1.4. 支持向量机#
**支持向量机 (SVM)** 是一组用于分类、回归和异常值检测的监督学习方法。
支持向量机的优点包括:
在高维空间中有效。
在维度数量大于样本数量的情况下仍然有效。
在决策函数中使用训练点的一个子集(称为支持向量),因此它也是内存高效的。
用途广泛:可以为决策函数指定不同的核函数。提供了常见的核函数,但也可以指定自定义核函数。
支持向量机的缺点包括:
scikit-learn 中的支持向量机支持密集型(numpy.ndarray 和可通过 numpy.asarray 转换为该类型的)和稀疏型(任何 scipy.sparse)样本向量作为输入。但是,要使用 SVM 对稀疏数据进行预测,必须先用此类数据对其进行拟合。为了获得最佳性能,请使用 C 顺序的 numpy.ndarray(密集型)或 scipy.sparse.csr_matrix(稀疏型),dtype=float64。
1.4.1. 分类#
SVC、NuSVC 和 LinearSVC 是能够对数据集执行二元和多类别分类的类。
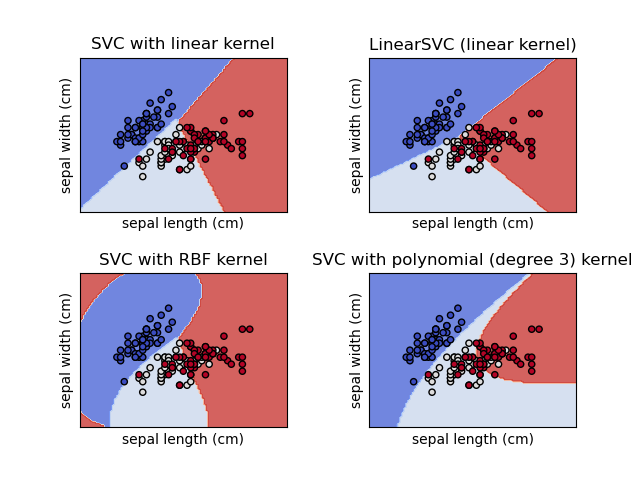
SVC 和 NuSVC 是类似的方法,但接受略微不同的参数集,并且具有不同的数学公式(参见章节 数学公式)。另一方面,LinearSVC 是支持向量分类的另一种(更快)实现,适用于线性核的情况。它也缺少SVC 和 NuSVC 的一些属性,例如 support_。LinearSVC 使用 squared_hinge 损失函数,并且由于其在 liblinear 中的实现,如果考虑的话,它也会对截距进行正则化。但是,可以通过仔细微调其 intercept_scaling 参数来减少这种影响,该参数允许截距项与其他特征相比具有不同的正则化行为。因此,分类结果和分数可能与其他两个分类器不同。
与其他分类器一样,SVC、NuSVC 和 LinearSVC 将两个数组作为输入:形状为 (n_samples, n_features) 的数组 X,包含训练样本;以及形状为 (n_samples) 的类别标签(字符串或整数)数组 y。
>>> from sklearn import svm
>>> X = [[0, 0], [1, 1]]
>>> y = [0, 1]
>>> clf = svm.SVC()
>>> clf.fit(X, y)
SVC()
拟合后,模型可用于预测新值。
>>> clf.predict([[2., 2.]])
array([1])
SVM 的决策函数(在 数学公式 中详细说明)取决于训练数据的一个子集,称为支持向量。这些支持向量的某些属性可以在属性 support_vectors_、support_ 和 n_support_ 中找到。
>>> # get support vectors
>>> clf.support_vectors_
array([[0., 0.],
[1., 1.]])
>>> # get indices of support vectors
>>> clf.support_
array([0, 1]...)
>>> # get number of support vectors for each class
>>> clf.n_support_
array([1, 1]...)
