1.6. 最近邻#
sklearn.neighbors 提供了基于邻居的无监督和有监督学习方法的功能。无监督最近邻是许多其他学习方法的基础,特别是流形学习和谱聚类。有监督的基于邻居的学习有两种形式:具有离散标签的数据的分类,以及具有连续标签的数据的回归。
最近邻方法的原理是找到距离新点最近的预定义数量的训练样本,并根据这些样本预测标签。样本数量可以是用户定义的常数(k-最近邻学习),也可以根据点的局部密度(基于半径的邻居学习)而变化。距离通常可以是任何度量:标准欧几里得距离是最常见的选择。基于邻居的方法被称为 非泛化 机器学习方法,因为它们只是“记住”所有训练数据(可能转换为快速索引结构,例如球树或KD树)。
尽管其简单,最近邻在大量分类和回归问题中取得了成功,包括手写数字和卫星图像场景。作为一种非参数方法,它在决策边界非常不规则的分类情况下通常很成功。
sklearn.neighbors 中的类可以处理 NumPy 数组或 scipy.sparse 矩阵作为输入。对于稠密矩阵,支持大量可能的距离度量。对于稀疏矩阵,支持任意 Minkowski 度量进行搜索。
有许多学习例程其核心依赖于最近邻。一个例子是核密度估计,在密度估计部分讨论。
1.6.1. 无监督最近邻#
NearestNeighbors 实现了无监督最近邻学习。它作为三种不同最近邻算法的统一接口:BallTree、KDTree 以及基于sklearn.metrics.pairwise 中例程的暴力算法。邻居搜索算法的选择通过关键字 'algorithm' 控制,该关键字必须是 ['auto', 'ball_tree', 'kd_tree', 'brute'] 之一。当传入默认值 'auto' 时,算法会尝试从训练数据中确定最佳方法。关于每个选项的优缺点讨论,请参阅最近邻算法。
警告
关于最近邻算法,如果两个邻居 \(k+1\) 和 \(k\) 具有相同的距离但标签不同,结果将取决于训练数据的顺序。
1.6.1.1. 查找最近邻#
对于查找两组数据之间最近邻的简单任务,可以使用sklearn.neighbors 中的无监督算法
>>> from sklearn.neighbors import NearestNeighbors
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> nbrs = NearestNeighbors(n_neighbors=2, algorithm='ball_tree').fit(X)
>>> distances, indices = nbrs.kneighbors(X)
>>> indices
array([[0, 1],
[1, 0],
[2, 1],
[3, 4],
[4, 3],
[5, 4]]...)
>>> distances
array([[0. , 1. ],
[0. , 1. ],
[0. , 1.41421356],
[0. , 1. ],
[0. , 1. ],
[0. , 1.41421356]])
由于查询集与训练集匹配,每个点的最近邻是点本身,距离为零。
也可以有效地生成一个稀疏图,显示相邻点之间的连接
>>> nbrs.kneighbors_graph(X).toarray()
array([[1., 1., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0.],
[0., 1., 1., 0., 0., 0.],
[0., 0., 0., 1., 1., 0.],
[0., 0., 0., 1., 1., 0.],
[0., 0., 0., 0., 1., 1.]])
数据集的结构使得索引顺序上相邻的点在参数空间中也相邻,从而导致K-最近邻的近似块对角矩阵。这种稀疏图在各种利用点之间空间关系进行无监督学习的情况下很有用:特别是,请参阅Isomap、LocallyLinearEmbedding 和SpectralClustering。
1.6.1.2. KDTree 和 BallTree 类#
或者,可以直接使用 KDTree 或 BallTree 类来查找最近邻。这是上面使用的 NearestNeighbors 类封装的功能。球树和KD树具有相同的接口;我们将在这里展示一个使用KD树的示例
>>> from sklearn.neighbors import KDTree
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> kdt = KDTree(X, leaf_size=30, metric='euclidean')
>>> kdt.query(X, k=2, return_distance=False)
array([[0, 1],
[1, 0],
[2, 1],
[3, 4],
[4, 3],
[5, 4]]...)
