1.11. 集成方法:梯度提升、随机森林、bagging、投票、堆叠#
集成方法结合了使用给定学习算法构建的多个基础估计器的预测结果,以提高相对于单个估计器的泛化能力/鲁棒性。
更一般地,集成模型可以应用于树以外的任何基础学习器,包括Bagging 方法、模型堆叠或投票等平均方法,以及AdaBoost等提升方法。
1.11.1. 梯度提升树#
梯度树提升或梯度提升决策树(GBDT)是提升算法对任意可微分损失函数的推广,请参阅[Friedman2001]的开创性工作。GBDT 是一种出色的回归和分类模型,特别适用于表格数据。
1.11.1.1. 基于直方图的梯度提升#
Scikit-learn 0.21 引入了两种新的梯度提升树实现,即 HistGradientBoostingClassifier 和 HistGradientBoostingRegressor,灵感来源于 LightGBM(参见 [LightGBM])。
当样本数量大于数万个时,这些基于直方图的估计器可以比 GradientBoostingClassifier 和 GradientBoostingRegressor 快上几个数量级。
它们还内置支持缺失值,无需使用插值器。
这些快速估计器首先将输入样本 X 分到整数值分箱中(通常为 256 个分箱),这极大地减少了需要考虑的分裂点数量,并允许算法在构建树时利用基于整数的数据结构(直方图),而不是依赖于排序后的连续值。这些估计器的 API 略有不同,GradientBoostingClassifier 和 GradientBoostingRegressor 中的一些功能尚未得到支持,例如某些损失函数。
示例
1.11.1.1.1. 用法#
大多数参数与 GradientBoostingClassifier 和 GradientBoostingRegressor 保持不变。一个例外是 max_iter 参数取代了 n_estimators,用于控制提升过程的迭代次数。
>>> from sklearn.ensemble import HistGradientBoostingClassifier
>>> from sklearn.datasets import make_hastie_10_2
>>> X, y = make_hastie_10_2(random_state=0)
>>> X_train, X_test = X[:2000], X[2000:]
>>> y_train, y_test = y[:2000], y[2000:]
>>> clf = HistGradientBoostingClassifier(max_iter=100).fit(X_train, y_train)
>>> clf.score(X_test, y_test)
0.8965
回归可用的损失函数有:
‘squared_error’(平方误差),默认损失函数;
‘absolute_error’(绝对误差),对离群值不敏感度低于平方误差;
‘gamma’,非常适合建模严格为正的结果;
‘poisson’(泊松),非常适合建模计数和频率;
‘quantile’(分位数),允许估计条件分位数,可用于获取预测区间。
对于分类,‘log_loss’ 是唯一的选择。对于二元分类,它使用二元对数损失,也称为二项式偏差或二元交叉熵。对于 n_classes >= 3,它使用多类对数损失函数,也称为多项式偏差和分类交叉熵。适当的损失版本是根据传递给 fit 的 y 来选择的。
树的大小可以通过 max_leaf_nodes、max_depth 和 min_samples_leaf 参数来控制。
用于对数据进行分箱的箱数由 max_bins 参数控制。使用较少的箱数可以作为一种正则化形式。通常建议使用尽可能多的箱数(255),这是默认值。
l2_regularization 参数充当损失函数的正则化项,对应于以下表达式中的 \(\lambda\)(参见 [XGBoost] 中的方程 (2))
l2 正则化详情#
重要的是要注意,除了 pinball 损失和绝对误差之外,损失项 \(l(\hat{y}_i, y_i)\) 只描述了实际损失函数的一半。
索引 \(k\) 指的是树集成中的第 k 棵树。在回归和二元分类的情况下,梯度提升模型在每次迭代中只生长一棵树,因此 \(k\) 的范围达到 max_iter。在多类分类问题的情况下,索引 \(k\) 的最大值是 n_classes \(\times\) max_iter。
如果 \(T_k\) 表示第 k 棵树中的叶子数量,那么 \(w_k\) 是长度为 \(T_k\) 的向量,其中包含叶子值,形式为 w = -sum_gradient / (sum_hessian + l2_regularization)(参见 [XGBoost] 中的方程 (5))。
叶子值 \(w_k\) 是通过将损失函数梯度的总和除以 Hessian 矩阵总和来导出的。将正则化项添加到分母中会惩罚具有小 Hessian 矩阵(平坦区域)的叶子,从而导致较小的更新。然后,这些 \(w_k\) 值会为落入相应叶子的给定输入贡献模型的预测。最终预测是基础预测和每棵树贡献的总和。然后根据损失函数的选择,通过逆链接函数对总和结果进行转换(参见数学公式)。
请注意,原始论文 [XGBoost] 引入了一个项 \(\gamma\sum_k T_k\),它惩罚叶子数量(使其成为 max_leaf_nodes 的平滑版本),但此处未介绍,因为它未在 scikit-learn 中实现;而 \(\lambda\) 惩罚单个树预测在被学习率重新缩放之前的大小,参见通过学习率进行收缩。
请注意,如果样本数量大于 10,000,默认启用提前停止。提前停止行为通过 early_stopping、scoring、validation_fraction、n_iter_no_change 和 tol 参数控制。可以使用任意 scorer 进行提前停止,或者只使用训练或验证损失。请注意,出于技术原因,使用可调用对象作为评分器比使用损失要慢得多。默认情况下,如果训练集中至少有 10,000 个样本,则使用验证损失执行提前停止。
1.11.1.1.2. 缺失值支持#
HistGradientBoostingClassifier 和 HistGradientBoostingRegressor 内置支持缺失值(NaNs)。
在训练期间,树生长器在每个分裂点根据潜在增益学习缺失值样本应该进入左子节点还是右子节点。在预测时,缺失值样本会相应地分配给左子节点或右子节点。
>>> from sklearn.ensemble import HistGradientBoostingClassifier
>>> import numpy as np
>>> X = np.array([0, 1, 2, np.nan]).reshape(-1, 1)
>>> y = [0, 0, 1, 1]
>>> gbdt = HistGradientBoostingClassifier(min_samples_leaf=1).fit(X, y)
>>> gbdt.predict(X)
array([0, 0, 1, 1])
当缺失模式具有预测性时,可以根据特征值是否缺失来执行分裂。
>>> X = np.array([0, np.nan, 1, 2, np.nan]).reshape(-1, 1)
>>> y = [0, 1, 0, 0, 1]
>>> gbdt = HistGradientBoostingClassifier(min_samples_leaf=1,
... max_depth=2,
... learning_rate=1,
... max_iter=1).fit(X, y)
>>> gbdt.predict(X)
array([0, 1, 0, 0, 1])
如果在训练期间某个给定特征没有遇到缺失值,那么在预测时,缺失值样本将映射到具有最多样本的子节点。
示例
1.11.1.1.3. 样本权重支持#
HistGradientBoostingClassifier 和 HistGradientBoostingRegressor 在 fit 期间支持样本权重。
以下玩具示例演示了样本权重为零的样本被忽略:
>>> X = [[1, 0],
... [1, 0],
... [1, 0],
... [0, 1]]
>>> y = [0, 0, 1, 0]
>>> # ignore the first 2 training samples by setting their weight to 0
>>> sample_weight = [0, 0, 1, 1]
>>> gb = HistGradientBoostingClassifier(min_samples_leaf=1)
>>> gb.fit(X, y, sample_weight=sample_weight)
HistGradientBoostingClassifier(...)
