1.7. 高斯过程#
高斯过程 (GP) 是一种非参数监督学习方法,用于解决回归和概率分类问题。
高斯过程的优点包括:
预测内插观测值(至少对于常规核而言)。
预测是概率性的(高斯分布),因此可以计算经验置信区间,并根据这些区间决定是否应该在某些感兴趣的区域重新拟合(在线拟合、自适应拟合)预测。
用途广泛:可以指定不同的核。提供了常见的核,但也可以指定自定义核。
高斯过程的缺点包括:
我们的实现不是稀疏的,即它们使用整个样本/特征信息来执行预测。
它们在高维空间中效率降低——即当特征数量超过几十个时。
1.7.1. 高斯过程回归 (GPR)#
GaussianProcessRegressor实现了用于回归目的的高斯过程 (GP)。为此,需要指定 GP 的先验。GP 将结合此先验和基于训练样本的似然函数。它允许通过在预测时给出均值和标准差作为输出,对预测进行概率性方法。
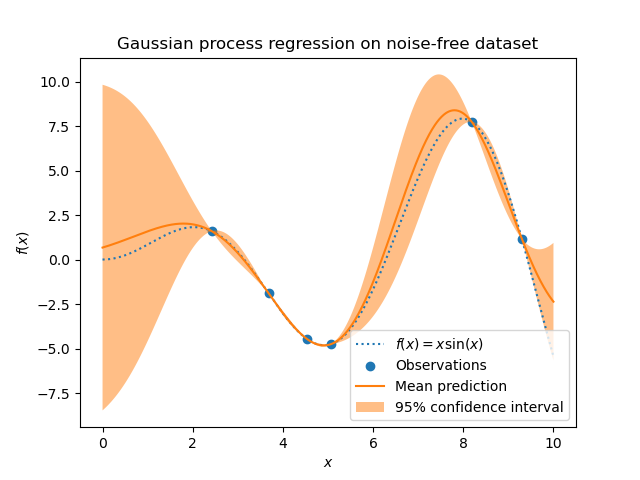
假设先验均值为常数且为零(对于normalize_y=False)或训练数据的均值(对于normalize_y=True)。先验的协方差通过传递核对象来指定。在拟合GaussianProcessRegressor时,通过基于传递的optimizer最大化对数边际似然 (LML) 来优化核的超参数。由于 LML 可能有多个局部最优值,因此可以通过指定n_restarts_optimizer来重复启动优化器。第一次运行始终从核的初始超参数值开始;后续运行从在允许值的范围内随机选择的超参数值开始。如果应保持初始超参数不变,则可以将None作为优化器传递。
目标中的噪声水平可以通过参数alpha来指定,可以全局地作为标量指定,也可以按数据点指定。请注意,适度的噪声水平也有助于处理拟合过程中的数值不稳定性,因为它实际上是作为 Tikhonov 正则化实现的,即通过将其添加到核矩阵的对角线上。显式指定噪声水平的另一种方法是将WhiteKernel组件包含到核中,它可以从数据中估计全局噪声水平(参见下面的示例)。下图显示了通过设置参数alpha处理的噪声目标的影响。
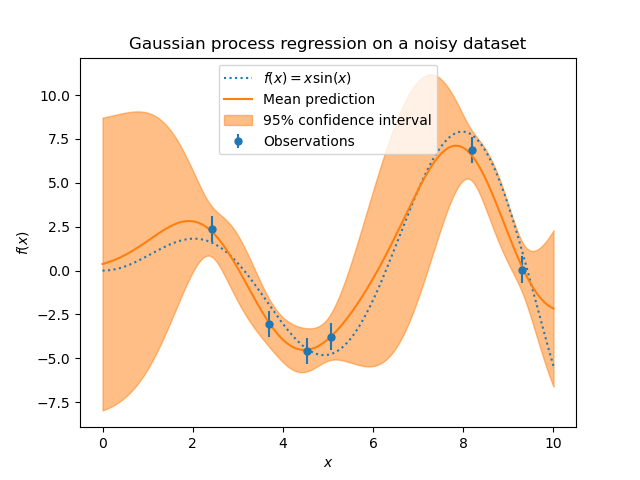
该实现基于[RW2006]的算法 2.1。除了标准 scikit-learn 估计器的 API 外,GaussianProcessRegressor