有关最近邻搜索可用选项的更多信息,包括查询策略、距离度量等,请参阅KDTree 和 BallTree 类文档。要获取有效度量列表,请使用 KDTree.valid_metrics 和 BallTree.valid_metrics。
>>> from sklearn.neighbors import KDTree, BallTree
>>> KDTree.valid_metrics
['euclidean', 'l2', 'minkowski', 'p', 'manhattan', 'cityblock', 'l1', 'chebyshev', 'infinity']
>>> BallTree.valid_metrics
['euclidean', 'l2', 'minkowski', 'p', 'manhattan', 'cityblock', 'l1', 'chebyshev', 'infinity', 'seuclidean', 'mahalanobis', 'hamming', 'canberra', 'braycurtis', 'jaccard', 'dice', 'rogerstanimoto', 'russellrao', 'sokalmichener', 'sokalsneath', 'haversine', 'pyfunc']
1.6.2. 最近邻分类#
基于邻居的分类是一种 基于实例的学习 或 非泛化学习:它不尝试构建通用的内部模型,而只是存储训练数据实例。分类是通过其最近邻的简单多数投票来计算的:查询点被分配给在点最近邻中代表最多的数据类别。
scikit-learn 实现了两种不同的最近邻分类器:KNeighborsClassifier 实现了基于每个查询点的 \(k\) 个最近邻的学习,其中 \(k\) 是用户指定的整数值。RadiusNeighborsClassifier 实现了基于每个训练点固定半径 \(r\) 内邻居数量的学习,其中 \(r\) 是用户指定的浮点值。
KNeighborsClassifier 中的 \(k\)-邻居分类是最常用的技术。 \(k\) 值的最佳选择高度依赖于数据:通常,较大的 \(k\) 会抑制噪声的影响,但会使分类边界不那么清晰。
在数据未均匀采样的情况下,RadiusNeighborsClassifier 中的基于半径的邻居分类可能是一个更好的选择。用户指定一个固定半径 \(r\),这样在稀疏邻域中的点使用较少的最近邻进行分类。对于高维参数空间,由于所谓的“维度诅咒”,这种方法的效果会降低。
基本的最近邻分类使用统一权重:也就是说,分配给查询点的值是根据最近邻的简单多数投票计算的。在某些情况下,最好对邻居进行加权,使较近的邻居对拟合的贡献更大。这可以通过 weights 关键字来实现。默认值 weights = 'uniform' 为每个邻居分配统一权重。weights = 'distance' 根据距离查询点的距离的倒数分配权重。另外,可以提供用户定义的距离函数来计算权重。
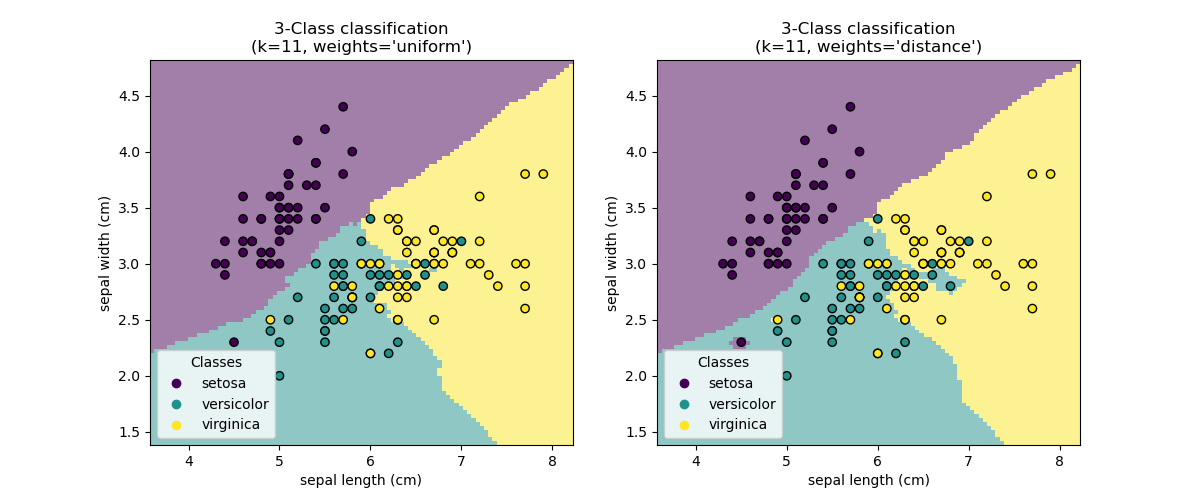
示例
最近邻分类:使用最近邻进行分类的示例。
1.6.3. 最近邻回归#
基于邻居的回归可用于数据标签是连续变量而不是离散变量的情况。分配给查询点的标签是根据其最近邻的标签均值计算的。
scikit-learn 实现了两种不同的邻居回归器:KNeighborsRegressor 实现了基于每个查询点的 \(k\) 个最近邻的学习,其中 \(k\) 是用户指定的整数值。RadiusNeighborsRegressor 实现了基于查询点固定半径 \(r\) 内邻居的学习,其中 \(r\) 是用户指定的浮点值。