>>> gb.predict([[1, 0]])
array([1])
>>> gb.predict_proba([[1, 0]])[0, 1]
np.float64(0.999)
如您所见,[1, 0] 被轻松分类为 1,因为前两个样本由于其样本权重而被忽略。
实现细节:考虑样本权重相当于将梯度(和 Hessian 矩阵)乘以样本权重。请注意,分箱阶段(特别是分位数计算)不考虑权重。
1.11.1.1.4. 分类特征支持#
HistGradientBoostingClassifier 和 HistGradientBoostingRegressor 原生支持分类特征:它们可以考虑对非有序分类数据进行分裂。
对于包含分类特征的数据集,使用原生分类支持通常优于依赖独热编码(OneHotEncoder),因为独热编码需要更深的树深度才能实现等效的分裂。依赖原生分类支持也通常优于将分类特征视为连续(有序)特征,这在有序编码的分类数据中会发生,因为类别是名义量,顺序并不重要。
要启用分类支持,可以将布尔掩码传递给 categorical_features 参数,指示哪个特征是分类的。在下面,第一个特征将被视为分类特征,第二个特征被视为数值特征:
>>> gbdt = HistGradientBoostingClassifier(categorical_features=[True, False])
同样地,可以传递一个整数列表,指示分类特征的索引:
>>> gbdt = HistGradientBoostingClassifier(categorical_features=[0])
当输入是 DataFrame 时,也可以传递一个列名列表:
>>> gbdt = HistGradientBoostingClassifier(categorical_features=["site", "manufacturer"])
最后,当输入是 DataFrame 时,我们可以使用 categorical_features="from_dtype",在这种情况下,所有具有分类 dtype 的列都将被视为分类特征。
每个分类特征的基数必须小于 max_bins 参数。有关在分类特征上使用基于直方图的梯度提升的示例,请参阅梯度提升中的分类特征支持。
如果在训练期间存在缺失值,缺失值将被视为一个适当的类别。如果在训练期间没有缺失值,那么在预测时,缺失值将被映射到具有最多样本的子节点(就像连续特征一样)。在预测时,训练期间未见的类别将被视为缺失值。
使用分类特征查找分裂点#
在树中考虑分类分裂的规范方法是考虑所有 \(2^{K - 1} - 1\) 个分区,其中 \(K\) 是类别的数量。当 \(K\) 很大时,这很快就会变得令人望而却步。幸运的是,由于梯度提升树始终是回归树(即使对于分类问题),存在一种更快的策略可以产生等效的分裂。首先,对于每个类别 k,根据目标变量的方差对特征的类别进行排序。一旦类别排序完成,就可以考虑连续分区,即像对待有序连续值一样对待这些类别(参见 [Fisher1958] 的正式证明)。因此,只需要考虑 \(K - 1\) 个分裂点,而不是 \(2^{K - 1} - 1\) 个。初始排序操作的复杂度为 \(\mathcal{O}(K \log(K))\),总复杂度为 \(\mathcal{O}(K \log(K) + K)\),而不是 \(\mathcal{O}(2^K)\)。
示例
1.11.1.1.5. 单调约束#
根据手头的问题,您可能具有先验知识,表明给定特征通常应对目标值产生正向(或负向)影响。例如,在其他条件相同的情况下,更高的信用评分应增加获得贷款批准的概率。单调约束允许您将此类先验知识纳入模型中。
对于具有两个特征的预测器 \(F\):
单调递增约束的形式为:
\[x_1 \leq x_1' \implies F(x_1, x_2) \leq F(x_1', x_2)\]单调递减约束的形式为:
\[x_1 \leq x_1' \implies F(x_1, x_2) \geq F(x_1', x_2)\]
您可以使用 monotonic_cst 参数指定每个特征的单调约束。对于每个特征,值 0 表示无约束,而 1 和 -1 分别表示单调递增和单调递减约束。
>>> from sklearn.ensemble import HistGradientBoostingRegressor
... # monotonic increase, monotonic decrease, and no constraint on the 3 features
>>> gbdt = HistGradientBoostingRegressor(monotonic_cst=[1, -1, 0])
在二元分类上下文中,施加单调递增(递减)约束意味着特征的较高值应对样本属于正类的概率产生正向(负向)影响。
然而,单调约束只对特征对输出的影响进行了轻微约束。例如,单调递增和递减约束不能用于强制执行以下建模约束:
此外,多类分类不支持单调约束。
有关使用基于直方图的梯度提升实现单调约束的实际示例,包括当领域知识可用时如何提高泛化能力,请参阅单调约束。
注意
由于类别是无序量,因此无法对分类特征施加单调约束。
示例
1.11.1.1.6. 交互约束#
先验地,基于直方图的梯度提升树允许使用任何特征将节点分裂为子节点。这会产生所谓的特征交互,即沿分支使用不同的特征进行分裂。有时,人们希望限制可能的交互,参见 [Mayer2022]。这可以通过参数 interaction_cst 来完成,在该参数中可以指定允许交互的特征索引。例如,总共有 3 个特征,interaction_cst=[{0}, {1}, {2}] 禁止所有交互。约束 [{0, 1}, {1, 2}] 指定了两组可能交互的特征。特征 0 和 1 可以相互交互,特征 1 和 2 也可以。但请注意,特征 0 和 2 被禁止交互。下图描绘了一棵树和树的可能分裂:
1 <- Both constraint groups could be applied from now on
/ \
1 2 <- Left split still fulfills both constraint groups.
/ \ / \ Right split at feature 2 has only group {1, 2} from now on.
LightGBM 对重叠组使用相同的逻辑。
请注意,未在 interaction_cst 中列出的特征会自动分配给自己的交互组。同样有 3 个特征,这意味着 [{0}] 等同于 [{0}, {1, 2}]。
示例
References
M. Mayer, S.C. Bourassa, M. Hoesli, and D.F. Scognamiglio. 2022. Machine Learning Applications to Land and Structure Valuation. Journal of Risk and Financial Management 15, no. 5: 193
1.11.1.1.7. 低级并行性#
HistGradientBoostingClassifier 和 HistGradientBoostingRegressor 通过 Cython 使用 OpenMP 进行并行化。有关如何控制线程数的更多详细信息,请参阅我们的并行性说明。
以下部分是并行化的:
将样本从实数值映射到整数值分箱(但是查找分箱阈值是顺序的)
构建直方图在特征上并行化
在节点处找到最佳分裂点在特征上并行化
在 fit 期间,将样本映射到左子节点和右子节点在样本上并行化
梯度和 Hessian 矩阵计算在样本上并行化
预测在样本上并行化
1.11.1.1.8. 为什么它更快#
梯度提升过程的瓶颈是构建决策树。构建传统决策树(如其他 GBDT GradientBoostingClassifier 和 GradientBoostingRegressor 中所示)需要对每个节点(对每个特征)的样本进行排序。需要排序才能有效地计算分裂点的潜在增益。因此,分裂单个节点的复杂度为 \(\mathcal{O}(n_\text{features} \times n \log(n))\),其中 \(n\) 是节点处的样本数量。
相反,HistGradientBoostingClassifier 和 HistGradientBoostingRegressor 不需要对特征值进行排序,而是使用一种称为直方图的数据结构,其中样本是隐式排序的。构建直方图的复杂度为 \(\mathcal{O}(n)\),因此节点分裂过程的复杂度为 \(\mathcal{O}(n_\text{features} \times n)\),远小于前者。此外,我们只考虑 max_bins 个分裂点,而不是 \(n\) 个分裂点,这可能小得多。
为了构建直方图,输入数据 X 需要被分到整数值分箱中。这个分箱过程确实需要对特征值进行排序,但它只在提升过程开始时发生一次(不像 GradientBoostingClassifier 和 GradientBoostingRegressor 那样在每个节点处都发生)。
最后,HistGradientBoostingClassifier 和 HistGradientBoostingRegressor 的许多实现部分都进行了并行化。
References
Fisher, W.D. (1958). “On Grouping for Maximum Homogeneity” Journal of the American Statistical Association, 53, 789-798.
