1.5. 随机梯度下降#
随机梯度下降 (SGD) 是一种简单而高效的训练线性分类器和回归器的方法,适用于支持向量机 (linear) 和逻辑回归等凸损失函数。尽管 SGD 在机器学习领域由来已久,但最近在大规模学习的背景下受到了相当多的关注。
SGD 已成功应用于文本分类和自然语言处理中常见的大规模和稀疏机器学习问题。鉴于数据的稀疏性,此模块中的分类器可以轻松扩展到具有超过 \(10^5\) 个训练样本和超过 \(10^5\) 个特征的问题。
严格来说,SGD 仅仅是一种优化技术,不对应于特定的机器学习模型家族。它只是一种训练模型的方法。通常,SGDClassifier 或 SGDRegressor 的实例在 scikit-learn API 中会有一个等效的估计器,可能使用不同的优化技术。例如,使用 SGDClassifier(loss='log_loss') 会得到逻辑回归,即一个与 LogisticRegression 等效的模型,它通过 SGD 拟合,而不是通过 LogisticRegression 中的其他求解器拟合。类似地,SGDRegressor(loss='squared_error', penalty='l2') 和 Ridge 通过不同的方式解决相同的优化问题。
随机梯度下降的优点是
效率高。
易于实现(有大量代码调优的机会)。
随机梯度下降的缺点包括
SGD 需要许多超参数,例如正则化参数和迭代次数。
SGD 对特征缩放敏感。
警告
在拟合模型之前,请确保对训练数据进行排列(打乱),或使用 shuffle=True 在每次迭代后打乱(默认为此)。此外,理想情况下,应使用例如 make_pipeline(StandardScaler(), SGDClassifier()) 对特征进行标准化(参见管道)。
1.5.1. 分类#
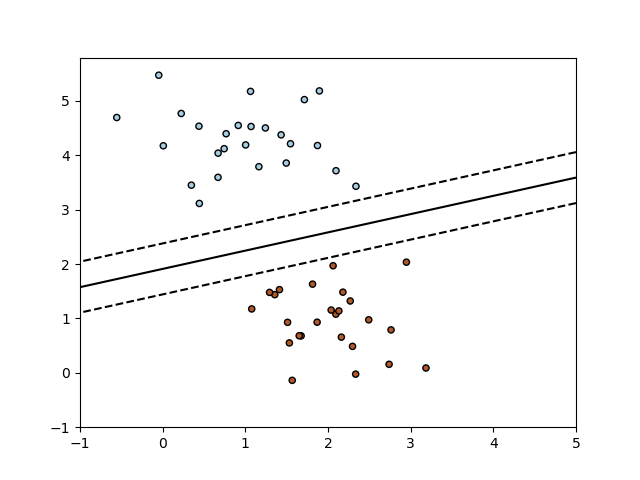
类 SGDClassifier 实现了简单的随机梯度下降学习例程,支持不同的损失函数和分类惩罚。下图是使用合页损失训练的 SGDClassifier 的决策边界,等同于线性 SVM。
与其他分类器一样,SGD 必须使用两个数组进行拟合:一个形状为 (n_samples, n_features) 的数组 X,用于保存训练样本;一个形状为 (n_samples,) 的数组 y,用于保存训练样本的目标值(类别标签)。
>>> from sklearn.linear_model import SGDClassifier
>>> X = [[0., 0.], [1., 1.]]
>>> y = [0, 1]
>>> clf = SGDClassifier(loss="hinge", penalty="l2", max_iter=5)
>>> clf.fit(X, y)
SGDClassifier(max_iter=5)
拟合后,模型可用于预测新值
>>> clf.predict([[2., 2.]])
array([1])
SGD 将线性模型拟合到训练数据。coef_ 属性保存模型参数
>>> clf.coef_
array([[9.9, 9.9]])
intercept_ 属性保存截距(又称偏移或偏差)
>>> clf.intercept_
array([-9.9])
模型是否应使用截距,即偏置超平面,由参数 fit_intercept 控制。
到超平面的有符号距离(通过系数与输入样本的点积加上截距计算)由 SGDClassifier.decision_function 给出
>>> clf.decision_function([[2., 2.]])