基本的最近邻回归使用统一权重:也就是说,局部邻域中的每个点都对查询点的分类做出统一贡献。在某些情况下,对点进行加权可能是有利的,使得附近的点对回归的贡献大于远处的点。这可以通过 weights 关键字来实现。默认值 weights = 'uniform' 为所有点分配相同的权重。weights = 'distance' 根据距离查询点的距离的倒数分配权重。另外,可以提供用户定义的距离函数,该函数将用于计算权重。
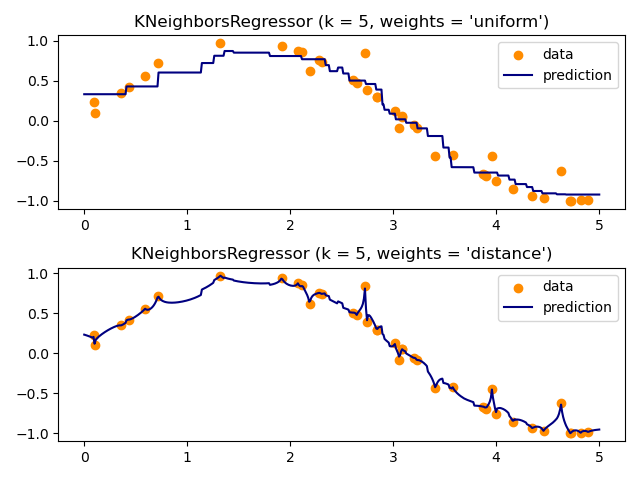
多输出最近邻回归的用法在使用多输出估计器完成人脸中进行了演示。在此示例中,输入 X 是人脸上半部分的像素,输出 Y 是这些人脸下半部分的像素。

示例
最近邻回归:使用最近邻进行回归的示例。
使用多输出估计器完成人脸:使用最近邻进行多输出回归的示例。
1.6.4. 最近邻算法#
1.6.4.1. 暴力法#
最近邻的快速计算是机器学习中的一个活跃研究领域。最简单的邻居搜索实现涉及到对数据集中所有点对之间的距离进行暴力计算:对于 \(D\) 维中的 \(N\) 个样本,这种方法的时间复杂度为 \(O[D N^2]\)。对于小型数据样本,高效的暴力邻居搜索可能非常有竞争力。然而,随着样本数量 \(N\) 的增加,暴力方法很快变得不可行。在 sklearn.neighbors 中的类中,暴力邻居搜索通过关键字 algorithm = 'brute' 指定,并使用 sklearn.metrics.pairwise 中可用的例程进行计算。
1.6.4.2. K-D 树#
为了解决暴力方法的计算效率低下问题,人们发明了各种基于树的数据结构。通常,这些结构试图通过有效地编码样本的聚合距离信息来减少所需的距离计算次数。基本思想是,如果点 \(A\) 离点 \(B\) 很远,而点 \(B\) 离点 \(C\) 很近,那么我们知道点 \(A\) 和 \(C\) 距离很远,而无需显式计算它们的距离。通过这种方式,最近邻搜索的计算成本可以降低到 \(O[D N \log(N)]\) 或更好。对于大型 \(N\),这是对暴力法的显著改进。
利用这种聚合信息的一种早期方法是 KD 树 数据结构(K 维树 的缩写),它将二维 四叉树 和三维 八叉树 推广到任意维数。KD 树是一种二叉树结构,它沿数据轴递归地划分参数空间,将其划分为嵌套的正交区域,数据点被归档到其中。KD 树的构建非常快:因为划分只沿数据轴进行,不需要计算 \(D\) 维距离。一旦构建完成,查询点的最近邻可以在仅 \(O[\log(N)]\) 次距离计算中确定。尽管 KD 树方法对于低维(\(D < 20\))邻居搜索非常快,但当 \(D\) 变得非常大时,它变得效率低下:这是所谓的“维度诅咒”的一种体现。在 scikit-learn 中,KD 树邻居搜索使用关键字 algorithm = 'kd_tree' 指定,并使用 KDTree 类进行计算。
参考文献#
“用于关联搜索的多维二叉搜索树”, Bentley, J.L., Communications of the ACM (1975)
1.6.4.3. 球树#
为了解决KD树在高维中的效率低下问题,开发了 球树 数据结构。KD树沿笛卡尔轴划分数据,而球树则在一系列嵌套的超球面中划分数据。这使得树的构建比KD树更昂贵,但生成的数据结构在高度结构化的数据上,即使在非常高维中,也可能非常高效。
球树递归地将数据划分为由质心 \(C\) 和半径 \(r\) 定义的节点,使得节点中的每个点都位于由 \(r\) 和 \(C\) 定义的超球内。通过使用 三角不等式 减少了邻居搜索的候选点数量