1.11.1.2. GradientBoostingClassifier 和 GradientBoostingRegressor#
GradientBoostingClassifier 和 GradientBoostingRegressor 的用法和参数如下所述。这些估计器中最重要的两个参数是 n_estimators 和 learning_rate。
分类#
GradientBoostingClassifier 支持二元分类和多类分类。以下示例展示了如何使用 100 个决策树桩作为弱学习器来拟合梯度提升分类器:
>>> from sklearn.datasets import make_hastie_10_2
>>> from sklearn.ensemble import GradientBoostingClassifier
>>> X, y = make_hastie_10_2(random_state=0)
>>> X_train, X_test = X[:2000], X[2000:]
>>> y_train, y_test = y[:2000], y[2000:]
>>> clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0,
... max_depth=1, random_state=0).fit(X_train, y_train)
>>> clf.score(X_test, y_test)
0.913
弱学习器(即回归树)的数量由参数 n_estimators 控制;每棵树的大小可以通过 max_depth 设置树深或通过 max_leaf_nodes 设置叶子节点数量来控制。learning_rate 是一个在 (0.0, 1.0] 范围内的超参数,通过收缩来控制过拟合。
注意
具有 2 个以上类别的分类需要在每次迭代中归纳 n_classes 棵回归树,因此,归纳的总树数等于 n_classes * n_estimators。对于具有大量类别的数据集,我们强烈建议使用 HistGradientBoostingClassifier 作为 GradientBoostingClassifier 的替代方案。
回归#
GradientBoostingRegressor 支持多种不同的损失函数用于回归,可以通过参数 loss 指定;回归的默认损失函数是平方误差('squared_error')。
>>> import numpy as np
>>> from sklearn.metrics import mean_squared_error
>>> from sklearn.datasets import make_friedman1
>>> from sklearn.ensemble import GradientBoostingRegressor
>>> X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
>>> X_train, X_test = X[:200], X[200:]
>>> y_train, y_test = y[:200], y[200:]
>>> est = GradientBoostingRegressor(
... n_estimators=100, learning_rate=0.1, max_depth=1, random_state=0,
... loss='squared_error'
... ).fit(X_train, y_train)
>>> mean_squared_error(y_test, est.predict(X_test))
5.00
下图显示了将 GradientBoostingRegressor 应用于糖尿病数据集(sklearn.datasets.load_diabetes),使用最小二乘损失和 500 个基础学习器的结果。该图显示了每次迭代的训练误差和测试误差。每次迭代的训练误差存储在梯度提升模型的 train_score_ 属性中。每次迭代的测试误差可以通过 staged_predict 方法获得,该方法返回一个生成器,生成每个阶段的预测结果。像这样的图可以用于通过提前停止来确定最佳树数(即 n_estimators)。
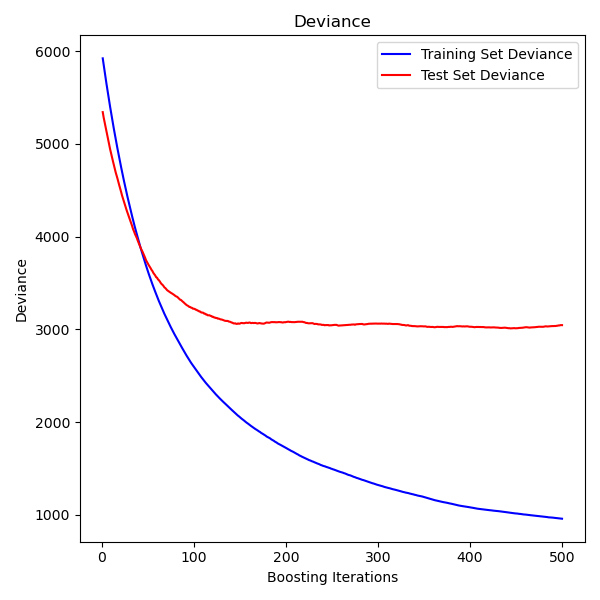
示例
1.11.1.2.1. 拟合额外的弱学习器#
GradientBoostingRegressor 和 GradientBoostingClassifier 都支持 warm_start=True,这允许您向已拟合的模型添加更多估计器。
>>> import numpy as np
>>> from sklearn.metrics import mean_squared_error
>>> from sklearn.datasets import make_friedman1
>>> from sklearn.ensemble import GradientBoostingRegressor
>>> X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
>>> X_train, X_test = X[:200], X[200:]
>>> y_train, y_test = y[:200], y[200:]
>>> est = GradientBoostingRegressor(
... n_estimators=100, learning_rate=0.1, max_depth=1, random_state=0,
... loss='squared_error'
... )
>>> est = est.fit(X_train, y_train) # fit with 100 trees
>>> mean_squared_error(y_test, est.predict(X_test))
5.00
>>> _ = est.set_params(n_estimators=200, warm_start=True) # set warm_start and increase num of trees
>>> _ = est.fit(X_train, y_train) # fit additional 100 trees to est
>>> mean_squared_error(y_test, est.predict(X_test))
3.84
1.11.1.2.2. 控制树的大小#
回归树基础学习器的大小定义了梯度提升模型可以捕获的变量交互级别。通常,深度为 h 的树可以捕获最高为 h 阶的交互。有两种方法可以控制单个回归树的大小。
如果您指定 max_depth=h,则将生长深度为 h 的完整二叉树。这样的树将具有(最多)2**h 个叶子节点和 2**h - 1 个分裂节点。
或者,您可以通过参数 max_leaf_nodes 指定叶子节点数量来控制树的大小。在这种情况下,将使用最佳优先搜索来生长树,其中杂质改善程度最高的节点将首先扩展。具有 max_leaf_nodes=k 的树有 k - 1 个分裂节点,因此可以建模最高为 max_leaf_nodes - 1 阶的交互。
我们发现 max_leaf_nodes=k 提供了与 max_depth=k-1 相当的结果,但在训练速度上明显更快,代价是训练误差略高。max_leaf_nodes 参数对应于 [Friedman2001] 中关于梯度提升章节中的变量 J,并与 R 的 gbm 包中的参数 interaction.depth 相关,其中 max_leaf_nodes == interaction.depth + 1。
1.11.1.2.3. 数学公式#
我们首先介绍回归的 GBRT,然后详细介绍分类情况。
回归#
GBRT 回归器是加性模型,对于给定输入 \(x_i\),其预测 \(\hat{y}_i\) 形式如下:
其中 \(h_m\) 是在提升上下文中称为弱学习器的估计器。梯度树提升使用固定大小的决策树回归器作为弱学习器。常数 M 对应于 n_estimators 参数。
与其他提升算法类似,GBRT 以贪婪方式构建:
其中新添加的树 \(h_m\) 被拟合以最小化损失 \(L_m\) 的总和,给定先前的集成 \(F_{m-1}\):
其中 \(l(y_i, F(x_i))\) 由 loss 参数定义,详见下一节。
默认情况下,初始模型 \(F_{0}\) 选择为使损失最小化的常数:对于最小二乘损失,这是目标值的经验平均值。初始模型也可以通过 init 参数指定。