array([29.6])
具体的损失函数可以通过 loss 参数设置。SGDClassifier 支持以下损失函数
loss="hinge":(软间隔) 线性支持向量机,loss="modified_huber":平滑合页损失,loss="log_loss":逻辑回归,以及以下所有回归损失。在这种情况下,目标被编码为 \(-1\) 或 \(1\),问题被视为回归问题。然后预测的类别对应于预测目标的符号。
有关公式,请参阅下面的数学部分。前两个损失函数是惰性函数,它们仅在示例违反间隔约束时更新模型参数,这使得训练非常高效,并且可能导致更稀疏的模型(即具有更多零系数),即使使用 \(L_2\) 惩罚。
使用 loss="log_loss" 或 loss="modified_huber" 会启用 predict_proba 方法,该方法为每个样本 \(x\) 提供概率估计向量 \(P(y|x)\)。
>>> clf = SGDClassifier(loss="log_loss", max_iter=5).fit(X, y)
>>> clf.predict_proba([[1., 1.]])
array([[0.00, 0.99]])
具体的惩罚可以通过 penalty 参数设置。SGD 支持以下惩罚
penalty="l2":对coef_的 \(L_2\) 范数惩罚。penalty="l1":对coef_的 \(L_1\) 范数惩罚。penalty="elasticnet":\(L_2\) 和 \(L_1\) 的凸组合;(1 - l1_ratio) * L2 + l1_ratio * L1。
默认设置为 penalty="l2"。\(L_1\) 惩罚导致稀疏解,使大多数系数趋于零。弹性网络(Elastic Net)[11] 解决了在存在高度相关属性时 \(L_1\) 惩罚的一些不足。参数 l1_ratio 控制 \(L_1\) 和 \(L_2\) 惩罚的凸组合。
SGDClassifier 通过“一对多”(OVA) 方案结合多个二元分类器来支持多类别分类。对于 \(K\) 个类别中的每个类别,学习一个二元分类器,用于区分该类别与所有其他 \(K-1\) 个类别。在测试时,我们计算每个分类器的置信度分数(即到超平面的有符号距离),并选择置信度最高的类别。下图说明了在 iris 数据集上的 OVA 方法。虚线表示三个 OVA 分类器;背景颜色显示由三个分类器诱导的决策面。
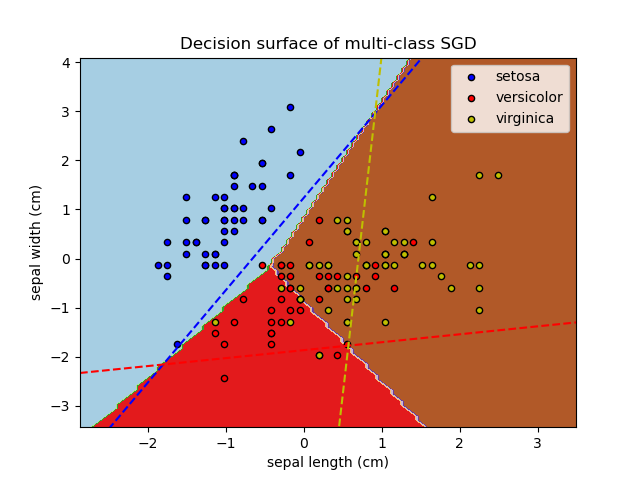
在多类别分类中,coef_ 是一个形状为 (n_classes, n_features) 的二维数组,而 intercept_ 是一个形状为 (n_classes,) 的一维数组。coef_ 的第 \(i\) 行包含第 \(i\) 个类别的 OVA 分类器的权重向量;类别按升序索引(参见属性 classes_)。请注意,原则上,由于它们允许创建概率模型,loss="log_loss" 和 loss="modified_huber" 更适合一对多分类。
SGDClassifier 通过拟合参数 class_weight 和 sample_weight 支持加权类别和加权实例。更多信息请参见以下示例和 SGDClassifier.fit 的文档字符串。
