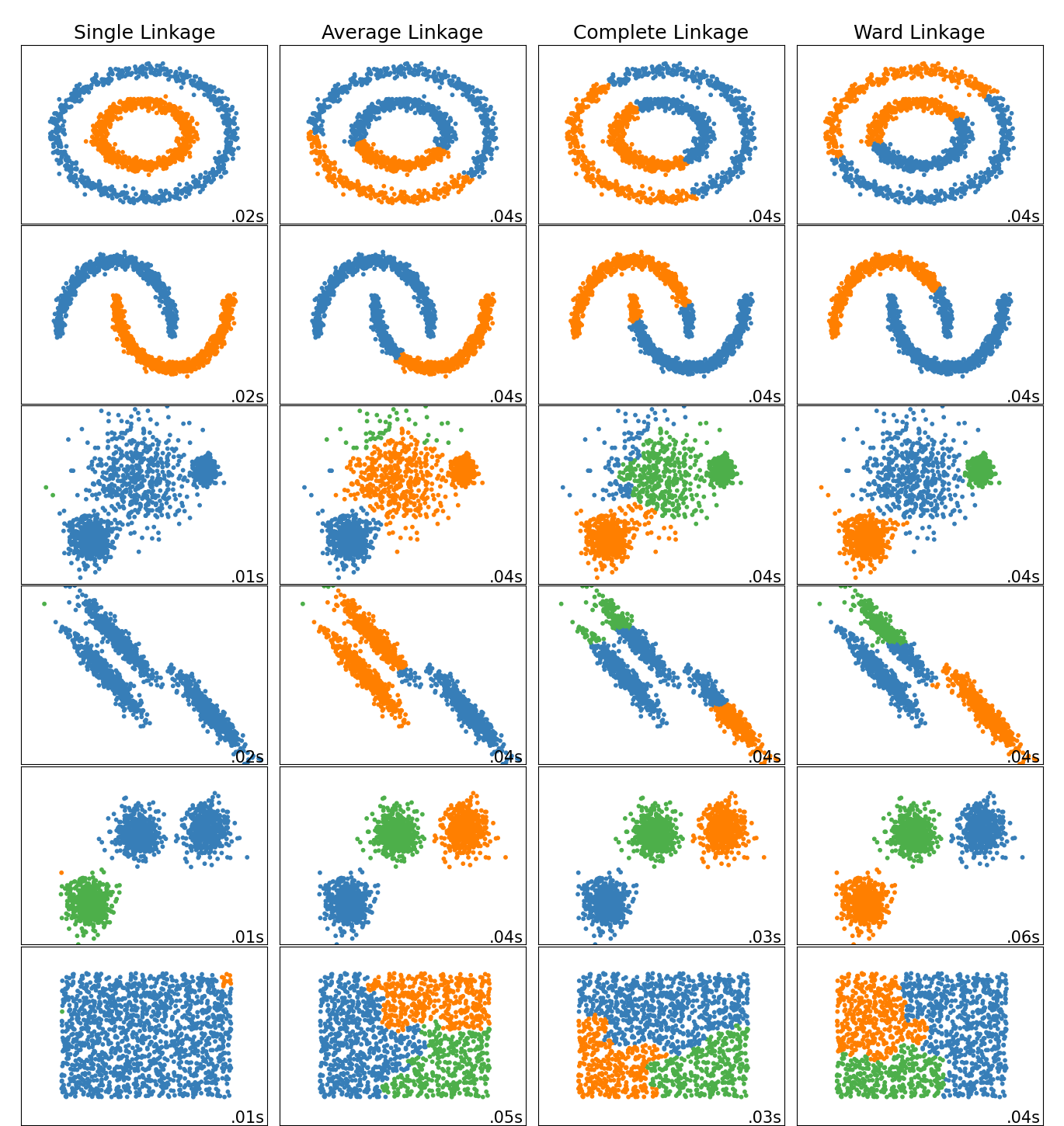
凝聚聚类具有“富者越富”的行为,导致聚类大小不均匀。在这方面,single linkage是最差的策略,而 Ward 则提供了最规则的大小。但是,Ward方法不能改变亲和度(或聚类中使用的距离),因此对于非欧几里得度量,average linkage是一个不错的替代方案。Single linkage虽然对噪声数据不鲁棒,但计算效率非常高,因此可用于提供更大数据集的层次聚类。Single linkage在非球形数据上也能表现良好。
示例
数字二维嵌入上的各种凝聚聚类:在真实数据集上探索不同的连接策略。
比较玩具数据集上不同的层次连接方法:在玩具数据集上探索不同的连接策略。
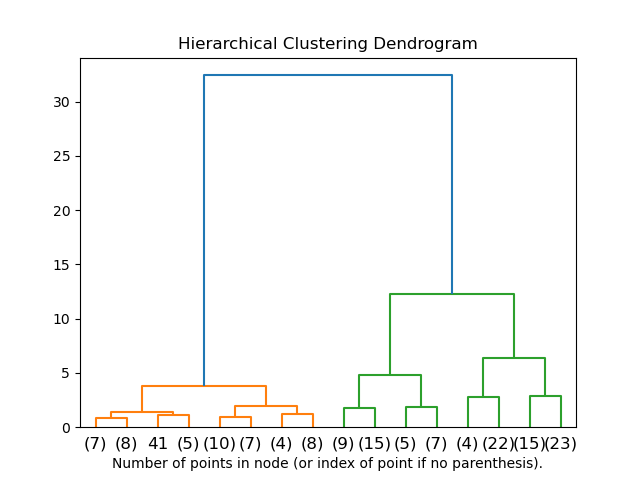
2.3.6.2. 聚类层次的可视化#
可以将表示聚类层次合并的树可视化为树状图。目视检查通常有助于理解数据的结构,但在样本量较小的情况下更为有效。
示例
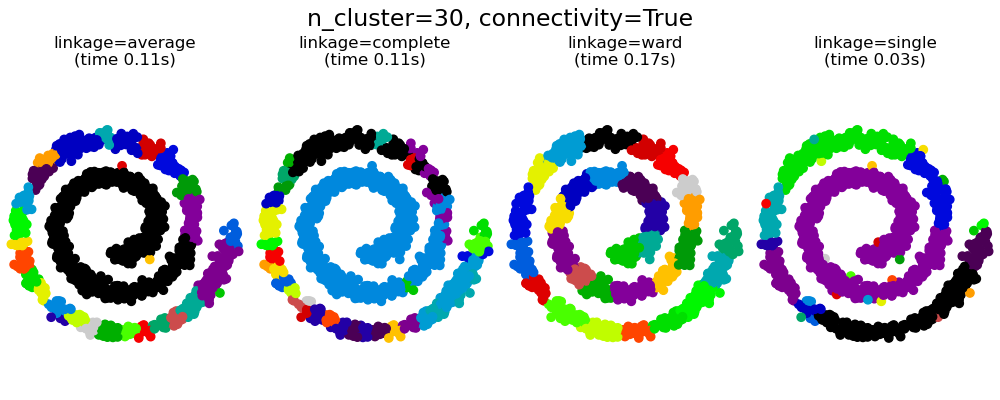
2.3.6.3. 添加连接约束#
AgglomerativeClustering的一个有趣方面是,可以通过连接矩阵(仅合并相邻的聚类)向该算法添加连接约束,该连接矩阵根据数据的给定结构为每个样本定义相邻样本。例如,在下面的瑞士卷示例中,连接约束禁止合并瑞士卷上不相邻的点,从而避免形成跨越瑞士卷重叠褶皱的聚类。
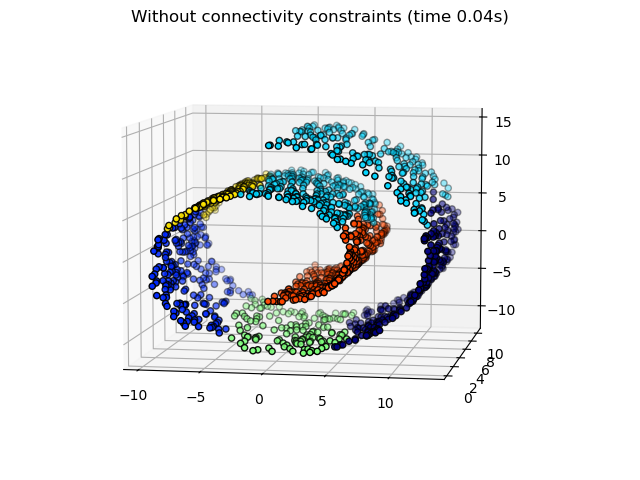
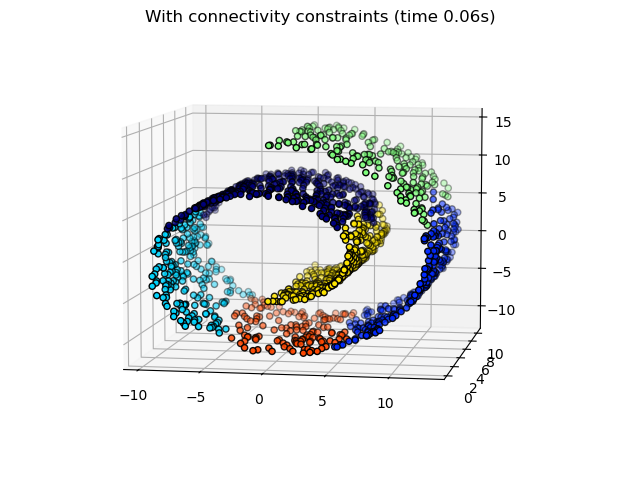
这些约束有助于施加一定的局部结构,同时也使算法更快,尤其是在样本数量较多的情况下。
连接约束通过连接矩阵来施加:一个 scipy 稀疏矩阵,只有在数据集行索引和列索引应连接的交叉点处才有元素。此矩阵可以根据先验信息构建:例如,您可能希望通过仅合并从一个页面指向另一个页面的链接来聚类网页。它也可以从数据中学习,例如使用sklearn.neighbors.kneighbors_graph来限制合并到最近邻,如此示例所示,或使用sklearn.feature_extraction.image.grid_to_graph来仅允许合并图像上相邻像素,如硬币示例所示。
警告
带有 single、average 和 complete 连接的连接约束
连接约束和 single、complete 或 average 连接可以增强凝聚聚类的“富者越富”方面,尤其是在使用sklearn.neighbors.kneighbors_graph构建时。在聚类数量较少的情况下,它们往往会给出一些宏观占据的聚类和几乎空的聚类。(参见带结构和不带结构的凝聚聚类中的讨论)。就这个问题而言,single linkage是最脆弱的连接选项。


示例
硬币图像结构化 Ward 层次聚类演示:使用 Ward 聚类将硬币图像分割成区域。
层次聚类:结构化与非结构化 Ward:在瑞士卷上使用 Ward 算法的示例,比较结构化方法与非结构化方法。
特征合并与单变量选择:基于 Ward 层次聚类的特征合并降维示例。
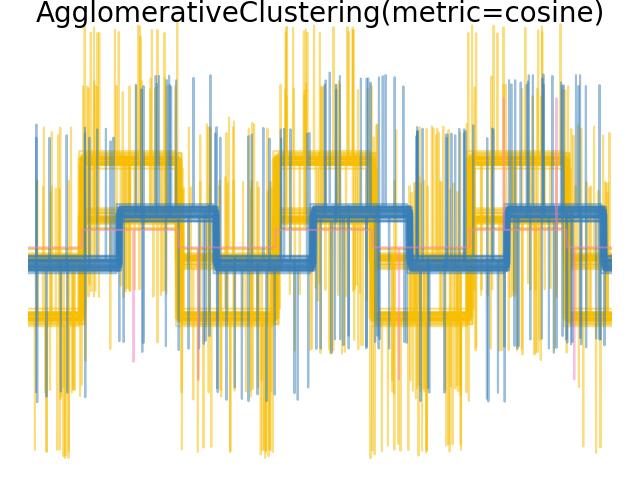
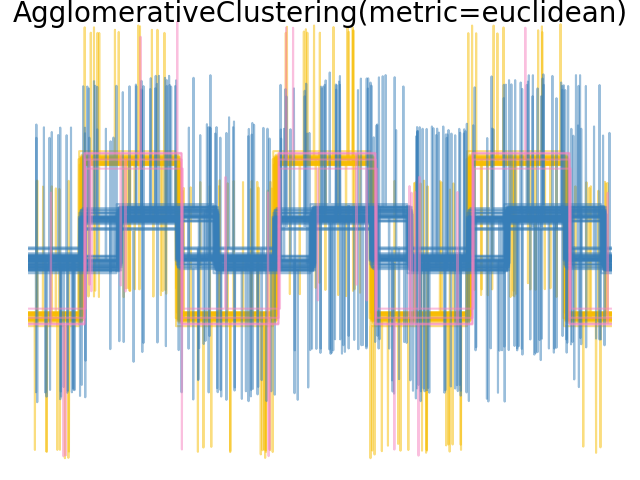
2.3.6.4. 改变度量#
Single、average 和 complete 连接可以与各种距离(或亲和度)一起使用,特别是欧几里得距离(*l2*)、曼哈顿距离(或 Cityblock,或 *l1*)、余弦距离或任何预计算的亲和度矩阵。
*l1* 距离通常适用于稀疏特征或稀疏噪声:即许多特征为零,例如使用稀有词出现的文本挖掘。
*cosine* 距离很有趣,因为它对信号的全局缩放不变。
选择度量的指导原则是使用一种度量,使不同类别样本之间的距离最大化,而同一类别内的距离最小化。
示例
2.3.6.5. 二分 K 均值#
BisectingKMeans是KMeans的一种迭代变体,使用分裂式层次聚类。它不是一次创建所有质心,而是根据之前的聚类逐步选择质心:一个聚类被重复地分成两个新的聚类,直到达到目标聚类数量。
当簇的数量很大时,BisectingKMeans 比 KMeans 更有效率,因为它每次二分只处理数据的一个子集,而 KMeans 总是处理整个数据集。
尽管BisectingKMeans 本身无法利用"k-means++" 初始化的优势,但就惯性而言,它仍然可以产生与KMeans(init="k-means++") 相当的结果,并且计算成本更低,而且可能比使用随机初始化的KMeans 产生更好的结果。