使用一阶泰勒近似,\(l\) 的值可以近似如下:
注意
简单来说,一阶泰勒近似表示 \(l(z) \approx l(a) + (z - a) \frac{\partial l}{\partial z}(a)\)。这里,\(z\) 对应于 \(F_{m - 1}(x_i) + h_m(x_i)\),\(a\) 对应于 \(F_{m-1}(x_i)\)。
量 \(\left[ \frac{\partial l(y_i, F(x_i))}{\partial F(x_i)} \right]_{F=F_{m - 1}}\) 是损失函数相对于其第二个参数的导数,在 \(F_{m-1}(x)\) 处评估。对于任何给定的 \(F_{m - 1}(x_i)\),由于损失是可微分的,因此很容易以闭合形式计算。我们将其表示为 \(g_i\)。
去除常数项,我们有:
如果 \(h(x_i)\) 被拟合以预测与负梯度 \(-g_i\) 成比例的值,则此式最小化。因此,在每次迭代中,估计器 \(h_m\) 被拟合以预测样本的负梯度。梯度在每次迭代中更新。这可以被视为函数空间中的一种梯度下降。
注意
对于某些损失,例如 'absolute_error'(其中梯度为 \(\pm 1\)),拟合的 \(h_m\) 预测的值不够精确:树只能输出整数值。因此,一旦树拟合完毕,树 \(h_m\) 的叶子值将被修改,使得叶子值最小化损失 \(L_m\)。更新取决于损失:对于绝对误差损失,叶子值被更新为该叶子中样本的中位数。
分类#
用于分类的梯度提升与回归情况非常相似。然而,树的总和 \(F_M(x_i) = \sum_m h_m(x_i)\) 与预测不一致:它不能是一个类别,因为树预测连续值。
从值 \(F_M(x_i)\) 到类别或概率的映射取决于损失。对于对数损失,\(x_i\) 属于正类的概率被建模为 \(p(y_i = 1 | x_i) = \sigma(F_M(x_i))\),其中 \(\sigma\) 是 sigmoid 或 expit 函数。
对于多类分类,在 \(M\) 次迭代中的每次迭代都构建 K 棵树(对于 K 个类别)。\(x_i\) 属于类别 k 的概率被建模为 \(F_{M,k}(x_i)\) 值的 softmax。
请注意,即使对于分类任务,子估计器 \(h_m\) 仍然是回归器,而不是分类器。这是因为子估计器被训练来预测(负)梯度,这些梯度始终是连续量。
1.11.1.2.4. 损失函数#
支持以下损失函数,可以通过参数 loss 指定:
回归#
平方误差(
'squared_error'):由于其优越的计算特性,是回归的自然选择。初始模型由目标值的平均值给出。绝对误差(
'absolute_error'):一种鲁棒的回归损失函数。初始模型由目标值的中位数给出。Huber(
'huber'):另一种鲁棒的损失函数,结合了最小二乘和最小绝对偏差;使用alpha来控制对离群值的敏感度(有关更多详细信息,请参见 [Friedman2001])。分位数(
'quantile'):用于分位数回归的损失函数。使用0 < alpha < 1来指定分位数。此损失函数可用于创建预测区间(参见梯度提升回归的预测区间)。
分类#
二元对数损失(
'log-loss'):用于二元分类的二项式负对数似然损失函数。它提供概率估计。初始模型由对数几率给出。多类对数损失(
'log-loss'):用于多类分类的多项式负对数似然损失函数,具有n_classes个互斥类别。它提供概率估计。初始模型由每个类别的先验概率给出。在每次迭代中必须构建n_classes棵回归树,这使得 GBRT 对于具有大量类别的数据集效率较低。指数损失(
'exponential'):与AdaBoostClassifier相同的损失函数。对错误标记的示例不如'log-loss'鲁棒;只能用于二元分类。
1.11.1.2.5. 通过学习率收缩#
[Friedman2001] 提出了一种简单的正则化策略,通过常数因子 \(\nu\) 来缩放每个弱学习器的贡献:
参数 \(\nu\) 也称为学习率,因为它缩放梯度下降过程的步长;可以通过 learning_rate 参数设置。
参数 learning_rate 与参数 n_estimators(要拟合的弱学习器数量)强相关。较小的 learning_rate 值需要更大的弱学习器数量才能保持恒定的训练误差。经验证据表明,小的 learning_rate 值有利于获得更好的测试误差。[HTF] 建议将学习率设置为较小的常数(例如 learning_rate <= 0.1)并选择足够大的 n_estimators,以便应用提前停止,有关 learning_rate 和 n_estimators 之间交互作用的更详细讨论,请参阅梯度提升中的提前停止,请参阅 [R2007]。
1.11.1.2.6. 子采样#
[Friedman2002] 提出了随机梯度提升,它将梯度提升与引导平均(bagging)相结合。在每次迭代中,基础分类器在可用训练数据的 subsample 部分上进行训练。子样本是无放回抽样。典型的 subsample 值为 0.5。
下图说明了收缩和子采样对模型拟合优度的影响。我们可以清楚地看到收缩优于不收缩。带有收缩的子采样可以进一步提高模型的准确性。另一方面,没有收缩的子采样表现不佳。
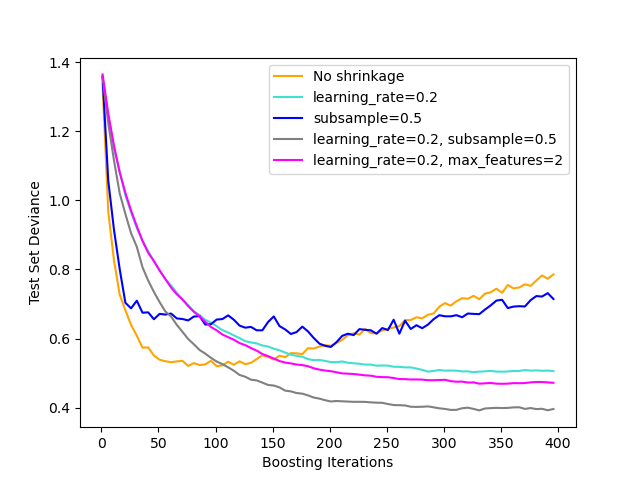
另一种减少方差的策略是子采样特征,类似于 RandomForestClassifier 中的随机分裂。子采样特征的数量可以通过 max_features 参数控制。
注意
使用较小的 max_features 值可以显着缩短运行时间。
随机梯度提升允许通过计算未包含在引导样本中的示例(即袋外示例)的偏差改进来计算袋外测试偏差估计。改进存储在属性 oob_improvement_ 中。oob_improvement_[i] 包含如果在当前预测中添加第 i 个阶段,OOB 样本上的损失改进。袋外估计可用于模型选择,例如确定最佳迭代次数。OOB 估计通常非常悲观,因此我们建议使用交叉验证,并且只有当交叉验证太耗时时才使用 OOB。
示例
1.11.1.2.7. 特征重要性解释#
通过简单地可视化树结构,可以轻松解释单个决策树。然而,梯度提升模型包含数百棵回归树,因此无法通过目视检查单个树来轻松解释。幸运的是,已经提出了许多技术来总结和解释梯度提升模型。
通常,特征对预测目标响应的贡献并不相等;在许多情况下,大多数特征实际上是不相关的。在解释模型时,第一个问题通常是:哪些是重要特征,它们如何有助于预测目标响应?
单个决策树通过选择适当的分裂点来固有地执行特征选择。此信息可用于衡量每个特征的重要性;基本思想是:特征在树的分裂点中使用的频率越高,该特征就越重要。这种重要性概念可以通过简单地平均每棵树基于杂质的特征重要性来扩展到决策树集成(有关更多详细信息,请参见特征重要性评估)。
拟合的梯度提升模型的特征重要性分数可以通过 feature_importances_ 属性访问:
>>> from sklearn.datasets import make_hastie_10_2
>>> from sklearn.ensemble import GradientBoostingClassifier
>>> X, y = make_hastie_10_2(random_state=0)
>>> clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0,
... max_depth=1, random_state=0).fit(X, y)
>>> clf.feature_importances_
array([0.107, 0.105, 0.113, 0.0987, 0.0947,
0.107, 0.0916, 0.0972, 0.0958, 0.0906])
请注意,这种特征重要性计算基于熵,与基于特征排列的 sklearn.inspection.permutation_importance 不同。
示例
References
Friedman, J.H. (2001). Greedy function approximation: A gradient boosting machine. Annals of Statistics, 29, 1189-1232.
Friedman, J.H. (2002). Stochastic gradient boosting.. Computational Statistics & Data Analysis, 38, 367-378.