SGDClassifier 支持平均 SGD (ASGD) [10]。可以通过设置 average=True 启用平均。ASGD 执行与常规 SGD 相同的更新(参见数学公式),但不是使用系数的最后值作为 coef_ 属性(即最后一次更新的值),而是将 coef_ 设置为所有更新中系数的平均值。intercept_ 属性也进行同样的处理。使用 ASGD 时,学习率可以更大甚至保持不变,从而在某些数据集上加快训练时间。
对于使用逻辑损失的分类,另一种带有平均策略的 SGD 变体是随机平均梯度 (SAG) 算法,它可在 LogisticRegression 中作为求解器使用。
示例
1.5.2. 回归#
类 SGDRegressor 实现了简单的随机梯度下降学习例程,支持不同的损失函数和惩罚以拟合线性回归模型。SGDRegressor 非常适用于训练样本量大(> 10,000)的回归问题,对于其他问题,我们推荐使用 Ridge、Lasso 或 ElasticNet。
具体的损失函数可以通过 loss 参数设置。SGDRegressor 支持以下损失函数
loss="squared_error":普通最小二乘,loss="huber":Huber 损失,用于稳健回归,loss="epsilon_insensitive":线性支持向量回归。
有关公式,请参阅下面的数学部分。Huber 和 epsilon 不敏感损失函数可用于稳健回归。不敏感区域的宽度必须通过参数 epsilon 指定。此参数取决于目标变量的尺度。
penalty 参数决定了要使用的正则化(参见上面分类部分的描述)。
SGDRegressor 也支持平均 SGD [10](此处同样,参见上面分类部分的描述)。
对于使用平方损失和 \(L_2\) 惩罚的回归问题,另一种带有平均策略的 SGD 变体是随机平均梯度 (SAG) 算法,可在 Ridge 中作为求解器使用。
1.5.3. 在线单类别支持向量机#
类 sklearn.linear_model.SGDOneClassSVM 实现了使用随机梯度下降的在线线性版本的单类别支持向量机。结合核近似技术,sklearn.linear_model.SGDOneClassSVM 可以用于近似解决核化单类别支持向量机(在 sklearn.svm.OneClassSVM 中实现)的解,并且在样本数量上具有线性复杂度。请注意,核化单类别支持向量机的复杂度在样本数量上最好是二次的。sklearn.linear_model.SGDOneClassSVM 因此非常适合训练样本数量大(超过 10,000 个)的数据集,因为 SGD 变体可以快几个数量级。
数学细节#
它的实现基于随机梯度下降的实现。实际上,单类别支持向量机的原始优化问题由下式给出
其中 \(\nu \in (0, 1]\) 是用户指定的参数,控制离群值的比例和支持向量的比例。去除松弛变量 \(\xi_i\),该问题等价于
乘以常数 \(\nu\) 并引入截距 \(b = 1 - \rho\),我们得到以下等效优化问题
这与数学公式一节中研究的优化问题类似,其中 \(y_i = 1, 1 \leq i \leq n\) 且 \(\alpha = \nu/2\),\(L\) 是合页损失函数,\(R\) 是 \(L_2\) 范数。我们只需要在优化循环中添加项 \(b\nu\)。
与 SGDClassifier 和 SGDRegressor 类似,SGDOneClassSVM 支持平均 SGD。可以通过设置 average=True 启用平均。
示例
1.5.4. 稀疏数据的随机梯度下降#
