1.17. 神经网络模型(监督式)#
警告
此实现并非旨在用于大型应用。特别是,scikit-learn 没有提供 GPU 支持。对于更快、基于 GPU 的实现,以及提供更多构建深度学习架构灵活性的框架,请参见 相关项目。
1.17.1. 多层感知器#
**多层感知器 (MLP)** 是一种监督学习算法,它通过在一个数据集上进行训练来学习一个函数 \(f: R^m \rightarrow R^o\),其中 \(m\) 是输入的维度数,\(o\) 是输出的维度数。给定一组特征 \(X = {x_1, x_2, ..., x_m}\) 和目标 \(y\),它可以学习用于分类或回归的非线性函数逼近器。它与逻辑回归的不同之处在于,在输入层和输出层之间可以存在一个或多个非线性层,称为隐藏层。图 1 显示了一个具有标量输出的单隐藏层 MLP。
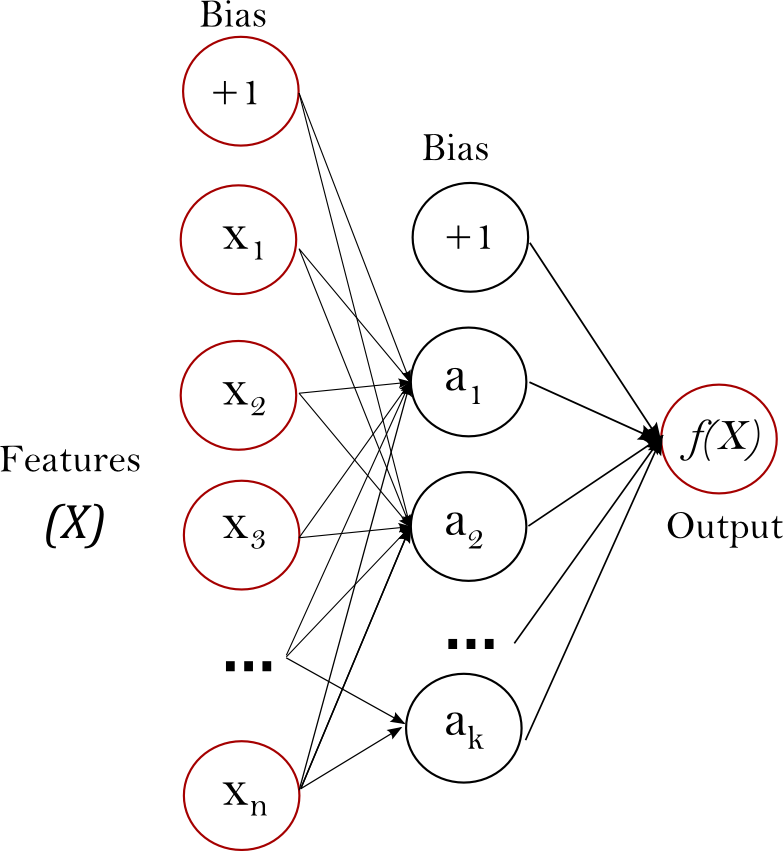
图 1:单隐藏层 MLP。#
最左边的层,称为输入层,由一组神经元 \(\{x_i | x_1, x_2, ..., x_m\}\) 组成,表示输入特征。隐藏层中的每个神经元都使用加权线性求和 \(w_1x_1 + w_2x_2 + ... + w_mx_m\) 转换来自前一层的数值,然后是一个非线性激活函数 \(g(\cdot):R \rightarrow R\)——例如双曲正切函数。输出层接收来自最后一隐藏层的数值并将它们转换为输出数值。
该模块包含公共属性 coefs_ 和 intercepts_。coefs_ 是权重矩阵列表,其中索引为 \(i\) 的权重矩阵表示层 \(i\) 和层 \(i+1\) 之间的权重。intercepts_ 是偏差向量列表,其中索引为 \(i\) 的向量表示添加到层 \(i+1\) 的偏差值。
1.17.2. 分类#
类MLPClassifier实现了一个多层感知器 (MLP) 算法,该算法使用反向传播进行训练。
MLP 在两个数组上进行训练:大小为 (n_samples, n_features) 的数组 X,其中包含表示为浮点特征向量的训练样本;以及大小为 (n_samples,) 的数组 y,其中包含训练样本的目标值(类别标签)。
>>> from sklearn.neural_network import MLPClassifier
>>> X = [[0., 0.], [1., 1.]]