示例
1.4.1.1. 多类分类#
SVC 和 NuSVC 实现了用于多类分类的“一对一”方法。总共构建了 n_classes * (n_classes - 1) / 2 个分类器,每个分类器都训练来自两类的数 据。为了与其他分类器提供一致的接口,decision_function_shape 选项允许将“一对一”分类器的结果单调地转换为形状为 (n_samples, n_classes) 的“一对多”决策函数,这是参数的默认设置 (default='ovr')。
>>> X = [[0], [1], [2], [3]]
>>> Y = [0, 1, 2, 3]
>>> clf = svm.SVC(decision_function_shape='ovo')
>>> clf.fit(X, Y)
SVC(decision_function_shape='ovo')
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 6 classes: 4*3/2 = 6
6
>>> clf.decision_function_shape = "ovr"
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 4 classes
4
另一方面,LinearSVC 实现了“一对多”多类策略,因此训练了 n_classes 个模型。
>>> lin_clf = svm.LinearSVC()
>>> lin_clf.fit(X, Y)
LinearSVC()
>>> dec = lin_clf.decision_function([[1]])
>>> dec.shape[1]
4
有关决策函数的完整描述,请参见 数学公式。
多类策略详情#
请注意,LinearSVC 还实现了一种替代的多类策略,即 Crammer 和 Singer [16] 提出的所谓多类 SVM,方法是使用选项 multi_class='crammer_singer'。在实践中,通常更倾向于使用一对多分类,因为结果大多相似,但运行时间明显更短。
对于“一对多”LinearSVC,属性 coef_ 和 intercept_ 的形状分别为 (n_classes, n_features) 和 (n_classes,)。系数的每一行对应于 n_classes 个“一对多”分类器中的一个,截距的顺序也类似,按照“一对一”类的顺序排列。
对于“一对一”的SVC 和 NuSVC,属性的布局更为复杂。对于线性核,属性coef_ 和 intercept_ 的形状分别为 (n_classes * (n_classes - 1) / 2, n_features) 和 (n_classes * (n_classes - 1) / 2)。这与上面描述的 LinearSVC 的布局类似,每一行现在对应一个二元分类器。对于类别 0 到 n 的顺序为“0 vs 1”、“0 vs 2”……“0 vs n”、“1 vs 2”、“1 vs 3”、“1 vs n”……“n-1 vs n”。
dual_coef_ 的形状为 (n_classes-1, n_SV),布局有点难以理解。列对应于参与任何 n_classes * (n_classes - 1) / 2 个“一对一”分类器的支持向量。每个支持向量 v 在将 v 的类别与另一类别进行比较的 n_classes - 1 个分类器中都有一个对偶系数。请注意,这些对偶系数中的一些(但并非全部)可能为零。n_classes - 1 个条目中的每一个都是这些对偶系数,按相反的类别排序。
举个例子可能更清楚:考虑一个三类问题,类别 0 有三个支持向量 \(v^{0}_0, v^{1}_0, v^{2}_0\),类别 1 和 2 分别有两个支持向量 \(v^{0}_1, v^{1}_1\) 和 \(v^{0}_2, v^{1}_2\)。对于每个支持向量 \(v^{j}_i\),有两个对偶系数。我们称支持向量 \(v^{j}_i\) 在类别 \(i\) 和 \(k\) 之间的分类器中的系数为 \(\alpha^{j}_{i,k}\)。那么 dual_coef_ 看起来像这样