注意
由于截距的学习率缩小,稀疏实现与密集实现会产生略微不同的结果。参见实现细节。
内置支持以 scipy.sparse 支持的任何矩阵格式提供的稀疏数据。然而,为了最大效率,请使用 scipy.sparse.csr_matrix 中定义的 CSR 矩阵格式。
示例
1.5.5. 复杂度#
SGD 的主要优点是其效率,其基本上与训练样本的数量呈线性关系。如果 \(X\) 是一个大小为 \(n \times p\) 的矩阵(包含 \(n\) 个样本和 \(p\) 个特征),则训练成本为 \(O(k n \bar p)\),其中 \(k\) 是迭代次数(周期),\(\bar p\) 是每个样本中非零属性的平均数量。
然而,最近的理论结果表明,达到所需优化精度的运行时不会随着训练集大小的增加而增加。
1.5.6. 停止准则#
类 SGDClassifier 和 SGDRegressor 提供两个准则,当达到给定收敛水平时停止算法
当
early_stopping=True时,输入数据被分成训练集和验证集。模型在训练集上拟合,停止准则基于在验证集上计算的预测分数(使用score方法)。验证集的大小可以通过参数validation_fraction进行更改。当
early_stopping=False时,模型在整个输入数据上拟合,停止准则基于在训练数据上计算的目标函数。
在这两种情况下,准则每个周期评估一次,当准则连续 n_iter_no_change 次没有改进时,算法停止。改进用绝对容差 tol 评估,并且算法在最大迭代次数 max_iter 后停止。
关于提前停止的效果示例,请参见随机梯度下降的提前停止。
1.5.7. 实用建议#
随机梯度下降对特征缩放敏感,因此强烈建议对数据进行缩放。例如,将输入向量 \(X\) 中的每个属性缩放到 \([0,1]\) 或 \([-1,1]\),或将其标准化为均值 \(0\) 和方差 \(1\)。请注意,必须对测试向量应用相同的缩放才能获得有意义的结果。这可以通过使用
StandardScaler轻松完成from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(X_train) # Don't cheat - fit only on training data X_train = scaler.transform(X_train) X_test = scaler.transform(X_test) # apply same transformation to test data # Or better yet: use a pipeline! from sklearn.pipeline import make_pipeline est = make_pipeline(StandardScaler(), SGDClassifier()) est.fit(X_train) est.predict(X_test)
如果您的属性具有内在尺度(例如词频或指示特征),则无需缩放。
寻找合理的正则化项 \(\alpha\) 最好通过自动超参数搜索来完成,例如
GridSearchCV或RandomizedSearchCV,通常在10.0**-np.arange(1,7)范围内。根据经验,我们发现 SGD 在观察大约 \(10^6\) 个训练样本后收敛。因此,迭代次数的合理首次猜测是