通过这种设置,测试点与质心之间的单次距离计算足以确定节点内所有点的距离的下限和上限。由于球树节点的球形几何特性,它在高维中可以优于 KD-树,尽管实际性能高度依赖于训练数据的结构。在 scikit-learn 中,基于球树的邻居搜索使用关键字 algorithm = 'ball_tree' 指定,并使用 BallTree 类进行计算。另外,用户可以直接使用 BallTree 类。
参考文献#
“五种球树构建算法”, Omohundro, S.M., 国际计算机科学研究所技术报告 (1989)
最近邻算法的选择#
给定数据集的最佳算法选择是一个复杂的决定,取决于多种因素
样本数量 \(N\) (即
n_samples) 和维度 \(D\) (即n_features)。暴力法 查询时间增长为 \(O[D N]\)
球树 查询时间大约增长为 \(O[D \log(N)]\)
KD 树 查询时间随 \(D\) 的变化而变化,难以精确描述。对于小 \(D\)(小于 20 左右),成本约为 \(O[D\log(N)]\),KD 树查询可以非常高效。对于较大的 \(D\),成本增加到接近 \(O[DN]\),并且树结构带来的开销可能导致查询比暴力法慢。
对于小型数据集(\(N\) 小于 30 左右),\(\log(N)\) 与 \(N\) 相当,暴力算法可能比基于树的方法更有效。
KDTree和BallTree都通过提供 叶子大小 参数来解决这个问题:它控制查询何时切换到暴力法的样本数量。这使得两种算法在小 \(N\) 时都能接近暴力计算的效率。数据结构:数据的 内在维度 和/或数据的 稀疏性。内在维度指的是数据所在的流形的维度 \(d \le D\),它可以线性或非线性地嵌入在参数空间中。稀疏性指的是数据填充参数空间的程度(这与“稀疏”矩阵中使用的概念不同。数据矩阵可能没有零条目,但从这个意义上讲,其 结构 仍然可以是“稀疏”的)。
暴力法 查询时间不受数据结构影响。
球树 和 KD 树 查询时间可能受到数据结构的极大影响。一般来说,内在维度较小的稀疏数据会导致更快的查询时间。由于 KD 树的内部表示与参数轴对齐,对于任意结构化数据,它通常不会像球树那样显示出显著的改进。
机器学习中使用的数据集往往结构化程度很高,非常适合基于树的查询。
查询点请求的邻居数 \(k\)。
暴力法 查询时间基本上不受 \(k\) 值的影响
球树 和 KD 树 查询时间会随着 \(k\) 的增加而变慢。这主要是由于两个影响:首先,较大的 \(k\) 导致需要搜索更大的参数空间。其次,使用 \(k > 1\) 需要在遍历树时对结果进行内部排队。
当 \(k\) 相对于 \(N\) 变得很大时,基于树的查询中修剪分支的能力会降低。在这种情况下,暴力查询可能更高效。
查询点数。球树和KD树都需要一个构建阶段。当分摊到许多查询时,此构建的成本可以忽略不计。但是,如果只执行少量查询,则构建可能占总成本的很大一部分。如果只需要很少的查询点,则暴力法优于基于树的方法。
目前,如果满足以下任何条件,algorithm = 'auto' 将选择 'brute'
输入数据是稀疏的
metric = 'precomputed'\(D > 15\)
\(k >= N/2\)
effective_metric_不在'kd_tree'或'ball_tree'的VALID_METRICS列表中
否则,它将从 'kd_tree' 和 'ball_tree' 中选择第一个在其 VALID_METRICS 列表中包含 effective_metric_ 的算法。此启发式方法基于以下假设
查询点的数量至少与训练点的数量处于同一数量级
leaf_size接近其默认值30当 \(D > 15\) 时,数据的内在维度通常对于基于树的方法来说太高了
`leaf_size` 的影响#