G. Ridgeway (2006). Generalized Boosted Models: A guide to the gbm package
1.11.2. 随机森林和其他随机树集成#
sklearn.ensemble 模块包含两种基于随机决策树的平均算法:RandomForest 算法和 Extra-Trees 方法。两种算法都是专门为树设计的扰动与组合技术 [B1998]。这意味着通过在分类器构建中引入随机性来创建多样化的分类器集。集成的预测结果是单个分类器预测结果的平均值。
与其他分类器一样,森林分类器必须使用两个数组进行拟合:形状为 (n_samples, n_features) 的稀疏或密集数组 X,其中包含训练样本,以及形状为 (n_samples,) 的数组 Y,其中包含训练样本的目标值(类别标签)。
>>> from sklearn.ensemble import RandomForestClassifier
>>> X = [[0, 0], [1, 1]]
>>> Y = [0, 1]
>>> clf = RandomForestClassifier(n_estimators=10)
>>> clf = clf.fit(X, Y)
与决策树类似,树森林也扩展到多输出问题(如果 Y 的形状为 (n_samples, n_outputs))。
1.11.2.1. 随机森林#
在随机森林中(参见 RandomForestClassifier 和 RandomForestRegressor 类),集成中的每棵树都是从训练集中有放回抽样(即引导样本)构建的。
在构建森林中的每棵树期间,会考虑特征的随机子集。此子集的大小由 max_features 参数控制;它可以包括所有输入特征或它们的随机子集(有关更多详细信息,请参阅参数调优指南)。
这两个随机性来源(引导样本和在每个分裂点随机选择特征)的目的是降低森林估计器的方差。确实,单个决策树通常表现出高方差并且容易过拟合。注入到森林中的随机性会使决策树的预测误差有所解耦。通过对这些预测进行平均,一些误差可以相互抵消。随机森林通过组合多样化的树来实现方差减少,有时会以轻微增加偏差为代价。在实践中,方差减少通常非常显着,从而产生整体更好的模型。
在生长森林中的每棵树时,根据杂质准则选择“最佳”分裂(即相当于向底层决策树传递 splitter="best")。有关更多详细信息,请参阅CART 数学公式。
与原始出版物 [B2001] 不同,scikit-learn 实现通过平均分类器的概率预测来组合分类器,而不是让每个分类器投票选出单个类别。
随机森林的一个有竞争力的替代方案是基于直方图的梯度提升(HGBT)模型。
构建树:随机森林通常依赖于深度树(单独过拟合),这会消耗大量计算资源,因为它们需要进行多次分裂和评估候选分裂。提升模型构建浅树(单独欠拟合),拟合和预测速度更快。
顺序提升:在 HGBT 中,决策树是顺序构建的,其中每棵树都经过训练以纠正前一棵树所犯的错误。这使得它们能够使用相对较少的树迭代地提高模型的性能。相比之下,随机森林使用多数投票来预测结果,这可能需要更多的树才能达到相同的准确性水平。
高效分箱:HGBT 使用高效的分箱算法,可以处理具有大量特征的大型数据集。分箱算法可以对数据进行预处理以加快后续树的构建(参见为什么它更快)。相比之下,scikit-learn 的随机森林实现不使用分箱,而是依赖精确分裂,这在计算上可能很昂贵。
总的来说,HGBT 与 RF 的计算成本取决于数据集的具体特征和建模任务。最好在您的特定问题上尝试这两种模型,比较它们的性能和计算效率,以确定哪个模型最合适。
示例
1.11.2.2. 极端随机树#
在极其随机的树中(见 ExtraTreesClassifier 和 ExtraTreesRegressor 类),随机性在计算分裂的方式上更进一步。与随机森林一样,它使用候选特征的一个随机子集,但不是寻找最具判别性的阈值,而是为每个候选特征随机抽取阈值,并选择这些随机生成的阈值中最好的一个作为分裂规则。这通常可以进一步减少模型的方差,代价是偏差会略微增加
>>> from sklearn.model_selection import cross_val_score
>>> from sklearn.datasets import make_blobs
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.ensemble import ExtraTreesClassifier
>>> from sklearn.tree import DecisionTreeClassifier
>>> X, y = make_blobs(n_samples=10000, n_features=10, centers=100,
... random_state=0)
>>> clf = DecisionTreeClassifier(max_depth=None, min_samples_split=2,
... random_state=0)
>>> scores = cross_val_score(clf, X, y, cv=5)
>>> scores.mean()
np.float64(0.98)
>>> clf = RandomForestClassifier(n_estimators=10, max_depth=None,
... min_samples_split=2, random_state=0)
>>> scores = cross_val_score(clf, X, y, cv=5)
>>> scores.mean()
np.float64(0.999)
>>> clf = ExtraTreesClassifier(n_estimators=10, max_depth=None,
... min_samples_split=2, random_state=0)
>>> scores = cross_val_score(clf, X, y, cv=5)
>>> scores.mean() > 0.999
np.True_
1.11.2.3. 参数#
使用这些方法时要调整的主要参数是 n_estimators 和 max_features。前者是森林中树的数量。数量越多越好,但计算时间也越长。此外,请注意,超过临界数量的树后,结果的改善将不再显著。后者是在分裂节点时考虑的特征随机子集的大小。值越低,方差减少越多,但偏差增加也越多。根据经验,良好的默认值是:对于回归问题,max_features=1.0 或等效地 max_features=None(总是考虑所有特征而不是随机子集);对于分类任务,max_features="sqrt"(使用大小为 sqrt(n_features) 的随机子集)(其中 n_features 是数据中的特征数量)。max_features=1.0 的默认值等效于 bagged trees,通过设置较小的值(例如,文献中典型的默认值是 0.3)可以实现更大的随机性。当设置 max_depth=None 并结合 min_samples_split=2(即完全展开树时)时,通常可以获得良好的结果。但请记住,这些值通常不是最优的,并且可能导致模型消耗大量 RAM。最佳参数值应始终通过交叉验证获得。此外,请注意,在随机森林中,默认使用 bootstrap 样本(bootstrap=True),而 extra-trees 的默认策略是使用整个数据集(bootstrap=False)。当使用 bootstrap 采样时,可以在留下的(out-of-bag)样本上估计泛化误差。这可以通过设置 oob_score=True 来启用。
注意
默认参数下模型的大小为 \(O( M * N * log (N) )\),其中 \(M\) 是树的数量,\(N\) 是样本数量。为了减小模型的大小,您可以更改这些参数:min_samples_split、max_leaf_nodes、max_depth 和 min_samples_leaf。
1.11.2.4. 并行化#
最后,该模块还通过 n_jobs 参数实现了树的并行构建和预测的并行计算。如果 n_jobs=k,则计算被划分为 k 个作业,并在机器的 k 个核心上运行。如果 n_jobs=-1,则使用机器上所有可用的核心。请注意,由于进程间通信开销,加速可能不是线性的(即,使用 k 个作业的速度不幸地不会快 k 倍)。但是,在构建大量树时,或者在构建单个树需要相当长的时间时(例如,在大型数据集上),仍然可以实现显著的加速。
示例
References
Breiman, “Random Forests”, Machine Learning, 45(1), 5-32, 2001.
Breiman, “Arcing Classifiers”, Annals of Statistics 1998.