max_iter = np.ceil(10**6 / n),其中n是训练集的大小。如果您将 SGD 应用于使用 PCA 提取的特征,我们发现通常明智的做法是将特征值乘以某个常数
c,使得训练数据的平均 \(L_2\) 范数等于一。我们发现平均 SGD 在特征数量较多和
eta0较高时效果最佳。
参考文献
“高效反向传播” Y. LeCun, L. Bottou, G. Orr, K. Müller - 刊于 Neural Networks: Tricks of the Trade 1998。
1.5.8. 数学公式#
我们在此描述 SGD 过程的数学细节。关于收敛率的良好概述可以在[12]中找到。
给定一组训练样本 \((x_1, y_1), \ldots, (x_n, y_n)\),其中 \(x_i \in \mathbf{R}^m\) 和 \(y_i \in \mathbf{R}\)(分类问题中 \(y_i \in \{-1, 1\}\)),我们的目标是学习一个线性评分函数 \(f(x) = w^T x + b\),其模型参数为 \(w \in \mathbf{R}^m\) 和截距 \(b \in \mathbf{R}\)。为了进行二元分类预测,我们只需查看 \(f(x)\) 的符号。为了找到模型参数,我们最小化由下式给出的正则化训练误差
其中 \(L\) 是衡量模型(不)拟合程度的损失函数,\(R\) 是惩罚模型复杂度的正则化项(又称惩罚项);\(\alpha > 0\) 是控制正则化强度的非负超参数。
损失函数详情#
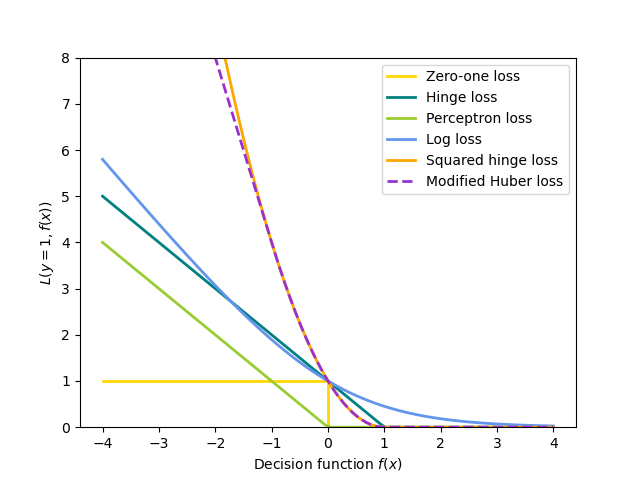
对 \(L\) 的不同选择会产生不同的分类器或回归器
合页损失(软间隔):等同于支持向量分类。\(L(y_i, f(x_i)) = \max(0, 1 - y_i f(x_i))\)。
感知器:\(L(y_i, f(x_i)) = \max(0, - y_i f(x_i))\)。
修改后的Huber:如果 \(y_i f(x_i) > -1\),则 \(L(y_i, f(x_i)) = \max(0, 1 - y_i f(x_i))^2\);否则 \(L(y_i, f(x_i)) = -4 y_i f(x_i)\)。
对数损失:等同于逻辑回归。\(L(y_i, f(x_i)) = \log(1 + \exp (-y_i f(x_i)))\)。
平方误差:线性回归(根据 \(R\) 选择 Ridge 或 Lasso)。\(L(y_i, f(x_i)) = \frac{1}{2}(y_i - f(x_i))^2\)。
Huber:对离群值比最小二乘更不敏感。当 \(|y_i - f(x_i)| \leq \varepsilon\) 时,它等同于最小二乘;否则,\(L(y_i, f(x_i)) = \varepsilon |y_i - f(x_i)| - \frac{1}{2} \varepsilon^2\)。
Epsilon-Insensitive:(软间隔)等同于支持向量回归。\(L(y_i, f(x_i)) = \max(0, |y_i - f(x_i)| - \varepsilon)\)。
如以下图所示,上述所有损失函数都可以视为误分类误差(零一损失)的上限。
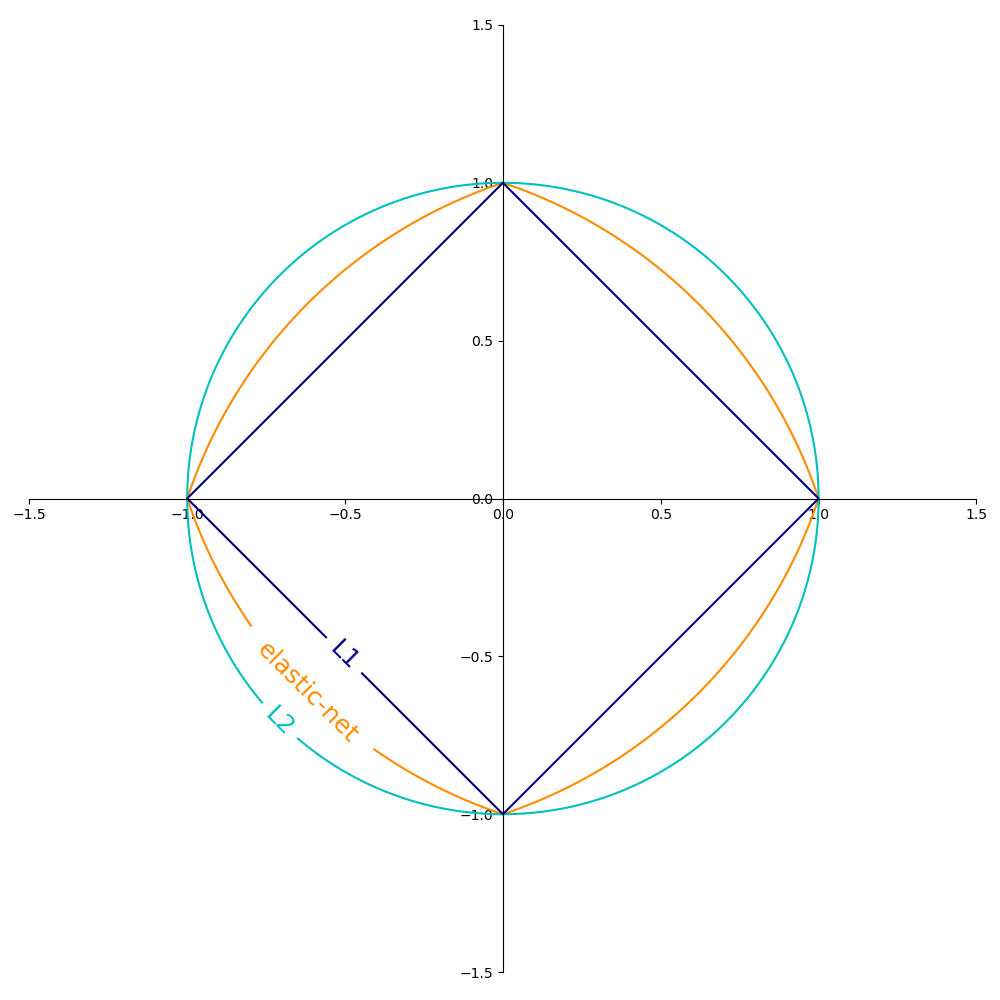
正则化项 \(R\)(penalty 参数)的常见选择包括