\(\alpha^{0}_{0,1}\) |
\(\alpha^{1}_{0,1}\) |
\(\alpha^{2}_{0,1}\) |
\(\alpha^{0}_{1,0}\) |
\(\alpha^{1}_{1,0}\) |
\(\alpha^{0}_{2,0}\) |
\(\alpha^{1}_{2,0}\) |
\(\alpha^{0}_{0,2}\) |
\(\alpha^{1}_{0,2}\) |
\(\alpha^{2}_{0,2}\) |
\(\alpha^{0}_{1,2}\) |
\(\alpha^{1}_{1,2}\) |
\(\alpha^{0}_{2,1}\) |
\(\alpha^{1}_{2,1}\) |
类别 0 的 SV 系数 |
类别 1 的 SV 系数 |
类别 2 的 SV 系数 |
||||
示例
1.4.1.2. 分数和概率#
SVC 和 NuSVC 的 decision_function 方法为每个样本提供每个类别的分数(在二元情况下,每个样本只有一个分数)。当构造函数选项 probability 设置为 True 时,将启用类成员概率估计(来自方法 predict_proba 和 predict_log_proba)。在二元情况下,概率使用 Platt 缩放[9] 进行校准:对 SVM 的分数进行逻辑回归,通过对训练数据的额外交叉验证进行拟合。在多类情况下,这将根据[10]进行扩展。
注意
通过 CalibratedClassifierCV(参见 概率校准),所有估计器都可以使用相同的概率校准程序。对于 SVC 和 NuSVC,此过程内置于 libsvm 中(在后台使用),因此它不依赖于 scikit-learn 的 CalibratedClassifierCV。
对于大型数据集,Platt 缩放中涉及的交叉验证是一项昂贵的操作。此外,概率估计可能与分数不一致。
分数的“argmax”可能不是概率的 argmax。
在二元分类中,即使
predict_proba的输出小于 0.5,样本也可能被predict标记为属于正类;同样,即使predict_proba的输出大于 0.5,它也可能被标记为负类。
Platt方法也存在一些理论问题。如果需要置信分数,但这些分数不必是概率,那么建议设置probability=False,并使用decision_function代替predict_proba。
请注意,当decision_function_shape='ovr'且n_classes > 2时,与decision_function不同,predict方法默认情况下不会尝试打破平局。您可以设置break_ties=True,使predict的输出与np.argmax(clf.decision_function(...), axis=1)相同,否则将始终返回平局类中的第一个类;但请记住,这会带来计算成本。有关打破平局的示例,请参见SVM打破平局示例。
1.4.1.3. 不平衡问题#
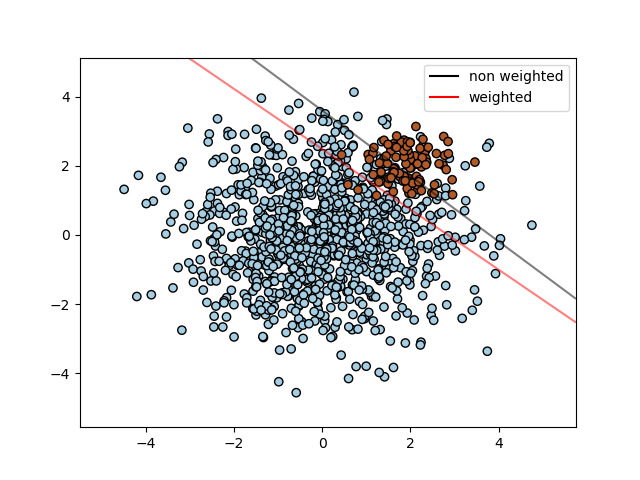
在需要对某些类别或某些单个样本赋予更多权重的问题中,可以使用参数class_weight和sample_weight。
SVC(但不是NuSVC)在fit方法中实现了参数class_weight。它是一个{class_label : value}形式的字典,其中value是一个大于0的浮点数,它将类别class_label的参数C设置为C * value。下图说明了加权和未加权不平衡问题的决策边界。
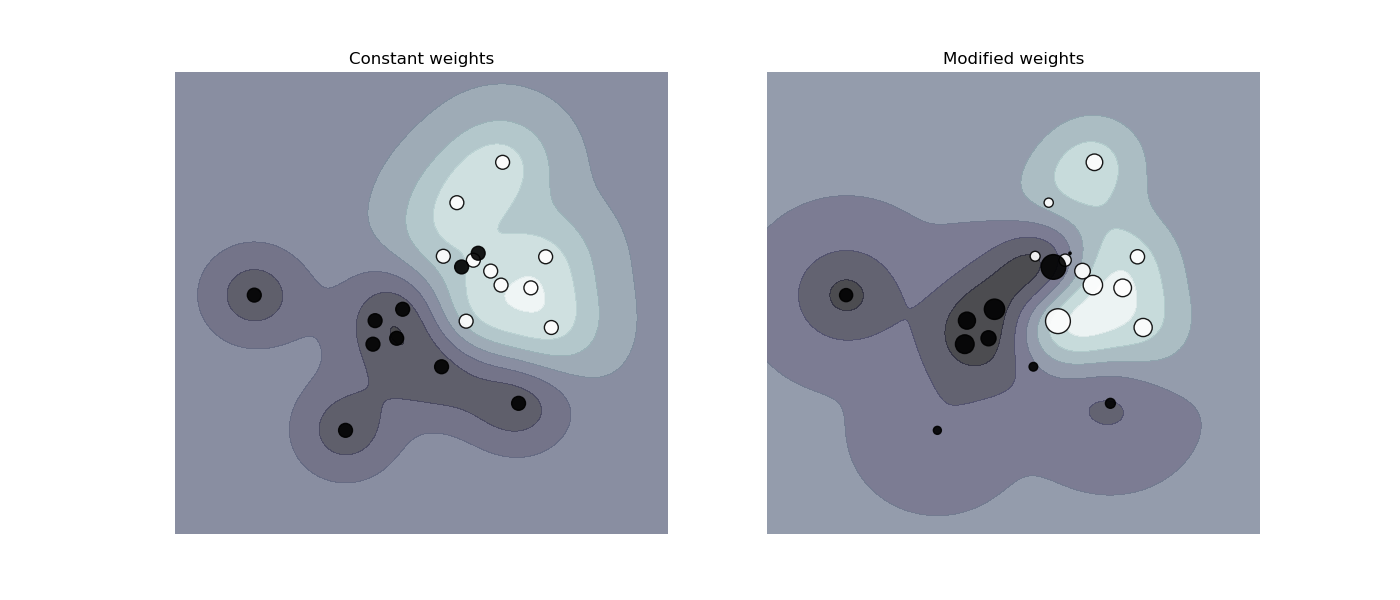