允许在先验拟合(基于 GP 先验)之前进行预测
提供了一种附加方法
sample_y(X),该方法评估从给定输入处的 GPR(先验或后验)中抽取的样本公开了一种方法
log_marginal_likelihood(theta),该方法可用于其他选择超参数的方法,例如通过马尔可夫链蒙特卡罗方法。
示例
1.7.2. 高斯过程分类 (GPC)#
高斯过程分类器 (GaussianProcessClassifier) 使用高斯过程 (GP) 进行分类,更具体地说,是进行概率分类,其中测试预测结果采用类概率的形式。高斯过程分类器在潜在函数 \(f\) 上放置一个 GP 先验,然后通过链接函数将其压缩以获得概率分类。潜在函数 \(f\) 是所谓的干扰函数,其值未被观察到,本身也不相关。其目的是允许对模型进行方便的公式化,并且在预测过程中会移除(积分)\(f\)。高斯过程分类器实现逻辑链接函数,对于该函数,积分无法通过分析计算,但在二元情况下很容易近似。
与回归设置相反,即使对于 GP 先验,潜在函数 \(f\) 的后验也不是高斯的,因为高斯似然函数不适用于离散类标签。相反,使用与逻辑链接函数(logit)相对应的非高斯似然函数。高斯过程分类器基于拉普拉斯近似,用高斯近似非高斯后验。更多细节可以在 [RW2006] 的第 3 章中找到。
假设 GP 先验均值为零。先验的协方差通过传递 核函数 对象来指定。通过基于传递的 optimizer 最大化对数边际似然 (LML),在高斯过程回归器的拟合过程中优化核函数的超参数。由于 LML 可能有多个局部最优值,因此可以通过指定 n_restarts_optimizer 来重复启动优化器。第一次运行总是从内核的初始超参数值开始;后续运行是从在允许值的范围内随机选择的超参数值开始的。如果应保持初始超参数不变,则可以将 None 作为优化器传递。
GaussianProcessClassifier 通过执行基于一对多或一对一训练和预测来支持多类分类。在一对多方法中,为每个类别拟合一个二元高斯过程分类器,该分类器被训练以将该类别与其余类别分开。“一对一”方法中,为每一对类别拟合一个二元高斯过程分类器,该分类器被训练以将这两个类别分开。这些二元预测器的预测结果被组合成多类预测结果。有关更多详细信息,请参阅关于 多类分类 的部分。