如果簇的数量与数据点的数量相比较小,则此变体比凝聚层次聚类更有效率。
此变体也不会产生空簇。
- 存在两种选择要分割的簇的策略
bisecting_strategy="largest_cluster"选择具有最多点的簇bisecting_strategy="biggest_inertia"选择具有最大惯性(簇内平方误差和最大的簇)的簇
在大多数情况下,按最大数据点数量进行选择可以产生与按惯性选择一样准确的结果,并且速度更快(尤其是在数据点数量较大的情况下,计算误差可能代价高昂)。
按最大数据点数量进行选择也可能产生大小相似的簇,而KMeans 则已知会产生大小不同的簇。
在示例二分 K 均值和普通 K 均值性能比较中可以看到二分 K 均值与普通 K 均值之间的区别。虽然普通的 K 均值算法倾向于创建不相关的簇,但二分 K 均值的簇是有序的,并形成了相当明显的层次结构。
参考文献#
“文档聚类技术的比较” Michael Steinbach、George Karypis 和 Vipin Kumar,明尼苏达大学计算机科学与工程系 (2000 年 6 月)
“K 均值和二分 K 均值算法在 Weblog 数据中的性能分析” K.Abirami 和 Dr.P.Mayilvahanan,《国际工程研究新兴技术杂志》(IJETER) 第 4 卷,第 8 期,(2016 年 8 月)
“基于 K 值自确定和聚类中心优化的二分 K 均值算法” 狄健,苟新月,华北电力大学控制与计算机工程学院,河北保定,中国 (2017 年 8 月)
2.3.7. DBSCAN#
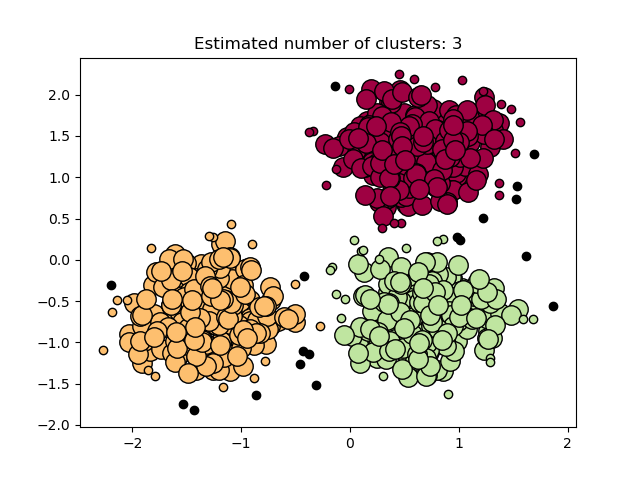
DBSCAN 算法将簇视为由低密度区域隔开的 高密度区域。由于这种相当通用的观点,DBSCAN 找到的簇可以是任何形状,而 k 均值则假设簇是凸形的。DBSCAN 的核心组成部分是 *核心样本* 的概念,核心样本是在高密度区域中的样本。因此,一个簇是一组核心样本,每个样本彼此靠近(通过某种距离度量),以及一组非核心样本,这些样本靠近核心样本(但它们本身不是核心样本)。算法有两个参数,min_samples 和 eps,它们正式定义了我们所说的 *密集* 的含义。min_samples 越高或 eps 越低,形成簇所需的密度越高。
更正式地说,我们将核心样本定义为数据集中这样的样本:存在min_samples 个其他样本在eps 的距离内,这些样本被定义为核心样本的 *邻居*。这告诉我们核心样本位于向量空间的密集区域。一个簇是一组核心样本,可以通过递归地取一个核心样本,找到其所有是核心样本的邻居,找到 *它们* 的所有是核心样本的邻居,依此类推来构建。一个簇也有一组非核心样本,这些样本是簇中核心样本的邻居,但它们本身不是核心样本。直观地说,这些样本位于簇的边缘。
根据定义,任何核心样本都是簇的一部分。任何不是核心样本的样本,并且距离任何核心样本至少有 eps 的距离,都被算法视为异常值。
虽然参数 min_samples 主要控制算法对噪声的容忍度(在嘈杂且大型的数据集上,可能需要增加此参数),但参数 eps *对于数据集和距离函数来说至关重要*,通常不能保留默认值。它控制点的局部邻域。如果选择得太小,大多数数据根本不会被聚类(并标记为 -1 表示“噪声”)。如果选择得太大的话,它会导致紧密的簇合并成一个簇,最终将整个数据集作为单个簇返回。文献中已经讨论了一些选择此参数的启发式方法,例如基于最近邻距离图中的拐点(如下面的参考文献中所述)。
在下图中,颜色表示簇成员身份,大圆圈表示算法找到的核心样本。小圆圈是非核心样本,它们仍然是簇的一部分。此外,异常值由下面的黑点表示。
示例
实现#
DBSCAN算法是确定性的,当给定相同顺序的相同数据时,总是生成相同的聚类。但是,当数据以不同顺序提供时,结果可能会有所不同。首先,即使核心样本将始终被分配到相同的聚类,但这些聚类的标签将取决于在数据中遇到这些样本的顺序。其次,更重要的是,非核心样本被分配到的聚类可能会因数据顺序而异。当非核心样本到两个不同聚类中的核心样本的距离小于eps时,就会发生这种情况。根据三角不等式,这两个核心样本彼此之间的距离必须大于eps,否则它们将位于同一聚类中。非核心样本被分配到在数据遍历中首先生成的任何聚类,因此结果将取决于数据排序。
当前的实现使用球树和kd树来确定点的邻域,这避免了计算完整的距离矩阵(如在0.14之前的scikit-learn版本中所做的那样)。保留了使用自定义度量的可能性;详情请参见NearestNeighbors。