>>> y = [0, 1]
>>> clf = MLPClassifier(solver='lbfgs', alpha=1e-5,
... hidden_layer_sizes=(5, 2), random_state=1)
...
>>> clf.fit(X, y)
MLPClassifier(alpha=1e-05, hidden_layer_sizes=(5, 2), random_state=1,
solver='lbfgs')
拟合(训练)后,模型可以预测新样本的标签。
>>> clf.predict([[2., 2.], [-1., -2.]])
array([1, 0])
MLP 可以将非线性模型拟合到训练数据。clf.coefs_包含构成模型参数的权重矩阵。
>>> [coef.shape for coef in clf.coefs_]
[(2, 5), (5, 2), (2, 1)]
目前,MLPClassifier只支持交叉熵损失函数,通过运行predict_proba方法可以得到概率估计。
MLP 使用反向传播进行训练。更准确地说,它使用某种形式的梯度下降,并且使用反向传播计算梯度。对于分类,它最小化交叉熵损失函数,为每个样本\(x\)提供一个概率估计向量\(P(y|x)\)
>>> clf.predict_proba([[2., 2.], [1., 2.]])
array([[1.967...e-04, 9.998...-01],
[1.967...e-04, 9.998...-01]])
MLPClassifier通过应用Softmax作为输出函数来支持多类别分类。
此外,该模型支持多标签分类,其中一个样本可以属于多个类别。对于每个类别,原始输出都通过逻辑函数。大于或等于0.5的值将四舍五入到1,否则四舍五入到0。对于样本的预测输出,值为1的索引表示该样本的指定类别。
>>> X = [[0., 0.], [1., 1.]]
>>> y = [[0, 1], [1, 1]]
>>> clf = MLPClassifier(solver='lbfgs', alpha=1e-5,
... hidden_layer_sizes=(15,), random_state=1)
...
>>> clf.fit(X, y)
MLPClassifier(alpha=1e-05, hidden_layer_sizes=(15,), random_state=1,
solver='lbfgs')
>>> clf.predict([[1., 2.]])
array([[1, 1]])
>>> clf.predict([[0., 0.]])
array([[0, 1]])
有关更多信息,请参见下面的示例和MLPClassifier.fit的文档字符串。
示例
参见MNIST上MLP权重的可视化以了解训练权重的可视化表示。
1.17.3. 回归#
类MLPRegressor实现了一个多层感知器 (MLP),它使用反向传播进行训练,输出层没有激活函数,也可以看作使用恒等函数作为激活函数。因此,它使用平方误差作为损失函数,输出是一组连续值。
MLPRegressor也支持多输出回归,其中一个样本可以有多个目标。
1.17.4. 正则化#
MLPRegressor和MLPClassifier都使用参数alpha进行正则化(L2 正则化),通过惩罚具有较大幅度的权重来帮助避免过拟合。下图显示了不同alpha值的决策函数。