在高斯过程分类的情况下,“一对一”方法在计算上可能更便宜,因为它必须解决许多仅涉及整个训练集子集的问题,而不是在整个数据集上解决较少的问题。由于高斯过程分类的计算量随数据集大小的三次方成比例增加,因此这可能会快得多。但是,请注意,“一对一”方法不支持预测概率估计,而只支持简单的预测。此外,请注意 GaussianProcessClassifier 尚未(尚未)在内部实现真正的多类拉普拉斯近似,但如上所述,它是基于在内部求解多个二元分类任务,这些任务使用一对多或一对一方法进行组合。
1.7.3. GPC 示例#
1.7.3.1. GPC 的概率预测#
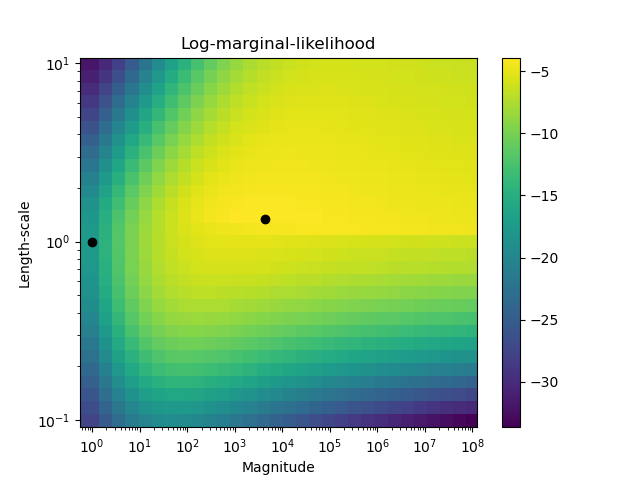
此示例说明了对于具有不同超参数选择的 RBF 核的 GPC 的预测概率。第一张图显示了具有任意选择的超参数和与最大对数边际似然 (LML) 相对应的超参数的 GPC 的预测概率。
虽然通过优化 LML 选择的超参数具有相当大的 LML,但根据测试数据的对数损失,它们的性能略差。该图显示这是因为它们在类边界处表现出类概率的急剧变化(这很好),但在远离类边界的地方预测概率接近 0.5(这不好)。这种不良影响是由 GPC 内部使用的拉普拉斯近似引起的。
第二张图显示了不同核函数超参数选择的对数边际似然,用黑点突出显示了第一张图中使用的两种超参数选择。
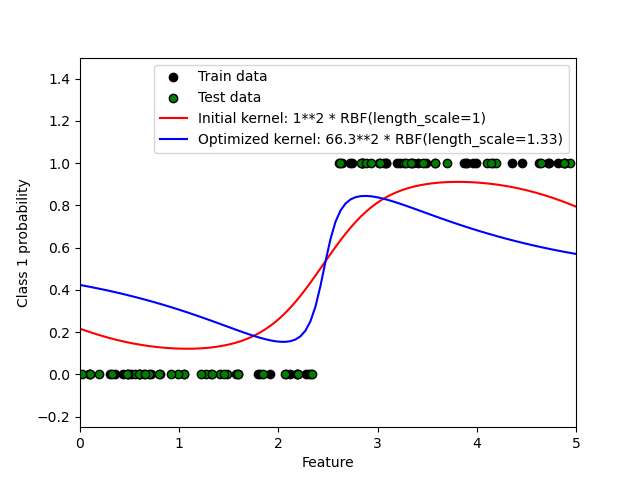
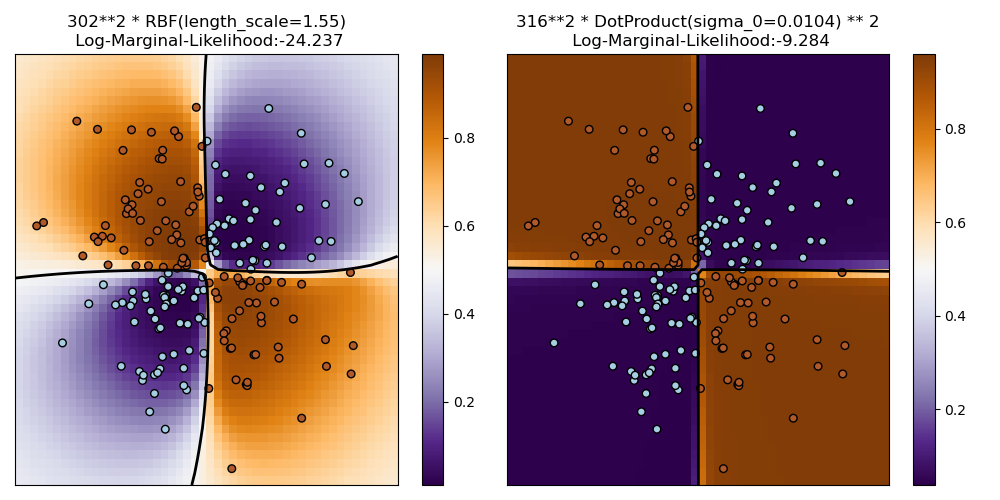
1.7.3.2. 在 XOR 数据集上说明 GPC#
此示例在 XOR 数据上说明了 GPC。比较了平稳各向同性核 (RBF) 和非平稳核 (DotProduct)。在这个特定数据集上,DotProduct 核获得了更好的结果,因为类边界是线性的并且与坐标轴重合。然而,在实践中,平稳核如 RBF 通常会获得更好的结果。
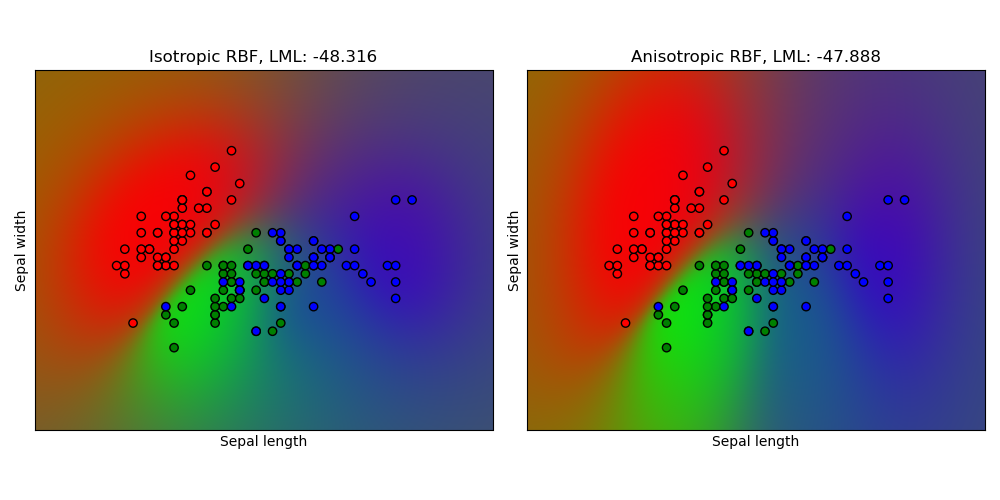
1.7.3.3. 鸢尾花数据集上的高斯过程分类 (GPC)#
此示例说明了在鸢尾花数据集的二维版本上,针对各向同性和各向异性 RBF 核的 GPC 的预测概率。这说明了 GPC 对非二元分类的适用性。各向异性 RBF 核通过为两个特征维度分配不同的长度尺度来获得略高的对数边际似然。
1.7.4. 高斯过程的核函数#