大型样本尺寸的内存消耗#
默认情况下,此实现不是内存高效的,因为它在无法使用kd树或球树的情况下(例如,使用稀疏矩阵)会构建完整的成对相似性矩阵。此矩阵将消耗\(n^2\)个浮点数。解决此问题的几种机制是
结合使用OPTICS聚类和
extract_dbscan方法。OPTICS聚类也计算完整的成对矩阵,但一次只保留一行在内存中(内存复杂度n)。可以以内存高效的方式预计算稀疏半径邻域图(其中缺失的条目被假定为超出eps),并且可以使用
metric='precomputed'在此图上运行dbscan。参见sklearn.neighbors.NearestNeighbors.radius_neighbors_graph。可以压缩数据集,方法是如果数据中出现完全重复项则将其删除,或者使用BIRCH。然后,您只需要少量代表来代表大量点。然后,您可以在拟合DBSCAN时提供
sample_weight。
参考文献#
一种用于发现大型空间数据库中具有噪声的聚类的基于密度的算法 Ester, M., H. P. Kriegel, J. Sander, and X. Xu, 在第二届知识发现与数据挖掘国际会议论文集,波特兰,俄勒冈州,AAAI出版社,第226-231页。1996年
DBSCAN再探,再探:为什么以及如何(仍然)使用DBSCAN。 Schubert, E., Sander, J., Ester, M., Kriegel, H. P., & Xu, X. (2017)。在ACM数据库系统事务(TODS),42(3), 19。
2.3.8. HDBSCAN#
HDBSCAN算法可以看作是DBSCAN和OPTICS的扩展。具体来说,DBSCAN假设聚类标准(即密度要求)是*全局同质的*。换句话说,DBSCAN可能难以成功捕获具有不同密度的聚类。HDBSCAN减轻了这一假设,并通过构建聚类问题的替代表示来探索所有可能的密度尺度。
注意
此实现改编自HDBSCAN的原始实现,scikit-learn-contrib/hdbscan,基于[LJ2017]。
示例
2.3.8.1. 互达性图#
HDBSCAN首先定义\(d_c(x_p)\),即样本\(x_p\)的*核心距离*,为到其min_samples个最近邻的距离,包括自身。例如,如果min_samples=5并且\(x_*\)是\(x_p\)的第5个最近邻,则核心距离为
接下来,它定义\(d_m(x_p, x_q)\),即两点\(x_p, x_q\)的*互达距离*,为
这两个概念允许我们构建针对固定min_samples选择的互达性图 \(G_{ms}\)。该图将每个样本 \(x_p\) 与图的一个顶点关联,因此点 \(x_p, x_q\) 之间的边就是它们之间的互达距离 \(d_m(x_p, x_q)\)。我们可以构建该图的子集,记为 \(G_{ms,\varepsilon}\),方法是移除任何值大于 \(\varepsilon\) 的边。在这个阶段,任何核心距离小于 \(\varepsilon\) 的点都被标记为噪声。然后通过寻找这个修剪后图的连通分量来对剩余的点进行聚类。
注意
获取修剪图 \(G_{ms,\varepsilon}\) 的连通分量等效于使用 min_samples 和 \(\varepsilon\) 运行 DBSCAN*。DBSCAN* 是[CM2013]中提到的 DBSCAN 的一个稍微修改的版本。
2.3.8.2. 层次聚类#
HDBSCAN 可以看作是一种算法,它对所有 \(\varepsilon\) 值执行 DBSCAN* 聚类。如前所述,这等效于找到所有 \(\varepsilon\) 值的互达性图的连通分量。为了高效地做到这一点,HDBSCAN 首先从完全连接的互达性图中提取最小生成树 (MST),然后贪婪地剪掉权重最大的边。HDBSCAN 算法的概要如下:
提取 \(G_{ms}\) 的 MST。
通过为每个顶点添加一个“自环”,并将权重设置为基础样本的核心距离来扩展 MST。
初始化 MST 的单个聚类和标签。
从 MST 中移除权重最大的边(同时移除具有相同权重的边)。
将聚类标签分配给包含现在已移除边的端点的连通分量。如果该分量至少不含有一条边,则将其分配一个“空”标签,将其标记为噪声。
重复步骤 4-5,直到没有更多连通分量。
因此,HDBSCAN 能够以层次方式获得固定 min_samples 选择下 DBSCAN* 可以实现的所有可能的划分。实际上,这允许 HDBSCAN 在多个密度上执行聚类,因此它不再需要将 \(\varepsilon\) 作为超参数给出。相反,它仅依赖于 min_samples 的选择,这往往是一个更稳健的超参数。