如上所述,对于小样本量,暴力搜索可能比基于树的查询更有效。球树和KD树通过在叶节点内切换到暴力搜索来解决这个问题。此切换的级别可以通过参数 leaf_size 指定。此参数选择有多种影响
- 构建时间
较大的
leaf_size会导致更快的树构建时间,因为需要创建的节点更少- 查询时间
大或小的
leaf_size都可能导致次优的查询成本。当leaf_size接近 1 时,遍历节点涉及的开销会显著减慢查询时间。当leaf_size接近训练集大小时,查询基本上变为暴力搜索。一个好的折衷方案是leaf_size = 30,这是参数的默认值。- 内存
随着
leaf_size的增加,存储树结构所需的内存会减少。这在球树的情况下尤其重要,它为每个节点存储一个 \(D\) 维质心。BallTree所需的存储空间大约是训练集大小的1 / leaf_size倍。
暴力查询不引用 leaf_size。
最近邻算法的有效度量#
有关可用指标的列表,请参阅 DistanceMetric 类的文档以及 sklearn.metrics.pairwise.PAIRWISE_DISTANCE_FUNCTIONS 中列出的指标。请注意,“余弦”指标使用 cosine_distances。
通过使用它们的 valid_metric 属性,可以获取上述任何算法的有效度量列表。例如,KDTree 的有效度量可以通过以下方式生成
>>> from sklearn.neighbors import KDTree
>>> print(sorted(KDTree.valid_metrics))
['chebyshev', 'cityblock', 'euclidean', 'infinity', 'l1', 'l2', 'manhattan', 'minkowski', 'p']
1.6.5. 最近质心分类器#
NearestCentroid 分类器是一个简单的算法,它通过其成员的质心来表示每个类别。实际上,这使得它类似于 KMeans 算法的标签更新阶段。它也没有参数可供选择,这使其成为一个很好的基线分类器。然而,它在非凸类别以及类别方差差异很大时会受到影响,因为它假设所有维度上的方差相等。有关不作此假设的更复杂方法,请参阅线性判别分析(LinearDiscriminantAnalysis)和二次判别分析(QuadraticDiscriminantAnalysis)。默认 NearestCentroid 的使用很简单
>>> from sklearn.neighbors import NearestCentroid
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> y = np.array([1, 1, 1, 2, 2, 2])
>>> clf = NearestCentroid()
>>> clf.fit(X, y)
NearestCentroid()
>>> print(clf.predict([[-0.8, -1]]))
[1]
1.6.5.1. 最近收缩质心#
NearestCentroid 分类器有一个 shrink_threshold 参数,它实现了最近收缩质心分类器。实际上,每个质心的每个特征值都除以该特征的类内方差。然后,特征值通过 shrink_threshold 减小。最值得注意的是,如果某个特定特征值穿过零,则将其设置为零。实际上,这会使该特征不再影响分类。例如,这对于去除噪声特征很有用。
在下面的示例中,使用较小的收缩阈值将模型的准确度从 0.81 提高到 0.82。
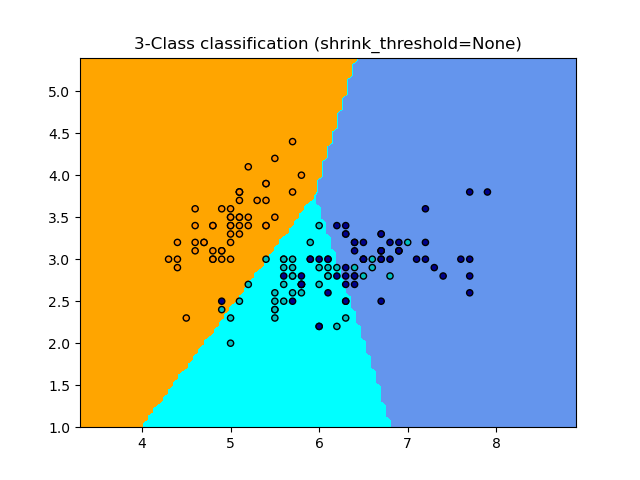
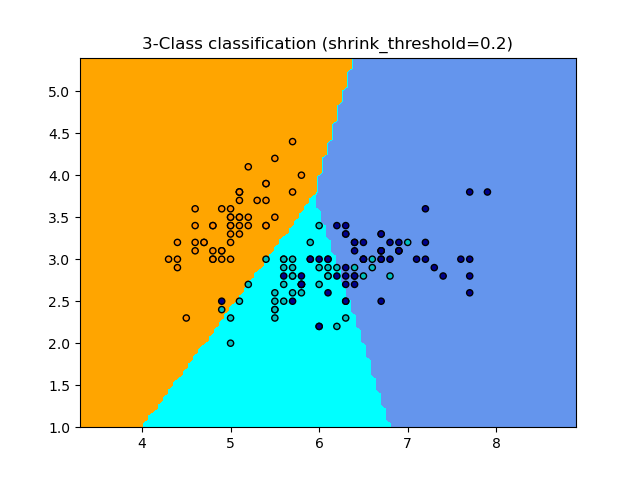
示例
最近质心分类:使用不同收缩阈值的最近质心分类示例。