核函数(在 GP 的背景下也称为“协方差函数”)是 GP 的一个重要组成部分,它决定了 GP 先验和后验的形状。它们通过定义两个数据点的“相似性”并结合类似数据点应具有类似目标值的假设来编码对被学习函数的假设。可以区分两类核函数:平稳核函数仅取决于两个数据点的距离,而不取决于它们的绝对值 \(k(x_i, x_j)= k(d(x_i, x_j))\),因此对于输入空间中的平移是不变的,而非平稳核函数还取决于数据点的具体值。平稳核函数可以进一步细分为各向同性和各向异性核函数,其中各向同性核函数对于输入空间中的旋转也是不变的。有关更多详细信息,请参阅 [RW2006] 的第 4 章。关于如何最好地组合不同核函数的指导,请参阅 [Duv2014]。
高斯过程核API#
Kernel 的主要用途是计算GP中数据点之间的协方差。为此,可以调用核的 __call__ 方法。此方法可以用于计算二维数组X中所有数据点对的“自协方差”,或者计算二维数组X中的数据点与二维数组Y中的数据点所有组合的“互协方差”。对于所有核k(WhiteKernel 除外),都成立以下恒等式:k(X) == K(X, Y=X)
如果只需要自协方差的对角线,则可以调用核的 diag() 方法,这比等效的 __call__ 调用更高效:np.diag(k(X, X)) == k.diag(X)
核由超参数向量\(\theta\) 参数化。例如,这些超参数可以控制核的长度尺度或周期性(见下文)。所有核都支持计算核自协方差关于\(log(\theta)\) 的解析梯度,方法是在 __call__ 方法中设置 eval_gradient=True。也就是说,返回一个 (len(X), len(X), len(theta)) 数组,其中条目 [i, j, l] 包含\(\frac{\partial k_\theta(x_i, x_j)}{\partial log(\theta_l)}\)。高斯过程(回归器和分类器)在计算对数边际似然的梯度时使用此梯度,而对数边际似然的梯度又用于通过梯度上升确定\(\theta\) 的值,该值使对数边际似然最大化。对于每个超参数,在创建核实例时需要指定初始值和边界。可以通过核对象的 theta 属性获取和设置\(\theta\) 的当前值。此外,可以通过核的 bounds 属性访问超参数的边界。请注意,这两个属性(theta 和 bounds)都返回内部使用值的 log 变换值,因为这些值通常更易于基于梯度的优化。每个超参数的规范以Hyperparameter 实例的形式存储在相应的核中。请注意,使用名为“x”的超参数的核必须具有属性 self.x 和 self.x_bounds。