\(L_2\) 范数:\(R(w) := \frac{1}{2} \sum_{j=1}^{m} w_j^2 = ||w||_2^2\),
\(L_1\) 范数:\(R(w) := \sum_{j=1}^{m} |w_j|\),这导致稀疏解。
弹性网络(Elastic Net):\(R(w) := \frac{\rho}{2} \sum_{j=1}^{n} w_j^2 + (1-\rho) \sum_{j=1}^{m} |w_j|\),是 \(L_2\) 和 \(L_1\) 的凸组合,其中 \(\rho\) 由
1 - l1_ratio给出。
下图显示了当 \(R(w) = 1\) 时,2 维参数空间(\(m=2\))中不同正则化项的等高线。
1.5.8.1. SGD#
随机梯度下降是一种用于无约束优化问题的优化方法。与(批量)梯度下降相反,SGD 通过一次考虑一个训练样本来近似 \(E(w,b)\) 的真实梯度。
类 SGDClassifier 实现了首阶 SGD 学习例程。该算法遍历训练样本,并为每个样本根据以下更新规则更新模型参数
其中 \(\eta\) 是学习率,控制参数空间中的步长。截距 \(b\) 以类似方式更新,但没有正则化(对于稀疏矩阵,还有额外的衰减,详情见实现细节)。
学习率 \(\eta\) 可以是常数,也可以是逐渐衰减的。对于分类,默认的学习率调度(learning_rate='optimal')由下式给出
其中 \(t\) 是时间步(总共有 n_samples * n_iter 个时间步),\(t_0\) 是根据 Léon Bottou 提出的启发式方法确定的,使得预期初始更新与预期的权重大小相当(这假设训练样本的范数约为 1)。确切的定义可以在 BaseSGD 中的 _init_t 中找到。
对于回归,默认的学习率调度是逆比例缩放(learning_rate='invscaling'),由下式给出
其中 \(eta_0\) 和 \(power\_t\) 分别是用户通过 eta0 和 power_t 选择的超参数。
对于恒定学习率,请使用 learning_rate='constant',并使用 eta0 指定学习率。
对于自适应递减的学习率,请使用 learning_rate='adaptive',并使用 eta0 指定起始学习率。当达到停止准则时,学习率除以 5,算法不会停止。当学习率低于 1e-6 时,算法停止。
模型参数可以通过 coef_ 和 intercept_ 属性访问:coef_ 保存权重 \(w\),intercept_ 保存 \(b\)。
使用平均 SGD(带有 average 参数)时,coef_ 被设置为所有更新的平均权重:coef_ \( = \frac{1}{T} \sum_{t=0}^{T-1} w^{(t)}\),其中 \(T\) 是更新的总次数,可在 t_ 属性中找到。
1.5.9. 实现细节#
SGD 的实现受到了 [7] 中 随机支持向量机 的影响。与 SvmSGD 类似,权重向量被表示为标量和向量的乘积,这使得在 \(L_2\) 正则化情况下能够高效地更新权重。在稀疏输入 X 的情况下,截距以较小的学习率(乘以 0.01)更新,以考虑它更新更频繁的事实。训练样本按顺序选取,并且学习率在每个观察到的样本后降低。我们采用了 [8] 中的学习率调度。对于多类别分类,使用“一对多”方法。我们使用 [9] 中提出的截断梯度算法进行 \(L_1\) 正则化(和弹性网络)。代码用 Cython 编写。
参考文献