1.6.6. 最近邻转换器#
许多 scikit-learn 估计器都依赖于最近邻:一些分类器和回归器,例如 KNeighborsClassifier 和 KNeighborsRegressor,还有一些聚类方法,例如 DBSCAN 和 SpectralClustering,以及一些流形嵌入,例如 TSNE 和 Isomap。
所有这些估计器都可以内部计算最近邻,但它们中的大多数也接受预计算的最近邻稀疏图,如 kneighbors_graph 和 radius_neighbors_graph 所提供的。在 mode='connectivity' 模式下,这些函数返回一个二进制邻接稀疏图,例如 SpectralClustering 中所需的。而在 mode='distance' 模式下,它们返回一个距离稀疏图,例如 DBSCAN 中所需的。要将这些函数包含在 scikit-learn 管道中,也可以使用相应的类 KNeighborsTransformer 和 RadiusNeighborsTransformer。这种稀疏图 API 的好处是多方面的。
首先,预计算的图可以多次重用,例如在改变估计器参数时。这可以由用户手动完成,或者使用 scikit-learn 管道的缓存特性
>>> import tempfile
>>> from sklearn.manifold import Isomap
>>> from sklearn.neighbors import KNeighborsTransformer
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.datasets import make_regression
>>> cache_path = tempfile.gettempdir() # we use a temporary folder here
>>> X, _ = make_regression(n_samples=50, n_features=25, random_state=0)
>>> estimator = make_pipeline(
... KNeighborsTransformer(mode='distance'),
... Isomap(n_components=3, metric='precomputed'),
... memory=cache_path)
>>> X_embedded = estimator.fit_transform(X)
>>> X_embedded.shape
(50, 3)
其次,预计算图可以对最近邻估计进行更精细的控制,例如通过参数 n_jobs 启用多进程,这可能在所有估计器中都不可用。
最后,预计算可以通过自定义估计器执行,以使用不同的实现,例如近似最近邻方法或具有特殊数据类型的实现。预计算的邻居稀疏图需要格式化为radius_neighbors_graph 的输出形式
一个 CSR 矩阵(尽管 COO、CSC 或 LIL 也可以接受)。
仅明确存储每个样本相对于训练数据的最近邻。这应包括距离查询点为0的邻居,包括在计算训练数据本身与训练数据之间的最近邻时的矩阵对角线。
每行的
data应该以升序存储距离(可选。未排序的数据将进行稳定排序,增加计算开销)。data 中的所有值应为非负。
任何行中都不应有重复的
indices(参见 scipy/scipy#5807)。如果将预计算矩阵传递给的算法使用 k 最近邻(而不是半径邻域),则每行必须存储至少 k 个邻居(或 k+1,如以下说明中所述)。
注意