所有核的抽象基类是Kernel。Kernel 实现与BaseEstimator 类似的接口,提供 get_params()、set_params() 和 clone() 方法。这允许通过元估计器(例如Pipeline 或GridSearchCV)来设置核值。请注意,由于核的嵌套结构(通过应用核算子,见下文),核参数的名称可能会变得相对复杂。一般来说,对于二元核算子,左操作数的参数以 k1__ 为前缀,右操作数的参数以 k2__ 为前缀。还有一个方便的方法是 clone_with_theta(theta),它返回核的克隆版本,但超参数设置为 theta。一个说明性的例子
>>> from sklearn.gaussian_process.kernels import ConstantKernel, RBF
>>> kernel = ConstantKernel(constant_value=1.0, constant_value_bounds=(0.0, 10.0)) * RBF(length_scale=0.5, length_scale_bounds=(0.0, 10.0)) + RBF(length_scale=2.0, length_scale_bounds=(0.0, 10.0))
>>> for hyperparameter in kernel.hyperparameters: print(hyperparameter)
Hyperparameter(name='k1__k1__constant_value', value_type='numeric', bounds=array([[ 0., 10.]]), n_elements=1, fixed=False)
Hyperparameter(name='k1__k2__length_scale', value_type='numeric', bounds=array([[ 0., 10.]]), n_elements=1, fixed=False)