HDBSCAN 可以通过额外的超参数 min_cluster_size 进行平滑处理,该参数指定在层次聚类过程中,样本数少于 minimum_cluster_size 的分量被认为是噪声。在实践中,可以设置 minimum_cluster_size = min_samples 来耦合参数并简化超参数空间。
参考文献
Campello, R.J.G.B., Moulavi, D., Sander, J. (2013). 基于层次密度估计的基于密度的聚类。载于:Pei, J., Tseng, V.S., Cao, L., Motoda, H., Xu, G. (eds) 知识发现和数据挖掘进展。PAKDD 2013。计算机科学讲义(),第 7819 卷。Springer,柏林,海德堡。基于层次密度估计的基于密度的聚类
L. McInnes 和 J. Healy,(2017)。加速的基于层次密度的聚类。载于:IEEE 国际数据挖掘研讨会 (ICDMW),2017 年,第 33-42 页。加速的基于层次密度的聚类
2.3.9. OPTICS#
OPTICS 算法与 DBSCAN 算法有很多相似之处,可以认为是 DBSCAN 的一个泛化,它将 eps 要求从单个值放宽到一个值范围。DBSCAN 和 OPTICS 之间的主要区别在于 OPTICS 算法构建了一个可达性图,该图为每个样本分配一个 reachability_ 距离和一个聚类中的位置 ordering_ 属性;这两个属性在模型拟合时分配,用于确定聚类成员资格。如果 OPTICS 使用 max_eps 的默认值 *inf* 运行,则可以使用 cluster_optics_dbscan 方法以线性时间对任何给定的 eps 值重复执行 DBSCAN 样式的聚类提取。将 max_eps 设置为较低的值将导致运行时间更短,可以将其视为从每个点查找其他潜在可达点的最大邻域半径。
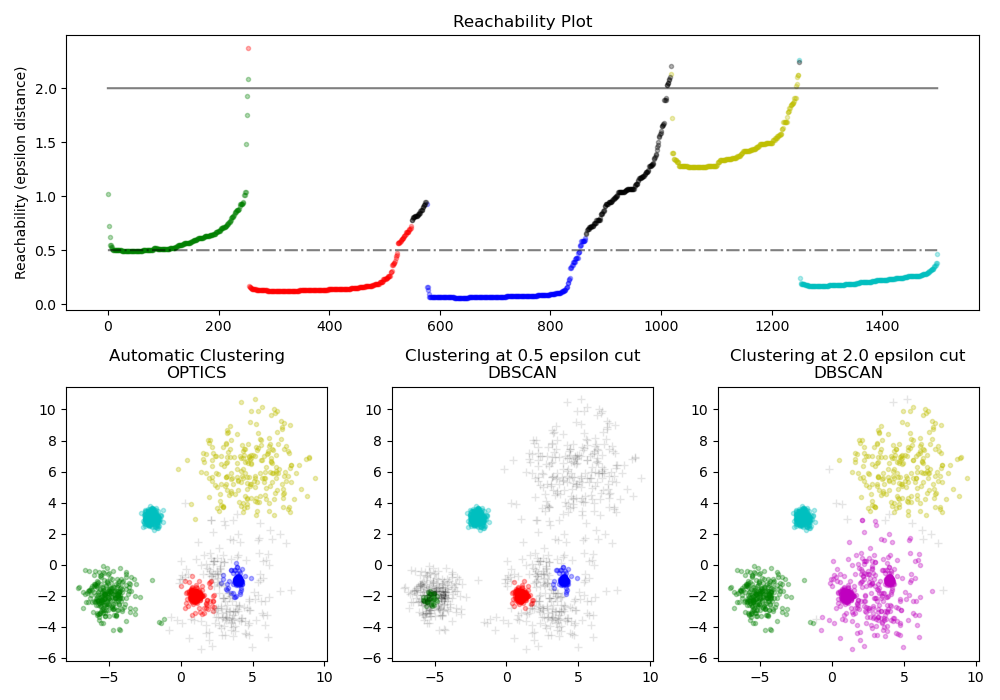
OPTICS 生成的可达性距离允许在单个数据集中进行可变密度聚类提取。如上图所示,结合可达性距离和数据集 ordering_ 可以生成可达性图,其中点密度表示在 Y 轴上,点按顺序排列,使得附近的点相邻。“切割”可达性图中的单个值会产生类似 DBSCAN 的结果;所有高于“切割”线的点都被分类为噪声,并且每次从左到右读取时出现中断都表示一个新的聚类。OPTICS 的默认聚类提取查看图中的陡峭斜率以查找聚类,用户可以使用参数 xi 定义什么算作陡峭斜率。图本身还有其他分析可能性,例如通过可达性图树状图生成数据的层次表示,并且可以通过 cluster_hierarchy_ 参数访问算法检测到的聚类层次结构。上图已着色,以便平面空间中的聚类颜色与可达性图的线性段聚类匹配。请注意,蓝色和红色聚类在可达性图中相邻,并且可以作为更大父聚类的子节点进行层次表示。
示例
与 DBSCAN 的比较#
OPTICS 的 cluster_optics_dbscan 方法和 DBSCAN 的结果非常相似,但并不总是完全相同;尤其是在外围点和噪声点的标记方面。这是因为 OPTICS 处理的每个密集区域的第一个样本具有较大的可达性值,同时又靠近该区域中的其他点,因此有时会被标记为噪声而不是外围点。当考虑将相邻点标记为外围点或噪声点时,这会影响它们。
请注意,对于任何单个 eps 值,DBSCAN 的运行时间往往比 OPTICS 短;但是,对于不同 eps 值的重复运行,一次 OPTICS 运行可能需要的累积运行时间少于 DBSCAN。同样重要的是要注意,只有当 eps 和 max_eps 接近时,OPTICS 的输出才接近 DBSCAN 的输出。
计算复杂度#
使用空间索引树来避免计算完整的距离矩阵,并允许在大型样本集上高效地使用内存。可以通过 metric 关键字提供不同的距离度量。
对于大型数据集,可以通过 HDBSCAN 获得相似(但并不相同)的结果。HDBSCAN 实现是多线程的,并且具有比 OPTICS 更好的算法运行时间复杂度,但代价是内存扩展性较差。对于使用 HDBSCAN 会耗尽系统内存的超大型数据集,OPTICS 将保持 \(n\)(而不是 \(n^2\))的内存扩展性;但是,可能需要调整 max_eps 参数才能在合理的时间内得到解决方案。
参考文献#