P. Geurts, D. Ernst., and L. Wehenkel, “Extremely randomized trees”, Machine Learning, 63(1), 3-42, 2006.
1.11.2.5. 特征重要性评估#
特征作为树中决策节点使用的相对排名(即深度)可以用来评估该特征对目标变量可预测性的相对重要性。在树顶部分使用的特征对更大比例的输入样本的最终预测决策有贡献。因此,它们贡献的样本的预期比例可以用作特征相对重要性的估计。在 scikit-learn 中,特征贡献的样本比例与分裂时杂质的减少量相结合,以创建该特征预测能力的标准化估计。
通过对多个随机树的预测能力估计进行平均,可以减少这种估计的方差,并将其用于特征选择。这被称为平均杂质减少量(mean decrease in impurity, MDI)。有关 MDI 和随机森林特征重要性评估的更多信息,请参阅 [L2014]。
警告
基于杂质的特征重要性计算在基于树的模型上存在两个缺陷,可能导致误导性结论。首先,它们是基于训练数据集得出的统计数据计算的,因此不一定能告诉我们哪些特征对于在保留数据集上做出良好预测最重要。其次,它们偏爱高基数特征,即具有许多唯一值的特征。排列特征重要性 是基于杂质的特征重要性的替代方案,它不受这些缺陷的影响。这两种获取特征重要性的方法在以下示例中进行了探讨:排列重要性 vs 随机森林特征重要性 (MDI)。
在实践中,这些估计值作为名为 feature_importances_ 的属性存储在拟合模型上。这是一个形状为 (n_features,) 的数组,其值是正数且总和为 1.0。值越高,匹配特征对预测函数的贡献越重要。
示例
References
G. Louppe, “Understanding Random Forests: From Theory to Practice”, PhD Thesis, U. of Liege, 2014.
1.11.2.6. 完全随机树嵌入#
RandomTreesEmbedding 实现了一种无监督的数据转换。使用完全随机树的森林,RandomTreesEmbedding 通过数据点最终所在的叶子的索引来编码数据。然后以 one-of-K 方式编码此索引,从而得到高维、稀疏的二进制编码。这种编码可以非常有效地计算,然后可以作为其他学习任务的基础。编码的大小和稀疏度可以通过选择树的数量和每棵树的最大深度来影响。对于集成中的每棵树,编码包含一个值为 1 的条目。编码的大小最多为 n_estimators * 2 ** max_depth,即森林中叶子的最大数量。
由于相邻数据点更有可能位于同一树叶中,因此该转换执行隐式的非参数密度估计。
示例
手写数字上的流形学习:局部线性嵌入、Isomap... 比较了手写数字上的非线性降维技术。
使用树集进行特征转换 比较了基于树的监督和非监督特征转换。
另请参阅
流形学习 技术也可用于派生特征空间的非线性表示,尽管这些方法也侧重于降维。
1.11.2.7. 拟合额外的树#
RandomForest、Extra-Trees 和 RandomTreesEmbedding 估计器都支持 warm_start=True,这允许您向已拟合的模型添加更多树。
>>> from sklearn.datasets import make_classification
>>> from sklearn.ensemble import RandomForestClassifier
>>> X, y = make_classification(n_samples=100, random_state=1)
>>> clf = RandomForestClassifier(n_estimators=10)
>>> clf = clf.fit(X, y) # fit with 10 trees
>>> len(clf.estimators_)
10
>>> # set warm_start and increase num of estimators
>>> _ = clf.set_params(n_estimators=20, warm_start=True)
>>> _ = clf.fit(X, y) # fit additional 10 trees
>>> len(clf.estimators_)
20
当同时设置 random_state 时,内部随机状态也会在 fit 调用之间保留。这意味着一次使用 n 个估计器训练模型与通过多次 fit 调用迭代构建模型是相同的,其中最终的估计器数量等于 n。
>>> clf = RandomForestClassifier(n_estimators=20) # set `n_estimators` to 10 + 10
>>> _ = clf.fit(X, y) # fit `estimators_` will be the same as `clf` above
请注意,这与 random_state 的通常行为不同,因为它在不同调用中不会产生相同的结果。
1.11.3. Bagging 元估计器#
在集成算法中,bagging 方法是一类算法,它在原始训练集的随机子集上构建黑盒估计器的多个实例,然后聚合它们的个体预测以形成最终预测。这些方法通过在其构建过程中引入随机性,然后从中创建集成,用于减少基础估计器(例如,决策树)的方差。在许多情况下,bagging 方法是相对于单个模型进行改进的一种非常简单的方法,而无需适应底层基础算法。由于它们提供了一种减少过拟合的方法,bagging 方法最适用于强大而复杂的模型(例如,完全展开的决策树),这与 boosting 方法形成对比,后者通常最适用于弱模型(例如,浅层决策树)。
Bagging 方法有许多变体,但主要区别在于它们抽取训练集随机子集的方式
当抽取数据集的随机子集作为样本的随机子集时,这种算法被称为 Pasting [B1999]。
当有放回地抽取样本时,这种方法被称为 Bagging [B1996]。
当抽取数据集的随机子集作为特征的随机子集时,这种方法被称为 Random Subspaces [H1998]。
最后,当基础估计器在样本和特征的子集上构建时,这种方法被称为 Random Patches [LG2012]。
在 scikit-learn 中,bagging 方法作为一个统一的 BaggingClassifier 元估计器(或 BaggingRegressor)提供,它接受用户指定的估计器以及指定抽取随机子集策略的参数作为输入。特别是,max_samples 和 max_features 控制子集的大小(以样本和特征计),而 bootstrap 和 bootstrap_features 控制样本和特征是带放回还是不带放回抽取。当使用可用样本的子集时,可以通过设置 oob_score=True 在 out-of-bag 样本上估计泛化精度。例如,下面的代码片段演示了如何实例化一个由 KNeighborsClassifier 估计器组成的 bagging 集成,每个估计器都构建在 50% 的样本和 50% 的特征的随机子集上。
>>> from sklearn.ensemble import BaggingClassifier
>>> from sklearn.neighbors import KNeighborsClassifier
>>> bagging = BaggingClassifier(KNeighborsClassifier(),
... max_samples=0.5, max_features=0.5)
示例
References
L. Breiman, “Pasting small votes for classification in large databases and on-line”, Machine Learning, 36(1), 85-103, 1999.
L. Breiman, “Bagging predictors”, Machine Learning, 24(2), 123-140, 1996.
T. Ho, “The random subspace method for constructing decision forests”, Pattern Analysis and Machine Intelligence, 20(8), 832-844, 1998.
G. Louppe and P. Geurts, “Ensembles on Random Patches”, Machine Learning and Knowledge Discovery in Databases, 346-361, 2012.