当查询特定数量的邻居时(使用 KNeighborsTransformer),n_neighbors 的定义是模糊的,因为它既可以包含每个训练点作为其自身的邻居,也可以排除它们。两种选择都不是完美的,因为包含它们会导致训练和测试期间的非自邻居数量不同,而排除它们则会导致 fit(X).transform(X) 和 fit_transform(X) 之间存在差异,这与 scikit-learn API 相悖。在 KNeighborsTransformer 中,我们使用将每个训练点作为其自身邻居包含在 n_neighbors 计数中的定义。然而,为了与其他使用不同定义的估计器兼容,当 mode == 'distance' 时,将计算一个额外的邻居。为了最大限度地与所有估计器兼容,一个安全的选择是在自定义最近邻估计器中始终包含一个额外的邻居,因为不必要的邻居将被后续估计器过滤掉。
示例
TSNE 中的近似最近邻:一个管道示例,将
KNeighborsTransformer和TSNE结合使用。还提出了两个基于外部包的自定义最近邻估计器。缓存最近邻:一个管道示例,将
KNeighborsTransformer和KNeighborsClassifier结合使用,以便在超参数网格搜索期间缓存邻居图。
1.6.7. 邻域成分分析#
邻域成分分析(NCA,NeighborhoodComponentsAnalysis)是一种距离度量学习算法,旨在与标准欧几里得距离相比,提高最近邻分类的准确性。该算法直接最大化训练集上留一法 k-最近邻(KNN)分数的随机变体。它还可以学习数据的低维线性投影,可用于数据可视化和快速分类。
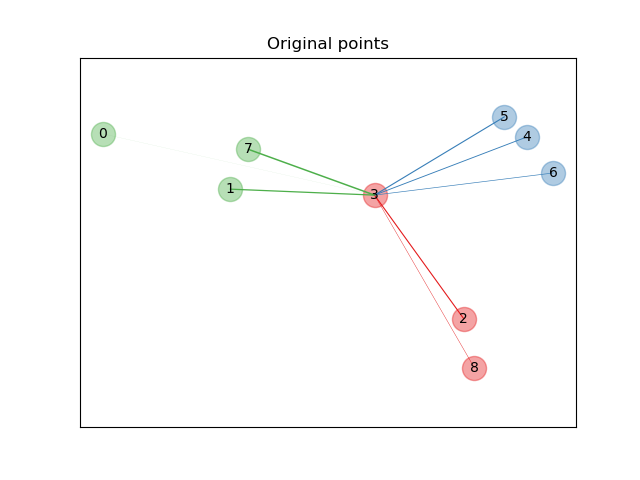
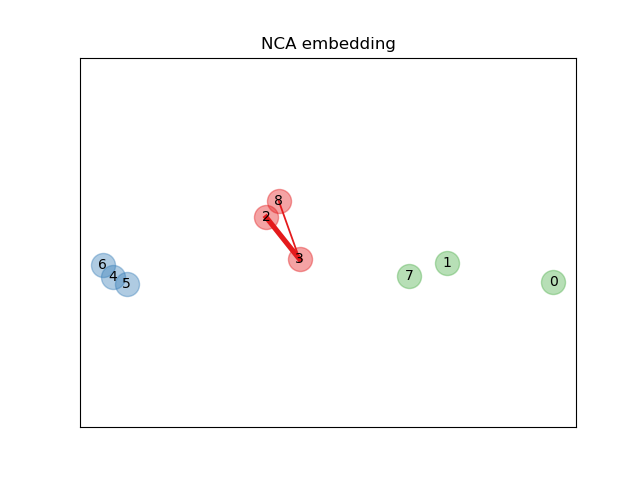
在上面的示意图中,我们考虑了随机生成数据集中的一些点。我们关注点编号为 3 的随机 KNN 分类。样本 3 与另一点之间链接的粗细与它们之间的距离成正比,可以看作是随机最近邻预测规则将分配给该点的相对权重(或概率)。在原始空间中,样本 3 有许多来自不同类别的随机邻居,因此正确的类别不太可能。然而,在 NCA 学习的投影空间中,唯一具有不可忽略权重的随机邻居与样本 3 属于同一类别,保证了后者将被正确分类。有关更多详细信息,请参阅数学公式。
1.6.7.1. 分类#
结合最近邻分类器(KNeighborsClassifier),NCA 对于分类很有吸引力,因为它可以自然地处理多类别问题而无需增加模型大小,并且不会引入需要用户微调的额外参数。
NCA 分类已被证明在各种大小和难度的数据集上实际表现良好。与线性判别分析等相关方法不同,NCA 不对类别分布做任何假设。最近邻分类可以自然地产生高度不规则的决策边界。
要将此模型用于分类,需要将学习最佳变换的 NeighborhoodComponentsAnalysis 实例与在投影空间中执行分类的 KNeighborsClassifier 实例结合起来。这是一个使用这两个类的示例
>>> from sklearn.neighbors import (NeighborhoodComponentsAnalysis,
... KNeighborsClassifier)
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.pipeline import Pipeline
>>> X, y = load_iris(return_X_y=True)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y,
... stratify=y, test_size=0.7, random_state=42)
>>> nca = NeighborhoodComponentsAnalysis(random_state=42)