“OPTICS: ordering points to identify the clustering structure.” Ankerst, Mihael, Markus M. Breunig, Hans-Peter Kriegel, and Jörg Sander. In ACM Sigmod Record, vol. 28, no. 2, pp. 49-60. ACM, 1999.
2.3.10. BIRCH#
Birch 为给定数据构建一棵称为聚类特征树 (CFT) 的树。数据基本上会被有损压缩为一组聚类特征节点 (CF 节点)。CF 节点包含多个称为聚类特征子集群 (CF 子集群) 的子集群,这些位于非终端 CF 节点中的 CF 子集群可以具有 CF 节点作为子节点。
CF 子集群保存聚类所需的必要信息,从而无需将整个输入数据保存在内存中。这些信息包括:
子集群中的样本数。
线性总和 - 一个 n 维向量,保存所有样本的总和。
平方和 - 所有样本的平方 L2 范数之和。
质心 - 为避免重新计算,线性总和 / 样本数。
质心的平方范数。
BIRCH 算法有两个参数:阈值和分支因子。分支因子限制节点中子集群的数量,阈值限制进入样本与现有子集群之间的距离。
该算法可以看作是一种实例或数据缩减方法,因为它将输入数据缩减为从 CFT 的叶子直接获得的一组子集群。可以通过将其馈送到全局聚类器来进一步处理此缩减后的数据。全局聚类器可以通过 n_clusters 设置。如果将 n_clusters 设置为 None,则直接读取叶子中的子集群;否则,全局聚类步骤将这些子集群标记为全局集群(标签),并将样本映射到最近子集群的全局标签。
算法描述#
将新的样本插入到 CF 树的根节点(这是一个 CF 节点)。然后,它与根节点的子集群合并,该子集群在合并后具有最小的半径,并受阈值和分支因子条件的约束。如果子集群有任何子节点,则重复此操作,直到到达叶子节点。在找到叶子节点中最接近的子集群后,递归更新此子集群和父子集群的属性。
如果通过合并新样本和最近的子集群获得的子集群的半径大于阈值的平方,并且子集群的数量大于分支因子,则会暂时为该新样本分配空间。选择两个最远的子集群,并根据这两个子集群之间的距离将子集群分成两组。
如果此分裂节点具有父子集群并且有空间容纳新的子集群,则将父节点分裂成两个。如果没有空间,则再次将此节点分成两个,并递归地继续此过程,直到到达根节点。
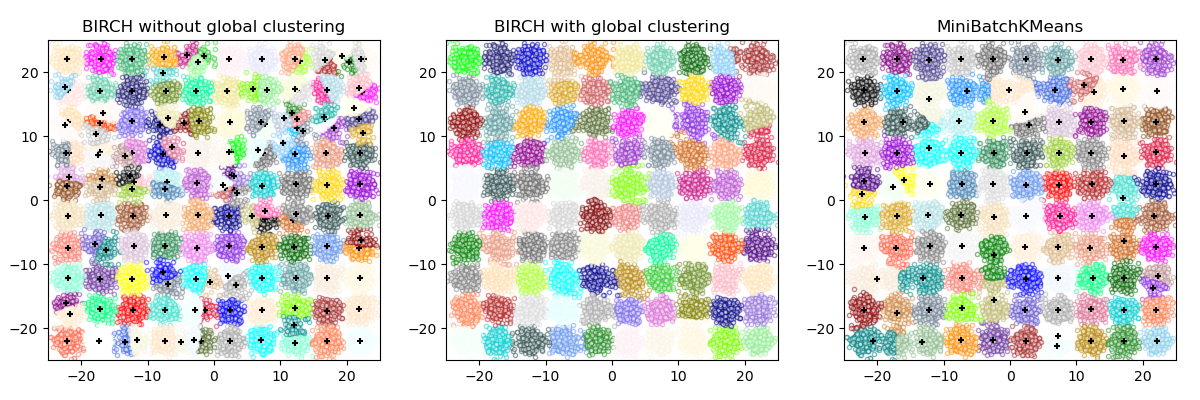
BIRCH 或 MiniBatchKMeans?#
BIRCH 并不很好地扩展到高维数据。根据经验,如果
n_features大于 20,则通常最好使用 MiniBatchKMeans。如果需要减少数据实例的数量,或者如果希望获得大量子集群(作为预处理步骤或其他目的),则 BIRCH 比 MiniBatchKMeans 更有用。
如何使用partial_fit?#
为了避免全局聚类的计算,建议用户在每次调用partial_fit时:
初始时设置
n_clusters=None。通过多次调用partial_fit来训练所有数据。
使用
brc.set_params(n_clusters=n_clusters)将n_clusters设置为所需的值。最后调用
partial_fit,不带任何参数,即brc.partial_fit(),这将执行全局聚类。
参考文献#
Tian Zhang, Raghu Ramakrishnan, Maron Livny BIRCH: 一种针对大型数据库的高效数据聚类方法。 https://www.cs.sfu.ca/CourseCentral/459/han/papers/zhang96.pdf
Roberto Perdisci JBirch - BIRCH聚类算法的Java实现 https://code.google.com/archive/p/jbirch
2.3.11. 聚类性能评估#
评估聚类算法的性能并不像计算监督分类算法的错误数量或精确率和召回率那样简单。特别是,任何评估指标都不应考虑聚类标签的绝对值,而应考虑此聚类是否定义了与某些地面实况类集类似的数据分离,或者是否满足某些假设,例如根据某些相似性度量,属于同一类的成员比属于不同类的成员更相似。
2.3.11.1. Rand指数#
已知地面实况类赋值labels_true和我们对相同样本的聚类算法赋值labels_pred,**(调整或未调整) Rand 指数**是一个测量这两个赋值**相似性**的函数,忽略排列。
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.rand_score(labels_true, labels_pred)
0.66...