SVC、NuSVC、SVR、NuSVR、LinearSVC、LinearSVR和OneClassSVM也在fit方法中通过sample_weight参数实现了单个样本的权重。与class_weight类似,这将第i个样本的参数C设置为C * sample_weight[i],这将鼓励分类器正确分类这些样本。下图说明了样本加权对决策边界的影響。圆圈的大小与样本权重成正比。
示例
1.4.2. 回归#
支持向量分类的方法可以扩展到解决回归问题。这种方法称为支持向量回归。
支持向量分类产生的模型只依赖于训练数据的一个子集,因为构建模型的代价函数并不关心位于裕度之外的训练点。类似地,支持向量回归产生的模型只依赖于训练数据的一个子集,因为代价函数忽略了预测值与其目标值接近的样本。
支持向量回归有三种不同的实现:SVR、NuSVR和LinearSVR。LinearSVR提供了比SVR更快的实现,但只考虑线性核,而NuSVR的实现方式与SVR和LinearSVR略有不同。由于其在liblinear中的实现,LinearSVR也会对截距进行正则化(如果考虑的话)。然而,可以通过仔细调整其intercept_scaling参数来减少这种影响,这允许截距项与其他特征相比具有不同的正则化行为。因此,分类结果和分数可能与其他两种分类器不同。有关详细信息,请参见实现细节。
与分类类别一样,fit方法将接收参数向量X、y,只是在这种情况下,y预期具有浮点值而不是整数值。
>>> from sklearn import svm
>>> X = [[0, 0], [2, 2]]
>>> y = [0.5, 2.5]
>>> regr = svm.SVR()
>>> regr.fit(X, y)
SVR()
>>> regr.predict([[1, 1]])
array([1.5])
示例
1.4.3. 密度估计,新颖性检测#
类OneClassSVM实现了一种用于异常值检测的一类SVM。
有关OneClassSVM的描述和用法,请参见新颖性和异常值检测。
1.4.4. 复杂度#
支持向量机 (SVM) 是一种强大的工具,但是其计算和存储需求会随着训练向量数量的增加而迅速增长。SVM 的核心是一个二次规划问题 (QP),用于将支持向量与其余训练数据分离。基于 libsvm 的实现所使用的 QP 求解器,其缩放比例介于 \(O(n_{features} \times n_{samples}^2)\) 和 \(O(n_{features} \times n_{samples}^3)\) 之间,具体取决于 libsvm 缓存的实际使用效率(取决于数据集)。如果数据非常稀疏,则应将 \(n_{features}\) 替换为样本向量中非零特征的平均数量。
对于线性情况,LinearSVC 中 liblinear 实现所使用的算法比其基于 libsvm 的 SVC 对等物高效得多,并且可以几乎线性地扩展到数百万个样本和/或特征。
1.4.5. 实用技巧#
避免数据复制:对于
SVC、SVR、NuSVC和NuSVR,如果传递给某些方法的数据不是 C 顺序连续的双精度数据,则在调用底层 C 实现之前会复制该数据。可以通过检查其flags属性来检查给定的 numpy 数组是否是 C 连续的。对于
LinearSVC(和LogisticRegression),任何作为 numpy 数组传入的输入都将被复制并转换为 liblinear 内部稀疏数据表示(双精度浮点数和非零分量的 int32 索引)。如果您想拟合大型线性分类器而无需将密集的 numpy C 连续双精度数组作为输入复制,建议改用SGDClassifier类。目标函数可以配置为与LinearSVC模型几乎相同。内核缓存大小:对于
SVC、SVR、NuSVC和NuSVR,内核缓存的大小对较大问题的运行时间有很大影响。如果您有足够的可用 RAM,建议将cache_size设置为高于默认值 200(MB) 的值,例如 500(MB) 或 1000(MB)。设置 C:
C默认值为1,这是一个合理的默认选择。如果您有很多噪声观测值,则应降低它:降低 C 对应于更多的正则化。LinearSVC和LinearSVR对C的敏感性较低,当它变大时,预测结果会在某个阈值后停止改进。同时,较大的C值将需要更多的时间来训练,有时长达 10 倍,如 [11] 所示。支持向量机算法不是尺度不变的,因此强烈建议缩放您的数据。例如,将输入向量 X 上的每个属性缩放至 [0,1] 或 [-1,+1],或将其标准化为均值为 0 方差为 1。请注意,必须对测试向量应用相同的缩放比例才能获得有意义的结果。这可以通过使用
Pipeline轻松完成。>>> from sklearn.pipeline import make_pipeline >>> from sklearn.preprocessing import StandardScaler >>> from sklearn.svm import SVC >>> clf = make_pipeline(StandardScaler(), SVC())
有关缩放和规范化的更多详细信息,请参见第 预处理数据 节。
关于
shrinking参数,引用 [12]:我们发现,如果迭代次数很大,则收缩可以缩短训练时间。但是,如果我们松散地求解优化问题(例如,通过使用较大的停止容差),则不使用收缩的代码可能会快得多参数
nu在NuSVC/OneClassSVM/NuSVR中近似于训练误差和支持向量的比例。在
SVC中,如果数据不平衡(例如,正样本很多而负样本很少),请设置class_weight='balanced'和/或尝试不同的惩罚参数C。底层实现的随机性:
SVC和NuSVC的底层实现仅使用随机数生成器来混洗数据以进行概率估计(当probability设置为True时)。这种随机性可以通过random_state参数控制。如果probability设置为False,则这些估计器不是随机的,random_state不会影响结果。OneClassSVM的底层实现类似于SVC和NuSVC。由于OneClassSVM不提供概率估计,因此它不是随机的。底层
LinearSVC实现使用随机数生成器在使用对偶坐标下降拟合模型时选择特征(即,当dual设置为True时)。因此,对于相同输入数据获得略微不同的结果并不罕见。如果发生这种情况,请尝试使用较小的tol参数。这种随机性也可以通过random_state参数控制。当dual设置为False时,LinearSVC的底层实现不是随机的,random_state不会影响结果。使用
LinearSVC(penalty='l1', dual=False)提供的L1惩罚可以产生稀疏解,即只有一部分特征权重不同于零并有助于决策函数。增加C会产生更复杂的模型(选择更多特征)。可以使用l1_min_c计算产生“空”模型(所有权重都等于零)的C值。
1.4.6. 核函数#
核函数可以是以下任何一种:
线性:\(\langle x, x'\rangle\)。
多项式:\((\gamma \langle x, x'\rangle + r)^d\),其中\(d\)由参数
degree指定,\(r\)由coef0指定。RBF:\(\exp(-\gamma \|x-x'\|^2)\),其中\(\gamma\)由参数
gamma指定,必须大于0。Sigmoid \(\tanh(\gamma \langle x,x'\rangle + r)\),其中\(r\)由
coef0指定。
不同的核函数由kernel参数指定。
>>> linear_svc = svm.SVC(kernel='linear')
>>> linear_svc.kernel
'linear'
>>> rbf_svc = svm.SVC(kernel='rbf')
>>> rbf_svc.kernel
'rbf'
另请参阅核近似,了解使用RBF核函数的更快、更可扩展的解决方案。
1.4.6.1. RBF核的参数#