1.11.4. 投票分类器#
VotingClassifier 背后的想法是结合概念上不同的机器学习分类器,并使用多数投票或平均预测概率(软投票)来预测类别标签。对于一组性能相近的模型,这种分类器可以平衡它们的个体弱点,从而非常有用。
1.11.4.1. 多数类别标签(多数/硬投票)#
在多数投票中,特定样本的预测类别标签是每个单独分类器预测的类别标签的多数(众数)。
例如,如果给定样本的预测是
分类器 1 -> 类别 1
分类器 2 -> 类别 1
分类器 3 -> 类别 2
则 VotingClassifier(使用 voting='hard')将根据多数类别标签将样本分类为“类别 1”。
在平局的情况下,VotingClassifier 将根据升序排序选择类别。例如,在以下情况中
分类器 1 -> 类别 2
分类器 2 -> 类别 1
类别标签 1 将被分配给样本。
1.11.4.2. 用法#
以下示例显示了如何拟合多数规则分类器
>>> from sklearn import datasets
>>> from sklearn.model_selection import cross_val_score
>>> from sklearn.linear_model import LogisticRegression
>>> from sklearn.naive_bayes import GaussianNB
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.ensemble import VotingClassifier
>>> iris = datasets.load_iris()
>>> X, y = iris.data[:, 1:3], iris.target
>>> clf1 = LogisticRegression(random_state=1)
>>> clf2 = RandomForestClassifier(n_estimators=50, random_state=1)
>>> clf3 = GaussianNB()
>>> eclf = VotingClassifier(
... estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)],
... voting='hard')
>>> for clf, label in zip([clf1, clf2, clf3, eclf], ['Logistic Regression', 'Random Forest', 'naive Bayes', 'Ensemble']):
... scores = cross_val_score(clf, X, y, scoring='accuracy', cv=5)
... print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
Accuracy: 0.95 (+/- 0.04) [Logistic Regression]
Accuracy: 0.94 (+/- 0.04) [Random Forest]
Accuracy: 0.91 (+/- 0.04) [naive Bayes]
Accuracy: 0.95 (+/- 0.04) [Ensemble]
1.11.4.3. 加权平均概率(软投票)#
与多数投票(硬投票)相反,软投票返回预测概率总和的 argmax 作为类别标签。
可以通过 weights 参数为每个分类器分配特定权重。当提供权重时,会收集每个分类器的预测类别概率,乘以分类器权重,然后求平均值。然后从具有最高平均概率的类别标签中得出最终类别标签。
为了用一个简单的例子说明,假设我们有 3 个分类器和一个 3 类别分类问题,我们为所有分类器分配相等的权重:w1=1, w2=1, w3=1。
然后,样本的加权平均概率将按如下方式计算
分类器 |
类别 1 |
类别 2 |
类别 3 |
|---|---|---|---|
分类器 1 |
w1 * 0.2 |
w1 * 0.5 |
w1 * 0.3 |
分类器 2 |
w2 * 0.6 |
w2 * 0.3 |
w2 * 0.1 |
分类器 3 |
w3 * 0.3 |
w3 * 0.4 |
w3 * 0.3 |
加权平均值 |
0.37 |
0.4 |
0.23 |
在这里,预测的类别标签是 2,因为它具有最高的平均预测概率。请参阅示例 可视化 VotingClassifier 的概率预测,了解如何从预测概率的加权平均值中获得预测类别标签的演示。
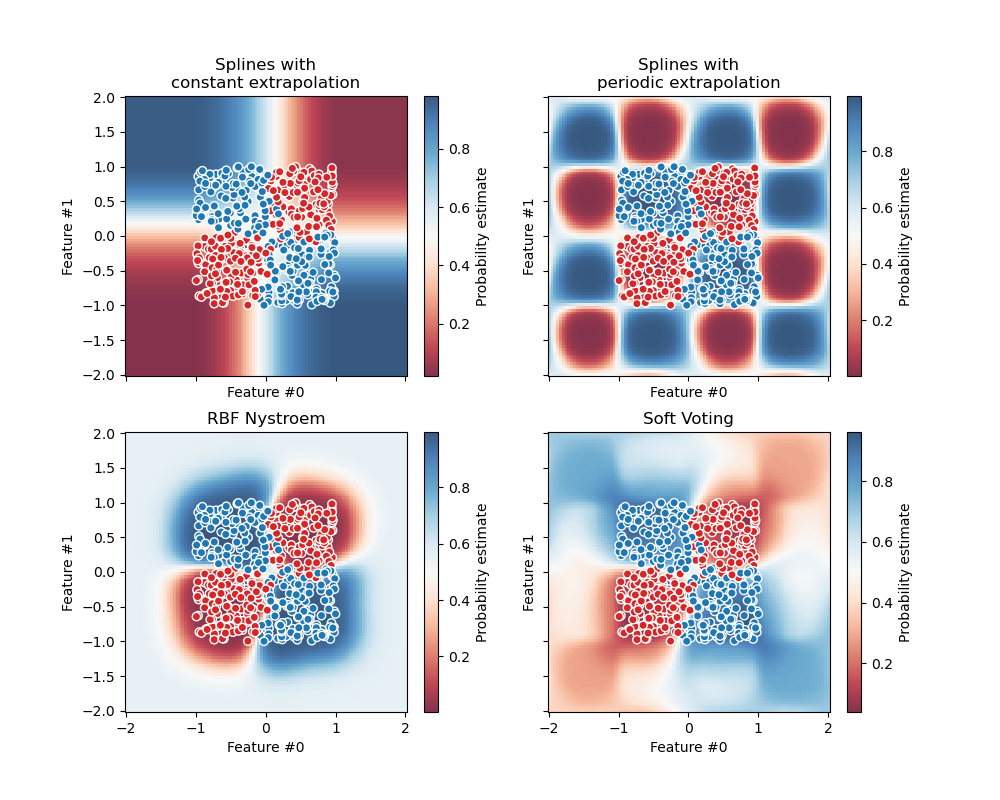
下图说明了当使用权重在三个线性模型上训练软 VotingClassifier 时,决策区域如何变化
1.11.4.4. 用法#
为了根据预测的类别概率预测类别标签(VotingClassifier 中的 scikit-learn 估计器必须支持 predict_proba 方法)
>>> eclf = VotingClassifier(
... estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)],
... voting='soft'
... )
可选地,可以为单个分类器提供权重
>>> eclf = VotingClassifier(
... estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)],
... voting='soft', weights=[2,5,1]
... )
将 VotingClassifier 与 GridSearchCV 一起使用#
VotingClassifier 也可以与 GridSearchCV 一起使用,以调整单个估计器的超参数
>>> from sklearn.model_selection import GridSearchCV
>>> clf1 = LogisticRegression(random_state=1)
>>> clf2 = RandomForestClassifier(random_state=1)
>>> clf3 = GaussianNB()
>>> eclf = VotingClassifier(
... estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)],
... voting='soft'
... )
>>> params = {'lr__C': [1.0, 100.0], 'rf__n_estimators': [20, 200]}
>>> grid = GridSearchCV(estimator=eclf, param_grid=params, cv=5)
>>> grid = grid.fit(iris.data, iris.target)
1.11.5. 投票回归器#
VotingRegressor 背后的想法是结合概念上不同的机器学习回归器并返回平均预测值。对于一组性能相近的模型,这种回归器可以平衡它们的个体弱点,从而非常有用。
1.11.5.1. 用法#
以下示例显示了如何拟合 VotingRegressor
>>> from sklearn.datasets import load_diabetes
>>> from sklearn.ensemble import GradientBoostingRegressor
>>> from sklearn.ensemble import RandomForestRegressor
>>> from sklearn.linear_model import LinearRegression
>>> from sklearn.ensemble import VotingRegressor
>>> # Loading some example data
>>> X, y = load_diabetes(return_X_y=True)
>>> # Training classifiers
>>> reg1 = GradientBoostingRegressor(random_state=1)
>>> reg2 = RandomForestRegressor(random_state=1)
>>> reg3 = LinearRegression()
>>> ereg = VotingRegressor(estimators=[('gb', reg1), ('rf', reg2), ('lr', reg3)])
>>> ereg = ereg.fit(X, y)
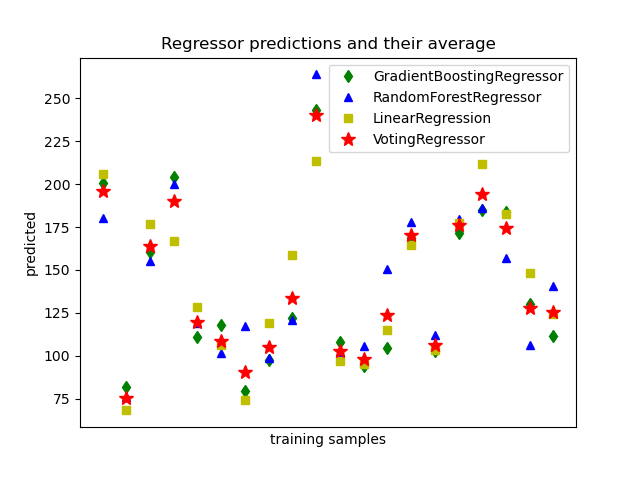
示例
1.11.6. 堆叠泛化#
堆叠泛化是一种结合估计器以减少其偏差的方法 [W1992] [HTF]。更准确地说,每个单独估计器的预测被堆叠在一起,并用作最终估计器的输入来计算预测。这个最终估计器是通过交叉验证训练的。
StackingClassifier 和 StackingRegressor 提供了此类策略,可应用于分类和回归问题。
estimators 参数对应于并行堆叠在输入数据上的估计器列表。它应该以名称和估计器列表的形式给出
>>> from sklearn.linear_model import RidgeCV, LassoCV
>>> from sklearn.neighbors import KNeighborsRegressor
>>> estimators = [('ridge', RidgeCV()),
... ('lasso', LassoCV(random_state=42)),
... ('knr', KNeighborsRegressor(n_neighbors=20,
... metric='euclidean'))]
final_estimator 将使用 estimators 的预测作为输入。当使用 StackingClassifier 或 StackingRegressor 时,它需要是一个分类器或回归器
>>> from sklearn.ensemble import GradientBoostingRegressor
>>> from sklearn.ensemble import StackingRegressor
>>> final_estimator = GradientBoostingRegressor(
... n_estimators=25, subsample=0.5, min_samples_leaf=25, max_features=1,
... random_state=42)
>>> reg = StackingRegressor(
... estimators=estimators,
... final_estimator=final_estimator)
为了训练 estimators 和 final_estimator,需要对训练数据调用 fit 方法
>>> from sklearn.datasets import load_diabetes
>>> X, y = load_diabetes(return_X_y=True)
>>> from sklearn.model_selection import train_test_split
>>> X_train, X_test, y_train, y_test = train_test_split(X, y,
... random_state=42)
>>> reg.fit(X_train, y_train)
StackingRegressor(...)