Rand 指数不能保证对于随机标记获得接近 0.0 的值。调整后的 Rand 指数**校正了偶然性**,并将给出这样的基线。
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
0.24...
与所有聚类指标一样,可以在预测标签中排列 0 和 1,将 2 重命名为 3,并获得相同的得分。
>>> labels_pred = [1, 1, 0, 0, 3, 3]
>>> metrics.rand_score(labels_true, labels_pred)
0.66...
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
0.24...
此外,rand_score adjusted_rand_score都是**对称的**: 交换参数不会改变分数。因此,它们可用作**一致性度量**。
>>> metrics.rand_score(labels_pred, labels_true)
0.66...
>>> metrics.adjusted_rand_score(labels_pred, labels_true)
0.24...
完美标记的得分为 1.0。
>>> labels_pred = labels_true[:]
>>> metrics.rand_score(labels_true, labels_pred)
1.0
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
1.0
一致性差的标签(例如,独立标记)得分较低,对于调整后的 Rand 指数,得分将为负或接近于零。但是,对于未调整的 Rand 指数,得分虽然较低,但不一定接近于零。
>>> labels_true = [0, 0, 0, 0, 0, 0, 1, 1]
>>> labels_pred = [0, 1, 2, 3, 4, 5, 5, 6]
>>> metrics.rand_score(labels_true, labels_pred)
0.39...
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
-0.07...
示例
聚类性能评估中的偶然性调整:分析数据集大小对随机分配的聚类度量值的影响。
数学公式#
如果 C 是地面实况类赋值,K 是聚类,让我们定义\(a\)和\(b\)为
\(a\),在 C 中属于同一集合且在 K 中属于同一集合的元素对数
b 代表在 C 和 K 中属于不同集合的元素对的数量。
未调整的 Rand 指数计算如下:
其中 \(C_2^{n_{samples}}\) 是数据集中所有可能的对的总数。只要计算方式一致,使用有序对还是无序对进行计算都没有关系。
然而,Rand 指数不能保证随机标签分配的值接近于零(特别是当聚类数量与样本数量的数量级相同时)。
为了解决这个问题,我们可以通过如下定义调整后的 Rand 指数来扣除随机标签的预期 RI \(E[\text{RI}]\):
参考文献#
比较划分 L. Hubert 和 P. Arabie,《分类杂志》1985年
Hubert-Arabie 调整 Rand 指数的属性 D. Steinley,《心理学方法》2004年
2.3.11.2. 基于互信息的评分#
已知真值类分配labels_true和我们对相同样本的聚类算法分配labels_pred,**互信息**是一个衡量两种分配**一致性**的函数,忽略排列。此度量的两种不同的归一化版本可用,即**归一化互信息 (NMI)** 和**调整后的互信息 (AMI)**。NMI 常用于文献中,而 AMI 是最近提出的,并且是**针对偶然性进行归一化的**。
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.adjusted_mutual_info_score(labels_true, labels_pred)
0.22504...
可以对预测标签中的 0 和 1 进行置换,将 2 重命名为 3,得到相同的得分。
>>> labels_pred = [1, 1, 0, 0, 3, 3]
>>> metrics.adjusted_mutual_info_score(labels_true, labels_pred)
0.22504...
所有 mutual_info_score、adjusted_mutual_info_score 和 normalized_mutual_info_score 都是对称的:交换参数不会改变得分。因此,它们可以用作**一致性度量**。
>>> metrics.adjusted_mutual_info_score(labels_pred, labels_true)
0.22504...
完美标记的得分为 1.0。
>>> labels_pred = labels_true[:]
>>> metrics.adjusted_mutual_info_score(labels_true, labels_pred)
1.0
>>> metrics.normalized_mutual_info_score(labels_true, labels_pred)
1.0
这对mutual_info_score并不适用,因此更难以判断。
>>> metrics.mutual_info_score(labels_true, labels_pred)
0.69...
不好的(例如,独立的标签)得分是非正数。
>>> labels_true = [0, 1, 2, 0, 3, 4, 5, 1]
>>> labels_pred = [1, 1, 0, 0, 2, 2, 2, 2]
>>> metrics.adjusted_mutual_info_score(labels_true, labels_pred)
-0.10526...
示例
聚类性能评估中的偶然性调整:分析数据集大小对随机分配的聚类度量值的影响。此示例还包括调整后的 Rand 指数。
数学公式#
假设有两个标签分配(对相同的 N 个对象),\(U\) 和 \(V\)。它们的熵是划分集的不确定性量,定义为
其中 \(P(i) = |U_i| / N\) 是从 \(U\) 中随机选择的物体落入类 \(U_i\) 的概率。 \(V\) 同理
其中 \(P'(j) = |V_j| / N\)。\(U\) 和 \(V\) 之间的互信息 (MI) 计算如下:
其中 \(P(i, j) = |U_i \cap V_j| / N\) 是随机选择的物体同时落入类 \(U_i\) 和 \(V_j\) 的概率。
它也可以用集合基数公式表示
归一化互信息定义为:
互信息的这个值以及归一化变体都没有针对偶然性进行调整,并且随着不同标签(聚类)数量的增加而趋于增加,而不管标签分配之间的实际“互信息”量是多少。
互信息的期望值可以使用以下公式计算[VEB2009]。在这个公式中,\(a_i = |U_i|\)(\(U_i\)中的元素个数)和\(b_j = |V_j|\)(\(V_j\)中的元素个数)。
使用期望值,调整后的互信息可以使用与调整后的Rand指数类似的形式计算
对于归一化互信息和调整后的互信息,归一化值通常是每个聚类的熵的某种广义平均值。存在各种广义平均值,并且不存在优先选择一种而不是另一种的明确规则。这个决定很大程度上取决于具体的领域;例如,在社区检测中,算术平均值最为常见。每种归一化方法都提供了“性质上相似的行为” [YAT2016]。在我们的实现中,这由average_method参数控制。
Vinh等人 (2010) 根据其平均方法命名了NMI和AMI的变体 [VEB2010]。他们的“sqrt”和“sum”平均值分别是几何平均值和算术平均值;我们更广泛地使用这些更常见的名称。
参考文献
Strehl, Alexander, 和 Joydeep Ghosh (2002)。“聚类集成——一种用于组合多个划分的知识重用框架”。机器学习研究杂志 3: 583-617。 doi:10.1162/153244303321897735.