使用径向基函数(RBF)核训练SVM时,必须考虑两个参数:C和gamma。C参数对所有SVM核函数都适用,它权衡了训练样本的误分类与决策面的简单性。较低的C使决策面平滑,而较高的C则旨在正确分类所有训练样本。gamma定义单个训练样本的影响程度。gamma越大,其他样本必须越接近才能受到影响。
正确选择C和gamma对于SVM的性能至关重要。建议使用GridSearchCV,并以指数间隔分布C和gamma来选择合适的数值。
示例
1.4.6.2. 自定义核函数#
您可以通过将核函数作为python函数提供或预计算Gram矩阵来定义自己的核函数。
使用自定义核函数的分类器与其他分类器的行为方式相同,只是
字段
support_vectors_现在为空,仅在support_中存储支持向量的索引。fit()方法的第一个参数的引用(而非副本)将被存储以供将来参考。如果在使用fit()和predict()之间该数组发生更改,则结果将出乎意料。
使用 Python 函数作为核函数#
可以通过将函数传递给 kernel 参数来使用您自己定义的核函数。
您的核函数必须接受形状为 (n_samples_1, n_features) 和 (n_samples_2, n_features) 的两个矩阵作为参数,并返回形状为 (n_samples_1, n_samples_2) 的核矩阵。
以下代码定义了一个线性核函数,并创建一个将使用该核函数的分类器实例。
>>> import numpy as np
>>> from sklearn import svm
>>> def my_kernel(X, Y):
... return np.dot(X, Y.T)
...
>>> clf = svm.SVC(kernel=my_kernel)
使用 Gram 矩阵#
可以通过使用 kernel='precomputed' 选项来传递预计算的核函数。然后,您应该将 Gram 矩阵而不是 X 传递给 fit 和 predict 方法。必须提供所有训练向量和测试向量之间的核值。
>>> import numpy as np
>>> from sklearn.datasets import make_classification
>>> from sklearn.model_selection import train_test_split
>>> from sklearn import svm
>>> X, y = make_classification(n_samples=10, random_state=0)
>>> X_train , X_test , y_train, y_test = train_test_split(X, y, random_state=0)
>>> clf = svm.SVC(kernel='precomputed')
>>> # linear kernel computation
>>> gram_train = np.dot(X_train, X_train.T)
>>> clf.fit(gram_train, y_train)
SVC(kernel='precomputed')
>>> # predict on training examples
>>> gram_test = np.dot(X_test, X_train.T)
>>> clf.predict(gram_test)
array([0, 1, 0])
示例
1.4.7. 数学公式#
支持向量机在高维或无限维空间中构建超平面或超平面集,可用于分类、回归或其他任务。直观地说,最佳分离是通过与任何类别最近的训练数据点距离最大的超平面(所谓的函数间隔)来实现的,因为通常情况下,间隔越大,分类器的泛化误差越低。下图显示了线性可分问题的决策函数,其中三个样本位于边界上,称为“支持向量”。
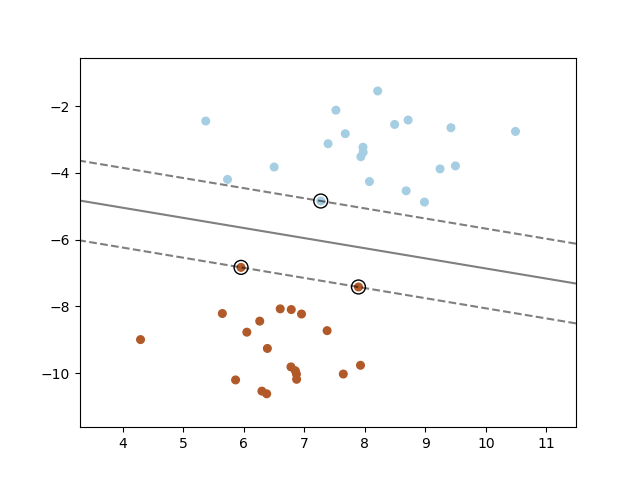