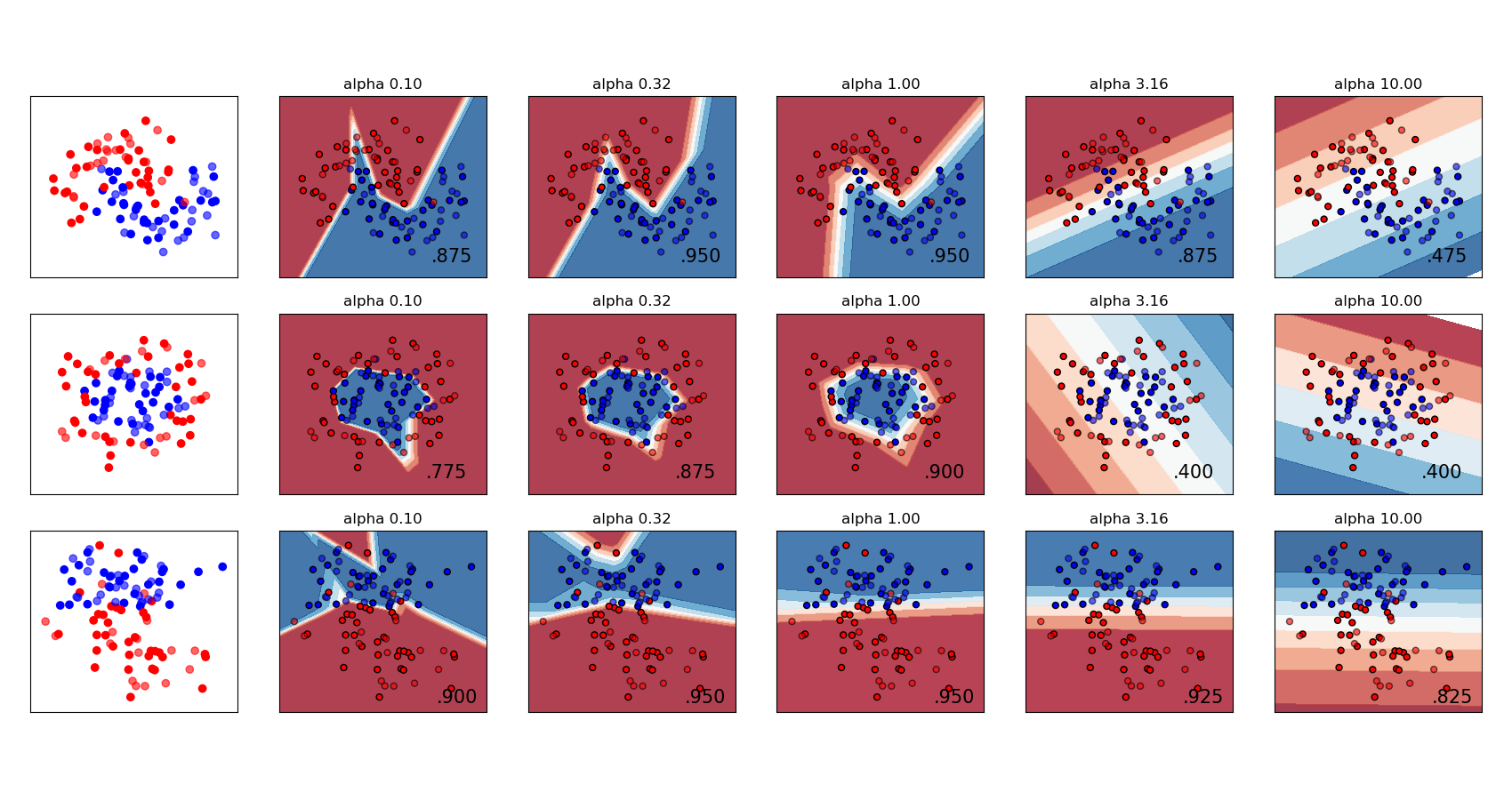
有关更多信息,请参见下面的示例。
示例
1.17.5. 算法#
MLP 使用随机梯度下降、Adam或L-BFGS进行训练。随机梯度下降 (SGD) 使用损失函数关于需要自适应的参数的梯度来更新参数,即
其中\(\eta\)是学习率,它控制参数空间搜索中的步长。\(Loss\)是网络使用的损失函数。
更多细节可以在SGD的文档中找到。
Adam 与 SGD 类似,因为它是一种随机优化器,但它可以根据低阶矩的自适应估计自动调整更新参数的量。
使用 SGD 或 Adam,训练支持在线和小型批次学习。
L-BFGS 是一种逼近 Hessian 矩阵的求解器,Hessian 矩阵表示函数的二阶偏导数。此外,它还逼近 Hessian 矩阵的逆来执行参数更新。该实现使用了L-BFGS的 Scipy 版本。
如果选择的求解器为“L-BFGS”,则训练不支持在线或小型批次学习。
1.17.6. 复杂度#
假设有\(n\)个训练样本,\(m\)个特征,\(k\)个隐藏层,每个隐藏层包含\(h\)个神经元——为简单起见,以及\(o\)个输出神经元。反向传播的时间复杂度为\(O(i \cdot n \cdot (m \cdot h + (k - 1) \cdot h \cdot h + h \cdot o))\),其中\(i\)是迭代次数。由于反向传播的时间复杂度很高,建议从较少的隐藏神经元和较少的隐藏层开始训练。
数学公式#
给定一组训练样本\((x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)\),其中\(x_i \in \mathbf{R}^n\)且\(y_i \in \{0, 1\}\),一个具有单隐层单隐层神经元的MLP学习函数\(f(x) = W_2 g(W_1^T x + b_1) + b_2\),其中\(W_1 \in \mathbf{R}^m\)和\(W_2, b_1, b_2 \in \mathbf{R}\)是模型参数。\(W_1, W_2\)分别表示输入层和隐层的权重;\(b_1, b_2\)分别表示添加到隐层和输出层的偏置。\(g(\cdot) : R \rightarrow R\)是激活函数,默认设置为双曲正切函数。其表达式为:
对于二元分类,\(f(x)\)经过逻辑函数\(g(z)=1/(1+e^{-z})\)得到0到1之间的输出值。阈值设置为0.5,输出值大于等于0.5的样本被分配到正类,其余的分配到负类。
如果有多于两个类别,\(f(x)\)本身将是一个大小为(n_classes,)的向量。它不经过逻辑函数,而是经过softmax函数,其表达式为:
其中\(z_i\)表示softmax输入的第\(i\)个元素,对应于第\(i\)类,\(K\)是类别数。结果是一个向量,包含样本\(x\)属于每个类别的概率。输出是概率最高的类别。
在回归问题中,输出保持为\(f(x)\);因此,输出激活函数只是恒等函数。
MLP根据问题类型使用不同的损失函数。分类问题的损失函数是平均交叉熵,在二元情况下,其表达式为:
其中\(\alpha ||W||_2^2\)是L2正则化项(也称为惩罚项),用于惩罚复杂的模型;\(\alpha > 0\)是一个非负超参数,控制惩罚项的大小。
对于回归问题,MLP使用均方误差损失函数,其表达式为:
从初始随机权重开始,多层感知器(MLP)通过反复更新这些权重来最小化损失函数。计算损失后,反向传播将损失从输出层传播到之前的层,为每个权重参数提供一个更新值,以减少损失。
在梯度下降中,计算损失函数关于权重的梯度\(\nabla Loss_{W}\),并从\(W\)中减去。更正式地,这可以表示为:
其中\(i\)是迭代步数,\(\epsilon\)是学习率,其值大于0。
当达到预设的最大迭代次数;或当损失的改进低于某个小的数值时,算法停止。
1.17.7. 实践技巧#
多层感知器对特征缩放敏感,因此强烈建议缩放您的数据。例如,将输入向量X上的每个属性缩放至[0, 1]或[-1, +1],或将其标准化为均值为0,方差为1。请注意,必须对测试集应用相同的缩放才能获得有意义的结果。您可以使用
StandardScaler进行标准化。>>> from sklearn.preprocessing import StandardScaler >>> scaler = StandardScaler() >>> # Don't cheat - fit only on training data >>> scaler.fit(X_train) >>> X_train = scaler.transform(X_train) >>> # apply same transformation to test data >>> X_test = scaler.transform(X_test)
另一种推荐的方法是在
Pipeline中使用StandardScaler找到合理的正则化参数\(\alpha\) 最好使用
GridSearchCV,通常在10.0 ** -np.arange(1, 7)范围内。根据经验,我们观察到
L-BFGS在小型数据集上收敛速度更快,并且解决方案更好。然而,对于相对较大的数据集,Adam非常鲁棒。它通常收敛速度很快,并且性能相当好。SGD加上动量或Nesterov动量,如果学习率正确调整,则可以优于这两种算法。
1.17.8. 使用warm_start获得更多控制#
如果您希望更好地控制SGD中的停止条件或学习率,或者希望进行额外的监控,则可以使用warm_start=True和max_iter=1并自行迭代。
>>> X = [[0., 0.], [1., 1.]]
>>> y = [0, 1]
>>> clf = MLPClassifier(hidden_layer_sizes=(15,), random_state=1, max_iter=1, warm_start=True)
>>> for i in range(10):
... clf.fit(X, y)
... # additional monitoring / inspection
MLPClassifier(...
参考文献#
“通过反向传播误差学习表示。” Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams.
“随机梯度下降” L. Bottou - 网站,2010。
“反向传播” Andrew Ng, Jiquan Ngiam, Chuan Yu Foo, Yifan Mai, Caroline Suen - 网站,2011。
“高效反向传播” Y. LeCun, L. Bottou, G. Orr, K. Müller - 在《神经网络:技巧》1998。
“Adam:一种用于随机优化的算法。” Kingma, Diederik, and Jimmy Ba (2014)