在训练期间,estimators 在整个训练数据 X_train 上拟合。它们将在调用 predict 或 predict_proba 时使用。为了泛化并避免过拟合,final_estimator 使用 sklearn.model_selection.cross_val_predict 内部训练 out-samples。
对于 StackingClassifier,请注意 estimators 的输出由参数 stack_method 控制,并且由每个估计器调用。此参数要么是一个字符串(即估计器方法名称),要么是 'auto',它将根据可用性自动识别可用方法,按偏好顺序测试:predict_proba、decision_function 和 predict。
与任何其他回归器或分类器一样,StackingRegressor 和 StackingClassifier 暴露了 predict、predict_proba 或 decision_function 方法,例如
>>> y_pred = reg.predict(X_test)
>>> from sklearn.metrics import r2_score
>>> print('R2 score: {:.2f}'.format(r2_score(y_test, y_pred)))
R2 score: 0.53
请注意,也可以使用 transform 方法获取堆叠 estimators 的输出
>>> reg.transform(X_test[:5])
array([[142, 138, 146],
[179, 182, 151],
[139, 132, 158],
[286, 292, 225],
[126, 124, 164]])
在实践中,堆叠预测器的预测效果与基础层中最好的预测器一样好,有时甚至通过结合这些预测器的不同优点而超越它。然而,训练堆叠预测器在计算上是昂贵的。
注意
对于 StackingClassifier,当使用 stack_method_='predict_proba' 时,如果问题是二元分类问题,则会丢弃第一列。事实上,每个估计器预测的两个概率列是完全共线的。
注意
通过将 final_estimator 分配给 StackingClassifier 或 StackingRegressor,可以实现多层堆叠
>>> final_layer_rfr = RandomForestRegressor(
... n_estimators=10, max_features=1, max_leaf_nodes=5,random_state=42)
>>> final_layer_gbr = GradientBoostingRegressor(
... n_estimators=10, max_features=1, max_leaf_nodes=5,random_state=42)
>>> final_layer = StackingRegressor(
... estimators=[('rf', final_layer_rfr),
... ('gbrt', final_layer_gbr)],
... final_estimator=RidgeCV()
... )
>>> multi_layer_regressor = StackingRegressor(
... estimators=[('ridge', RidgeCV()),
... ('lasso', LassoCV(random_state=42)),
... ('knr', KNeighborsRegressor(n_neighbors=20,
... metric='euclidean'))],
... final_estimator=final_layer
... )
>>> multi_layer_regressor.fit(X_train, y_train)
StackingRegressor(...)
>>> print('R2 score: {:.2f}'
... .format(multi_layer_regressor.score(X_test, y_test)))
R2 score: 0.53
示例
References
Wolpert, David H. “Stacked generalization.” Neural networks 5.2 (1992): 241-259.
1.11.7. AdaBoost#
模块 sklearn.ensemble 包括流行的 boosting 算法 AdaBoost,该算法由 Freund 和 Schapire 于 1995 年提出 [FS1995]。
AdaBoost 的核心原理是在数据的反复修改版本上拟合一系列弱学习器(即,仅比随机猜测稍好的模型,例如小的决策树)。然后通过加权多数投票(或求和)将所有弱学习器的预测结合起来,以产生最终预测。在每次所谓的 boosting 迭代中,数据修改包括对每个训练样本应用权重 \(w_1\), \(w_2\), …, \(w_N\)。最初,这些权重都设置为 \(w_i = 1/N\),因此第一步只是在原始数据上训练一个弱学习器。对于每次后续迭代,样本权重都会单独修改,并将学习算法重新应用于重新加权的数据。在给定步骤中,那些被前一步骤产生的 boosting 模型错误预测的训练示例的权重会增加,而那些被正确预测的示例的权重会减少。随着迭代的进行,难以预测的示例会获得不断增加的影响力。因此,每个后续弱学习器被迫集中于序列中前一个学习器遗漏的示例 [HTF]。
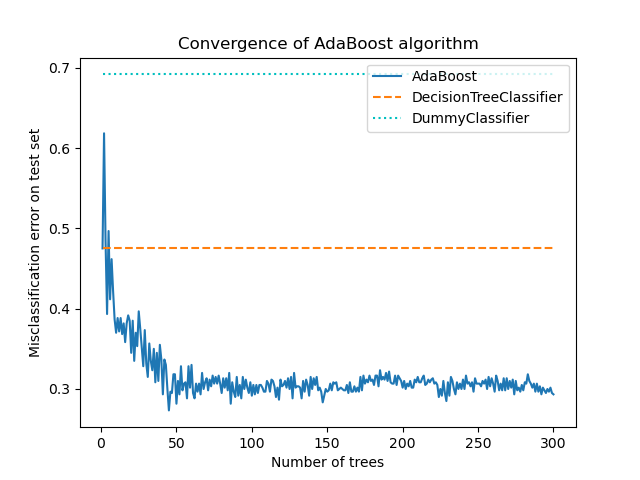
AdaBoost 可用于分类和回归问题
对于多类别分类,
AdaBoostClassifier实现了 AdaBoost.SAMME [ZZRH2009]。对于回归,
AdaBoostRegressor实现了 AdaBoost.R2 [D1997]。
1.11.7.1. 用法#
以下示例显示了如何拟合具有 100 个弱学习器的 AdaBoost 分类器
>>> from sklearn.model_selection import cross_val_score
>>> from sklearn.datasets import load_iris
>>> from sklearn.ensemble import AdaBoostClassifier
>>> X, y = load_iris(return_X_y=True)
>>> clf = AdaBoostClassifier(n_estimators=100)
>>> scores = cross_val_score(clf, X, y, cv=5)
>>> scores.mean()
np.float64(0.95)
弱学习器的数量由参数 n_estimators 控制。learning_rate 参数控制弱学习器在最终组合中的贡献。默认情况下,弱学习器是决策树桩。可以通过 estimator 参数指定不同的弱学习器。调整以获得良好结果的主要参数是 n_estimators 和基础估计器的复杂性(例如,其深度 max_depth 或考虑分裂所需的最小样本数 min_samples_split)。
示例
多类别 AdaBoosted 决策树 显示了 AdaBoost 在多类别问题上的性能。
两类别 AdaBoost 显示了使用 AdaBoost-SAMME 对非线性可分离的两类别问题的决策边界和决策函数值。
使用 AdaBoost 的决策树回归 演示了使用 AdaBoost.R2 算法进行回归。
References