通常,当问题不是线性可分时,支持向量是位于边界*内部*的样本。
我们推荐 [13] 和 [14] 作为 SVM 理论和实践的良好参考。
1.4.7.1. SVC#
给定两个类别中的训练向量 \(x_i \in \mathbb{R}^p\),i=1,…, n,以及向量 \(y \in \{1, -1\}^n\),我们的目标是找到 \(w \in \mathbb{R}^p\) 和 \(b \in \mathbb{R}\),使得由 \(\text{sign} (w^T\phi(x) + b)\) 给出的预测对于大多数样本都是正确的。
SVC 求解以下原始问题:
直观地说,我们试图最大化间隔(通过最小化 \(||w||^2 = w^Tw\)),同时在样本被误分类或位于间隔边界内时产生惩罚。理想情况下,值 \(y_i (w^T \phi (x_i) + b)\) 对所有样本都将 \(\geq 1\),这表示完美的预测。但问题通常并非总是可以用超平面完美地分离,因此我们允许一些样本与其正确的边界距离为 \(\zeta_i\)。惩罚项 C 控制此惩罚的强度,因此充当反向正则化参数(参见下面的说明)。
原始问题的对偶问题是:
其中 \(e\) 是全为一的向量,\(Q\) 是一个 \(n\) 乘 \(n\) 的半正定矩阵,\(Q_{ij} \equiv y_i y_j K(x_i, x_j)\),其中 \(K(x_i, x_j) = \phi (x_i)^T \phi (x_j)\) 是核函数。项 \(\alpha_i\) 称为对偶系数,它们的上限为 \(C\)。这种对偶表示突出了这样一个事实:训练向量通过函数 \(\phi\) 隐式地映射到更高(可能是无限)维的空间:参见 核技巧。
一旦优化问题得到解决,给定样本 \(x\) 的 决策函数 的输出变为:
预测的类别对应于其符号。我们只需要对支持向量(即位于边界内的样本)求和,因为对于其他样本,对偶系数 \(\alpha_i\) 为零。
这些参数可以通过属性 dual_coef_(保存乘积 \(y_i \alpha_i\))、support_vectors_(保存支持向量)和 intercept_(保存独立项 \(b\))访问。
注意
虽然源自libsvm和liblinear的SVM模型使用C作为正则化参数,但大多数其他估计器使用alpha。两个模型正则化程度的精确等价性取决于模型优化的精确目标函数。例如,当使用的估计器是Ridge回归时,它们之间的关系为\(C = \frac{1}{alpha}\)。
LinearSVC#
1.4.7.2. SVR#
给定训练向量\(x_i \in \mathbb{R}^p\),i=1,…, n,和向量\(y \in \mathbb{R}^n\),\(\varepsilon\)-SVR求解以下原始问题
在这里,我们对预测结果至少偏离其真实目标\(\varepsilon\)的样本进行惩罚。这些样本通过\(\zeta_i\)或\(\zeta_i^*\)对目标函数进行惩罚,这取决于它们的预测结果是高于还是低于\(\varepsilon\)区间。
对偶问题是
其中\(e\)是全为一的向量,\(Q\)是一个\(n\)乘\(n\)的半正定矩阵,\(Q_{ij} \equiv K(x_i, x_j) = \phi (x_i)^T \phi (x_j)\)是核函数。在这里,训练向量通过函数\(\phi\)隐式地映射到更高(可能无限)维的空间。
预测结果为
这些参数可以通过属性dual_coef_访问,它保存差值\(\alpha_i - \alpha_i^*\);support_vectors_,它保存支持向量;以及intercept_,它保存独立项\(b\)。
1.4.8. 实现细节#
在内部,我们使用libsvm [12]和liblinear [11]来处理所有计算。这些库使用C和Cython进行封装。有关实现的描述和所用算法的详细信息,请参阅其各自的论文。
参考文献