Vinh, Epps和Bailey,(2009)。“用于聚类比较的信息论度量”。第26届国际机器学习年会论文集 - ICML '09。 doi:10.1145/1553374.1553511。ISBN 9781605585161。
Vinh, Epps和Bailey,(2010)。“用于聚类比较的信息论度量:变体、属性、归一化和偶然性校正”。JMLR <https://jmlr.csail.mit.edu/papers/volume11/vinh10a/vinh10a.pdf>
Yang, Algesheimer和Tessone,(2016)。“人工网络上社区检测算法的比较分析”。科学报告 6: 30750。 doi:10.1038/srep30750.
2.3.11.3. 同质性、完整性和V-测度#
了解样本的真实类分配后,可以使用条件熵分析定义一些直观的度量。
特别是Rosenberg和Hirschberg (2007) 为任何聚类分配定义了以下两个理想的目标
同质性:每个聚类只包含单个类别的成员。
完整性:给定类别中的所有成员都被分配到同一个聚类。
我们可以将这些概念转换为分数 homogeneity_score 和 completeness_score。两者都下限为0.0,上限为1.0(越高越好)
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.homogeneity_score(labels_true, labels_pred)
0.66...
>>> metrics.completeness_score(labels_true, labels_pred)
0.42...
它们的调和平均数称为V-测度,由 v_measure_score 计算
>>> metrics.v_measure_score(labels_true, labels_pred)
0.51...
此函数的公式如下
beta默认为1.0,但如果使用小于1的beta值
>>> metrics.v_measure_score(labels_true, labels_pred, beta=0.6)
0.54...
将赋予同质性更大的权重,而使用大于1的值
>>> metrics.v_measure_score(labels_true, labels_pred, beta=1.8)
0.48...
将赋予完整性更大的权重。
V-测度实际上等同于上面讨论的互信息 (NMI),其聚合函数为算术平均值 [B2011]。
可以使用 homogeneity_completeness_v_measure 一次计算同质性、完整性和V-测度,如下所示
>>> metrics.homogeneity_completeness_v_measure(labels_true, labels_pred)
(0.66..., 0.42..., 0.51...)
以下聚类分配略好一些,因为它具有同质性但缺乏完整性
>>> labels_pred = [0, 0, 0, 1, 2, 2]
>>> metrics.homogeneity_completeness_v_measure(labels_true, labels_pred)
(1.0, 0.68..., 0.81...)
注意
v_measure_score 是对称的:它可以用来评估对同一数据集的两个独立分配的一致性。
对于 completeness_score 和 homogeneity_score 来说并非如此:两者都受到以下关系的约束
homogeneity_score(a, b) == completeness_score(b, a)
示例
聚类性能评估中的偶然性调整:分析数据集大小对随机分配的聚类度量值的影响。
数学公式#
同质性和完整性分数正式由下式给出
其中\(H(C|K)\)是给定聚类分配的类的条件熵,由下式给出
且\(H(C)\)是**类别的熵**,其计算公式为:
其中\(n\)是样本总数,\(n_c\)和\(n_k\)分别是属于类别\(c\)和簇\(k\)的样本数,最后\(n_{c,k}\)是分配给簇\(k\)的类别\(c\)的样本数。
**给定类别时的簇的条件熵** \(H(K|C)\) 和**簇的熵** \(H(K)\) 的定义方式相同。
Rosenberg 和 Hirschberg 进一步将**V-measure** 定义为**同质性和完整性的调和平均数**
参考文献
V-Measure: A conditional entropy-based external cluster evaluation measure Andrew Rosenberg 和 Julia Hirschberg,2007
Identification and Characterization of Events in Social Media,Hila Becker,博士论文。
2.3.11.4. Fowlkes-Mallows 指标#
最初的 Fowlkes-Mallows 指标 (FMI) 用于衡量两个聚类结果之间的相似性,这本质上是一种无监督比较。当已知样本的真实类别分配时,可以使用 Fowlkes-Mallows 指标的监督适应(如在 sklearn.metrics.fowlkes_mallows_score 中实现) 。FMI 定义为成对精确率和召回率的几何平均数
在上述公式中
TP(**真阳性**):在真实标签和预测标签中都一起聚类的点对数量。FP(**假阳性**):在预测标签中一起聚类但在真实标签中未一起聚类的点对数量。FN(**假阴性**):在真实标签中一起聚类但在预测标签中未一起聚类的点对数量。
该指标的范围为 0 到 1。高值表示两个聚类之间的相似性较好。
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.fowlkes_mallows_score(labels_true, labels_pred)
0.47140...
可以对预测标签中的 0 和 1 进行置换,将 2 重命名为 3,得到相同的得分。
>>> labels_pred = [1, 1, 0, 0, 3, 3]
>>> metrics.fowlkes_mallows_score(labels_true, labels_pred)
0.47140...
完美标记的得分为 1.0。
>>> labels_pred = labels_true[:]
>>> metrics.fowlkes_mallows_score(labels_true, labels_pred)
1.0
较差的(例如,独立的标记)得分将为零。
>>> labels_true = [0, 1, 2, 0, 3, 4, 5, 1]
>>> labels_pred = [1, 1, 0, 0, 2, 2, 2, 2]
>>> metrics.fowlkes_mallows_score(labels_true, labels_pred)
0.0
参考文献#
E. B. Fowkles 和 C. L. Mallows,1983。“一种比较两个层次聚类的方法”。美国统计协会杂志。https://www.tandfonline.com/doi/abs/10.1080/01621459.1983.10478008
2.3.11.5. 轮廓系数#
如果不知道真实标签,则必须使用模型本身进行评估。轮廓系数(sklearn.metrics.silhouette_score)就是一个这样的评估示例,其中较高的轮廓系数得分与具有更好定义的聚类的模型相关。轮廓系数是针对每个样本定义的,并且由两个得分组成
**a**:样本与同一类中所有其他点之间的平均距离。
**b**:样本与**下一个最近的簇**中所有其他点之间的平均距离。
单个样本的轮廓系数 *s* 则表示为
一组样本的轮廓系数表示为每个样本的轮廓系数的平均值。
>>> from sklearn import metrics
>>> from sklearn.metrics import pairwise_distances
>>> from sklearn import datasets
>>> X, y = datasets.load_iris(return_X_y=True)
在正常使用中,轮廓系数应用于聚类分析的结果。
>>> import numpy as np
>>> from sklearn.cluster import KMeans
>>> kmeans_model = KMeans(n_clusters=3, random_state=1).fit(X)
>>> labels = kmeans_model.labels_
>>> metrics.silhouette_score(X, labels, metric='euclidean')
0.55...