>>> knn = KNeighborsClassifier(n_neighbors=3)
>>> nca_pipe = Pipeline([('nca', nca), ('knn', knn)])
>>> nca_pipe.fit(X_train, y_train)
Pipeline(...)
>>> print(nca_pipe.score(X_test, y_test))
0.96190476...
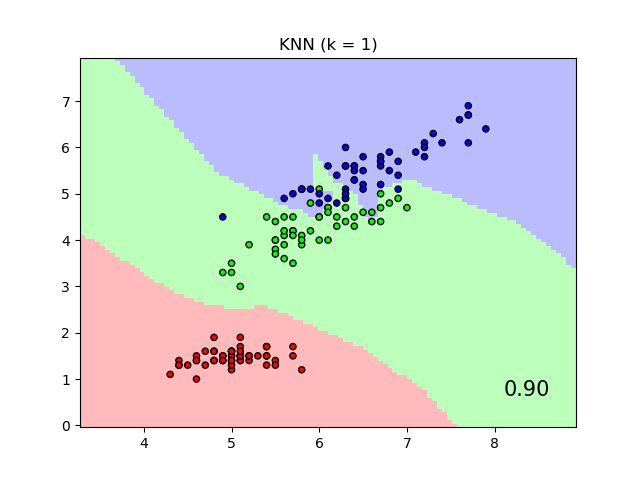
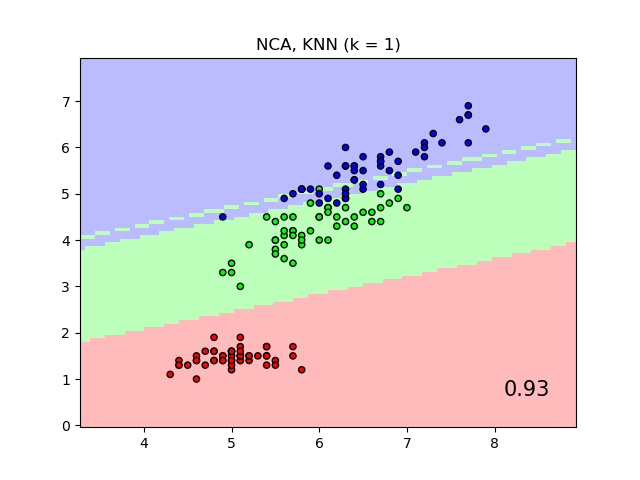
该图显示了鸢尾花数据集上最近邻分类和邻域成分分析分类的决策边界,为了可视化目的,仅使用两个特征进行训练和评分。
1.6.7.2. 降维#
NCA 可用于执行有监督降维。输入数据被投影到一个线性子空间,该子空间由使 NCA 目标函数最小化的方向组成。所需的维度可以通过参数 n_components 设置。例如,下图显示了在 Digits 数据集上,主成分分析(PCA)、线性判别分析(LinearDiscriminantAnalysis)和邻域成分分析(NeighborhoodComponentsAnalysis)降维的比较,该数据集的大小为 \(n_{samples} = 1797\) 和 \(n_{features} = 64\)。数据集被分成大小相等的训练集和测试集,然后进行标准化。为了评估,在每种方法找到的 2 维投影点上计算 3-最近邻分类准确度。每个数据样本属于 10 个类别中的一个。
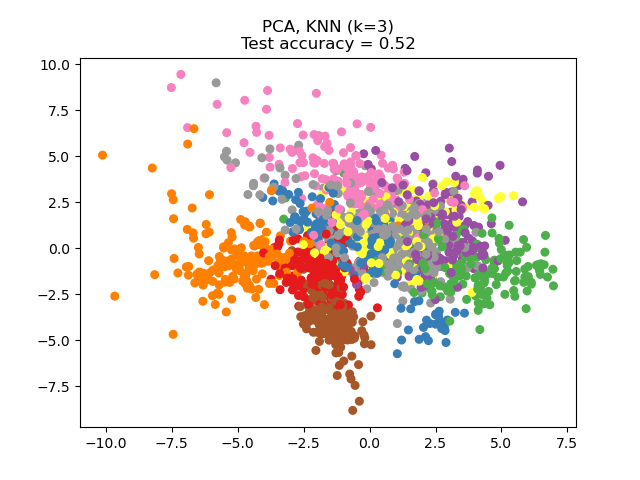
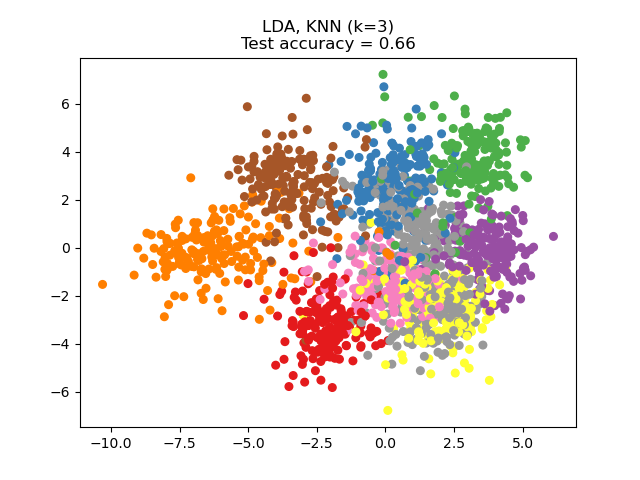
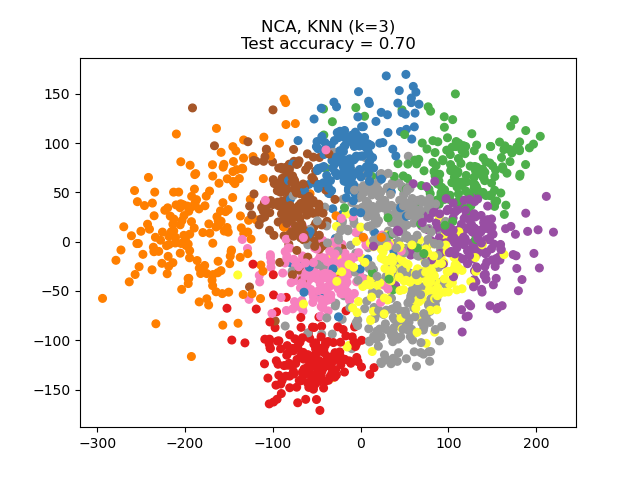
示例
1.6.7.3. 数学公式#
NCA 的目标是学习一个大小为 (n_components, n_features) 的最优线性变换矩阵,该矩阵使所有样本 \(i\) 被正确分类的概率 \(p_i\) 的总和最大化,即
其中 \(N\) = n_samples,\(p_i\) 是样本 \(i\) 在学习到的嵌入空间中根据随机最近邻规则正确分类的概率
其中 \(C_i\) 是与样本 \(i\) 属于同一类别的点集,\(p_{i j}\) 是嵌入空间中欧几里得距离的 softmax 函数
马氏距离#
NCA 可以看作是学习一个(平方)马氏距离度量
其中 \(M = L^T L\) 是一个大小为 (n_features, n_features) 的对称半正定矩阵。
1.6.7.4. 实现#
此实现遵循原始论文 [1] 中所述的内容。对于优化方法,它目前使用 scipy 的 L-BFGS-B,每次迭代都进行完全梯度计算,以避免调整学习率并提供稳定的学习。
有关更多信息,请参阅下面的示例和 NeighborhoodComponentsAnalysis.fit 的文档字符串。
1.6.7.5. 复杂性#
1.6.7.5.1. 训练#
NCA 存储一个成对距离矩阵,占用 n_samples ** 2 内存。时间复杂度取决于优化算法的迭代次数。然而,可以使用参数 max_iter 设置最大迭代次数。对于每次迭代,时间复杂度为 O(n_components x n_samples x min(n_samples, n_features))。
1.6.7.5.2. 转换#
此处 transform 操作返回 \(LX^T\),因此其时间复杂度等于 n_components * n_features * n_samples_test。该操作没有额外的空间复杂度。
参考文献