Hyperparameter(name='k2__length_scale', value_type='numeric', bounds=array([[ 0., 10.]]), n_elements=1, fixed=False)
>>> params = kernel.get_params()
>>> for key in sorted(params): print("%s : %s" % (key, params[key]))
k1 : 1**2 * RBF(length_scale=0.5)
k1__k1 : 1**2
k1__k1__constant_value : 1.0
k1__k1__constant_value_bounds : (0.0, 10.0)
k1__k2 : RBF(length_scale=0.5)
k1__k2__length_scale : 0.5
k1__k2__length_scale_bounds : (0.0, 10.0)
k2 : RBF(length_scale=2)
k2__length_scale : 2.0
k2__length_scale_bounds : (0.0, 10.0)
>>> print(kernel.theta) # Note: log-transformed
[ 0. -0.69314718 0.69314718]
>>> print(kernel.bounds) # Note: log-transformed
[[ -inf 2.30258509]
[ -inf 2.30258509]
[ -inf 2.30258509]]
所有高斯过程核都可与sklearn.metrics.pairwise 互操作,反之亦然:Kernel 的子类的实例可以作为 metric 传递给sklearn.metrics.pairwise 中的 pairwise_kernels。此外,来自 pairwise 的核函数可以通过使用包装类PairwiseKernel 作为 GP 核。唯一的警告是超参数的梯度不是解析的而是数值的,并且所有这些核只支持各向同性距离。gamma 参数被认为是一个超参数,可以进行优化。其他核参数在初始化时直接设置,并保持不变。
1.7.4.1. 基本核#
ConstantKernel 核可以作为 Product 核的一部分,它可以缩放其他因子(核)的幅度;也可以作为 Sum 核的一部分,它可以修改高斯过程的均值。它依赖于参数 \(constant\_value\)。其定义为:
WhiteKernel 核的主要用途是作为求和核的一部分,它解释了信号的噪声成分。调整其参数 \(noise\_level\) 相当于估计噪声水平。其定义为:
1.7.4.2. 核运算符#
核运算符接受一个或两个基核,并将它们组合成一个新的核。Sum 核接受两个核 \(k_1\) 和 \(k_2\),并通过 \(k_{sum}(X, Y) = k_1(X, Y) + k_2(X, Y)\) 将它们组合。Product 核接受两个核 \(k_1\) 和 \(k_2\),并通过 \(k_{product}(X, Y) = k_1(X, Y) * k_2(X, Y)\) 将它们组合。Exponentiation 核接受一个基核和一个标量参数 \(p\),并通过 \(k_{exp}(X, Y) = k(X, Y)^p\) 将它们组合。请注意,在核对象上覆盖了魔术方法 __add__、__mul___ 和 __pow__,因此可以使用例如 RBF() + RBF() 作为 Sum(RBF(), RBF()) 的快捷方式。
1.7.4.3. 径向基函数 (RBF) 核#
RBF 核是一个平稳核。它也称为“平方指数”核。它由长度尺度参数 \(l>0\) 参数化,该参数可以是标量(核的各向同性变体),也可以是与输入 \(x\) 维数相同的向量(核的各向异性变体)。该核由下式给出:
其中 \(d(\cdot, \cdot)\) 是欧几里得距离。这个核是无限可微的,这意味着具有该核作为协方差函数的 GPs 具有所有阶的均方导数,因此非常平滑。下图显示了由 RBF 核产生的 GP 的先验和后验。
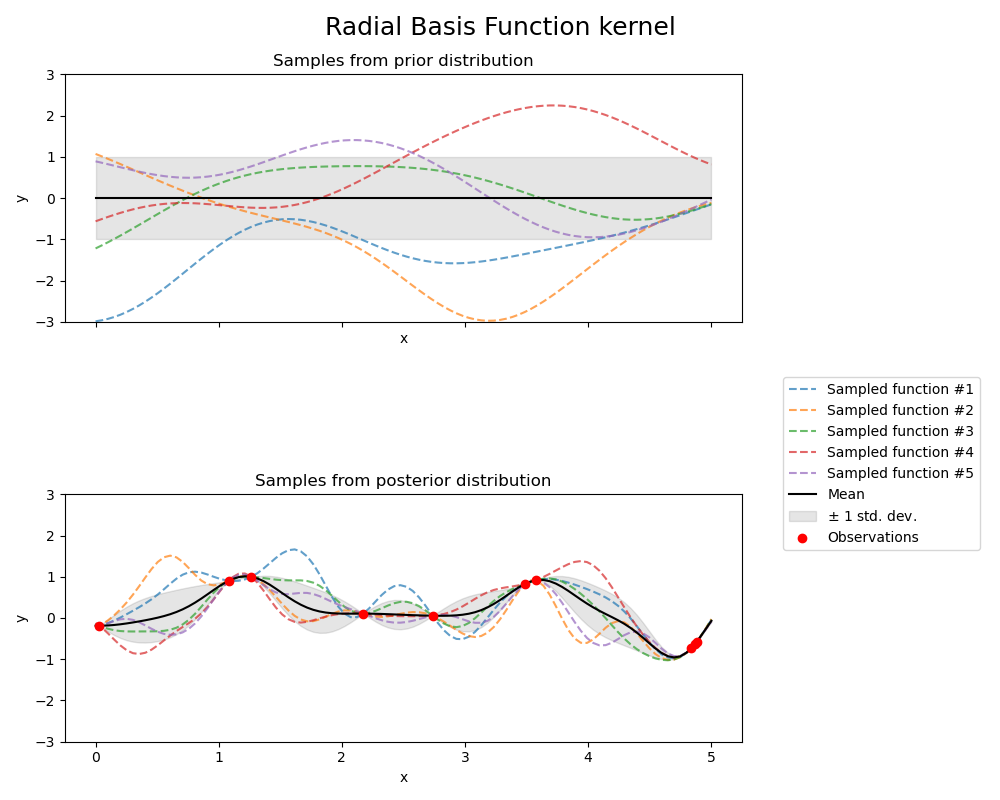
1.7.4.4. Matérn 核#
Matern 核是一个平稳核,也是 RBF 核的推广。它还有一个附加参数 \(\nu\),它控制生成的函数的平滑度。它由长度尺度参数 \(l>0\) 参数化,该参数可以是标量(核的各向同性变体),也可以是与输入 \(x\) 维数相同的向量(核的各向异性变体)。
Matérn 核的数学实现#
该核由下式给出:
其中 \(d(\cdot,\cdot)\) 是欧几里得距离,\(K_\nu(\cdot)\) 是修正的贝塞尔函数,\(\Gamma(\cdot)\) 是伽马函数。当 \(\nu\rightarrow\infty\) 时,Matérn 核收敛到 RBF 核。当 \(\nu = 1/2\) 时,Matérn 核与绝对指数核相同,即:
特别是,\(\nu = 3/2\)
和 \(\nu = 5/2\)
是学习非无限可微(如 RBF 核假设)但至少一次(\(\nu = 3/2\))或两次可微(\(\nu = 5/2\))的函数的常用选择。
通过 \(\nu\) 控制学习函数的平滑度的灵活性允许适应真实底层函数关系的属性。
下图显示了由 Matérn 核产生的 GP 的先验和后验。
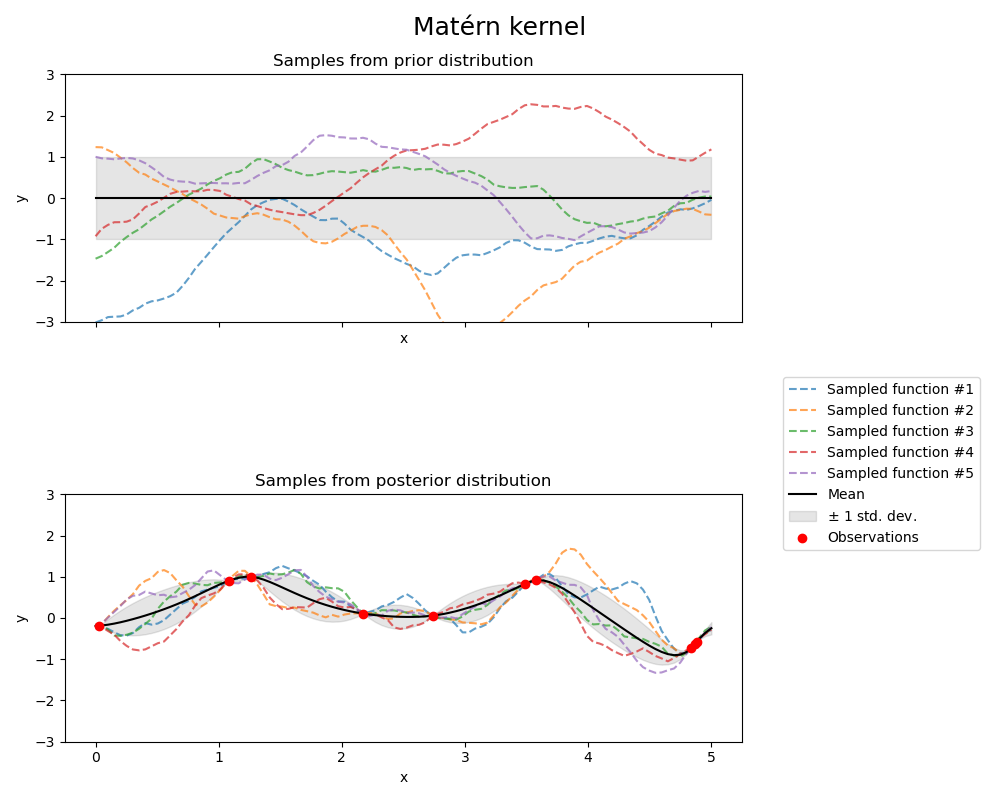
关于Matérn核的不同变体,详情请参见[RW2006],第84页。
1.7.4.5. 有理二次核#
RationalQuadratic 核可以看作是不同特征长度尺度的RBF 核的尺度混合(无限和)。它由长度尺度参数\(l>0\)和尺度混合参数\(\alpha>0\)参数化。目前仅支持\(l\)为标量的各向同性变体。该核由下式给出:
由RationalQuadratic 核产生的GP的先验和后验在下图中显示
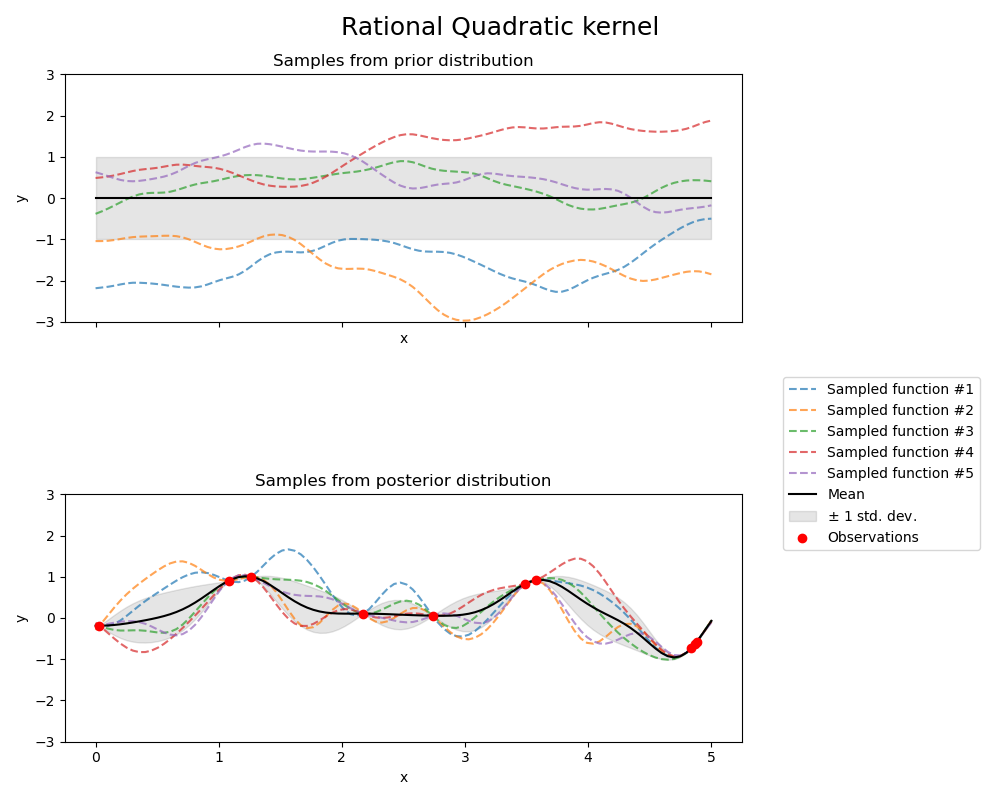
1.7.4.6. 指数正弦平方核#
ExpSineSquared 核允许对周期性函数进行建模。它由长度尺度参数\(l>0\)和周期性参数\(p>0\)参数化。目前仅支持\(l\)为标量的各向同性变体。该核由下式给出:
由指数正弦平方核产生的GP的先验和后验在下图中显示
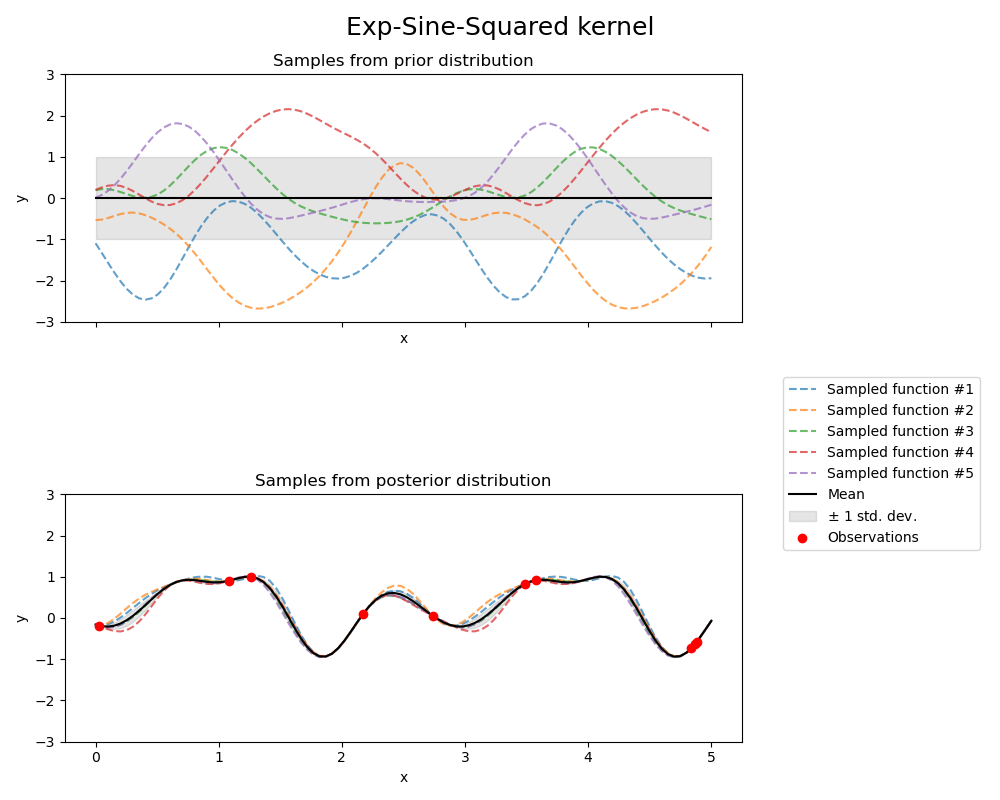
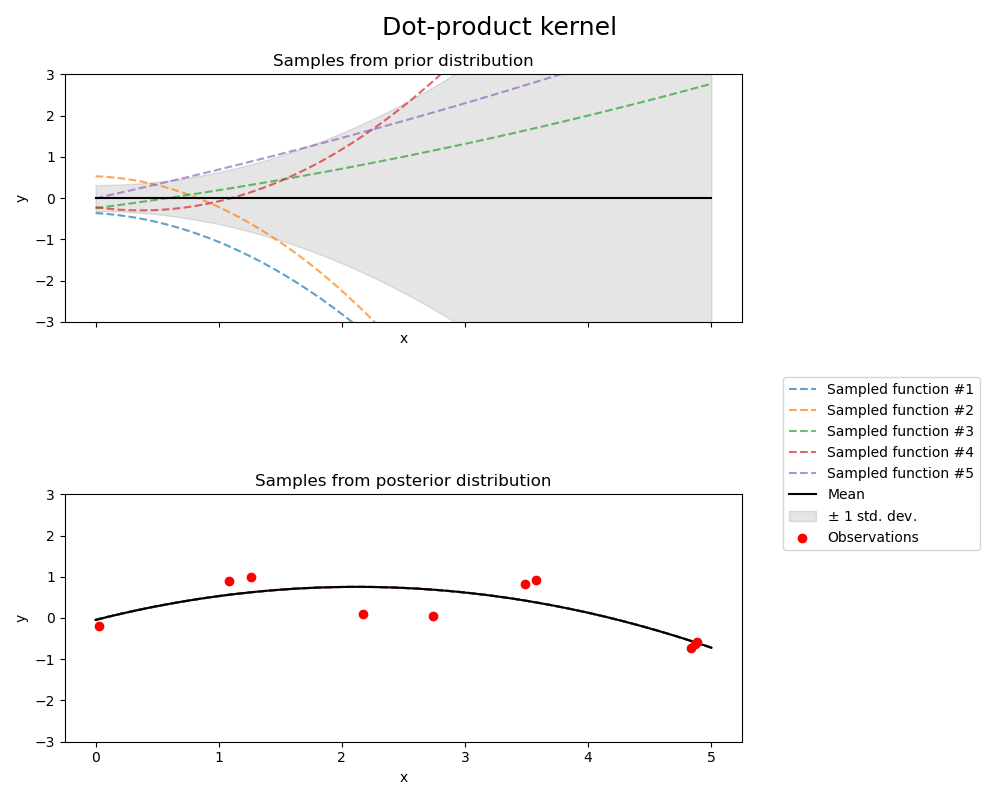
1.7.4.7. 点积核#
DotProduct 核是非平稳的,可以通过对\(x_d (d = 1, . . . , D)\)的系数施加\(N(0, 1)\)先验和对偏差施加\(N(0, \sigma_0^2)\)先验从线性回归中获得。DotProduct 核对原点周围坐标的旋转不变,但对平移不变。它由参数\(\sigma_0^2\)参数化。对于\(\sigma_0^2 = 0\),该核称为齐次线性核,否则为非齐次。该核由下式给出:
DotProduct 核通常与指数运算组合使用。指数为2的示例在下图中显示