示例
使用 KMeans 聚类的轮廓分析选择聚类数量:在此示例中,轮廓分析用于为 n_clusters 选择最佳值。
参考文献#
Peter J. Rousseeuw (1987)。“轮廓:聚类分析解释和验证的图形辅助工具”。计算与应用数学 20:53-65。
2.3.11.6. Calinski-Harabasz 指标#
如果不知道真实标签,则可以使用 Calinski-Harabasz 指标(sklearn.metrics.calinski_harabasz_score)(也称为方差比率准则)来评估模型,其中较高的 Calinski-Harabasz 得分与具有更好定义的聚类的模型相关。
该指标是所有聚类的组间离散度之和与组内离散度之和的比率(其中离散度定义为距离平方和)。
>>> from sklearn import metrics
>>> from sklearn.metrics import pairwise_distances
>>> from sklearn import datasets
>>> X, y = datasets.load_iris(return_X_y=True)
在正常使用情况下,Calinski-Harabasz 指数应用于聚类分析的结果。
>>> import numpy as np
>>> from sklearn.cluster import KMeans
>>> kmeans_model = KMeans(n_clusters=3, random_state=1).fit(X)
>>> labels = kmeans_model.labels_
>>> metrics.calinski_harabasz_score(X, labels)
561.59...
数学公式#
对于大小为 \(n_E\) 的数据集 \(E\),将其聚类成 \(k\) 个聚类,Calinski-Harabasz 分数 \(s\) 定义为聚类间离散度均值与聚类内离散度的比率
其中 \(\mathrm{tr}(B_k)\) 是组间离散度矩阵的迹,\(\mathrm{tr}(W_k)\) 是由下式定义的聚类内离散度矩阵的迹:
其中 \(C_q\) 是聚类 \(q\) 中的点集,\(c_q\) 是聚类 \(q\) 的中心,\(c_E\) 是 \(E\) 的中心,\(n_q\) 是聚类 \(q\) 中的点数。
参考文献#
Caliński, T., & Harabasz, J. (1974). “一种用于聚类分析的树状图方法”. Communications in Statistics-theory and Methods 3: 1-27.
2.3.11.7. Davies-Bouldin 指数#
如果不知道真实标签,可以使用 Davies-Bouldin 指数 (sklearn.metrics.davies_bouldin_score) 来评估模型,其中 Davies-Bouldin 指数越低,表示模型中聚类之间的分离度越好。
该指数表示聚类之间平均“相似性”,其中相似性是一种度量,它将聚类之间的距离与聚类本身的大小进行比较。
零是可能的最低分数。越接近零的值表示更好的划分。
在正常使用情况下,Davies-Bouldin 指数应用于聚类分析的结果,如下所示:
>>> from sklearn import datasets
>>> iris = datasets.load_iris()
>>> X = iris.data
>>> from sklearn.cluster import KMeans
>>> from sklearn.metrics import davies_bouldin_score
>>> kmeans = KMeans(n_clusters=3, random_state=1).fit(X)
>>> labels = kmeans.labels_
>>> davies_bouldin_score(X, labels)
0.666...
数学公式#
该指数定义为每个聚类 \(C_i\)(对于 \(i=1, ..., k\))与其最相似的聚类 \(C_j\) 之间的平均相似性。在此指数的上下文中,相似性定义为一个度量 \(R_{ij}\),它权衡了
\(s_i\),聚类 \(i\) 中每个点与其聚类质心之间的平均距离——也称为聚类直径。
\(d_{ij}\),聚类质心 \(i\) 和 \(j\) 之间的距离。
构造 \(R_{ij}\) 的一个简单选择,使其非负且对称:
然后,Davies-Bouldin 指数定义为:
参考文献#
Davies, David L.; Bouldin, Donald W. (1979). “一种聚类分离度量” IEEE Transactions on Pattern Analysis and Machine Intelligence. PAMI-1 (2): 224-227.
Halkidi, Maria; Batistakis, Yannis; Vazirgiannis, Michalis (2001). “关于聚类验证技术” Journal of Intelligent Information Systems, 17(2-3), 107-145.
2.3.11.8. 列联表#
列联表 (sklearn.metrics.cluster.contingency_matrix) 报告每对真实/预测聚类的交集基数。列联表为所有聚类度量提供了充分的统计数据,其中样本独立同分布,并且不需要考虑某些实例未被聚类的情况。
这是一个例子
>>> from sklearn.metrics.cluster import contingency_matrix
>>> x = ["a", "a", "a", "b", "b", "b"]
>>> y = [0, 0, 1, 1, 2, 2]
>>> contingency_matrix(x, y)
array([[2, 1, 0],
[0, 1, 2]])
输出数组的第一行表示有三个样本的真实聚类为“a”。其中,两个样本在预测聚类0中,一个在1中,没有在2中。第二行表示有三个样本的真实聚类为“b”。其中,没有样本在预测聚类0中,一个在1中,两个在2中。
分类的混淆矩阵是一个方形列联矩阵,其中行和列的顺序对应于类别列表。
参考文献#
2.3.11.9. 配对混淆矩阵#
配对混淆矩阵(sklearn.metrics.cluster.pair_confusion_matrix)是一个2x2的相似性矩阵
它是通过考虑所有样本对并计算在真实和预测聚类下被分配到相同或不同聚类的样本对的数量来计算两个聚类之间的。
它包含以下条目:
\(C_{00}\):两个聚类中样本均未聚在一起的样本对的数量
\(C_{10}\):真实标签聚类中样本聚在一起,但另一个聚类中样本未聚在一起的样本对的数量
\(C_{01}\):真实标签聚类中样本未聚在一起,但另一个聚类中样本聚在一起的样本对的数量
\(C_{11}\):两个聚类中样本均聚在一起的样本对的数量
将一对样本聚在一起视为正样本对,则如同二元分类一样,真阴性计数为\(C_{00}\),假阴性计数为\(C_{10}\),真阳性计数为\(C_{11}\),假阳性计数为\(C_{01}\)。
完美匹配的标签在对角线上所有非零条目,无论实际标签值如何。
>>> from sklearn.metrics.cluster import pair_confusion_matrix
>>> pair_confusion_matrix([0, 0, 1, 1], [0, 0, 1, 1])
array([[8, 0],
[0, 4]])
>>> pair_confusion_matrix([0, 0, 1, 1], [1, 1, 0, 0])
array([[8, 0],
[0, 4]])
将所有类成员分配到同一聚类的标签是完整的,但可能并不总是纯净的,因此会受到惩罚,并且具有一些非对角线非零条目。
>>> pair_confusion_matrix([0, 0, 1, 2], [0, 0, 1, 1])
array([[8, 2],
[0, 2]])
该矩阵不是对称的。
>>> pair_confusion_matrix([0, 0, 1, 1], [0, 0, 1, 2])
array([[8, 0],
[2, 2]])
如果类成员完全分布在不同的聚类中,则分配完全不完整,因此矩阵的对角线条目全为零。
>>> pair_confusion_matrix([0, 0, 0, 0], [0, 1, 2, 3])
array([[ 0, 0],
[12, 0]])