1.3. 核岭回归#
核岭回归 (KRR) [M2012] 将岭回归和分类(带有 \(L_2\)-范数正则化的线性最小二乘)与核技巧相结合。因此,它在由相应核和数据诱导的空间中学习一个线性函数。对于非线性核,这对应于原始空间中的非线性函数。
由KernelRidge学习的模型形式与支持向量回归 (SVR) 相同。然而,它们使用不同的损失函数:KRR 使用平方误差损失,而支持向量回归使用 \(\epsilon\)-不敏感损失,两者都结合了 \(L_2\) 正则化。与 SVR 不同,KernelRidge 的拟合可以通过闭式解完成,对于中等规模的数据集通常更快。另一方面,学习到的模型是非稀疏的,因此在预测时比 SVR 慢,后者对于 \(\epsilon > 0\) 学习的是稀疏模型。
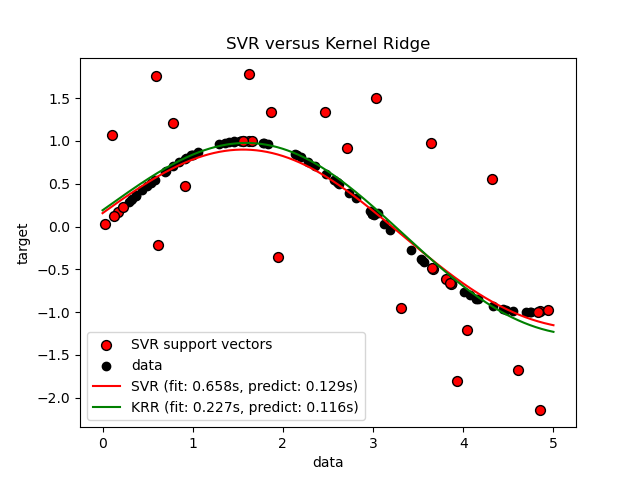
下图比较了 KernelRidge 和 SVR 在一个人工数据集上的表现,该数据集包含一个正弦目标函数,并且每第五个数据点都添加了强噪声。图中绘制了 KernelRidge 和 SVR 学习到的模型,其中两者都通过网格搜索优化了 RBF 核的复杂性/正则化和带宽。学习到的函数非常相似;然而,拟合 KernelRidge 大约比拟合 SVR 快七倍(两者都使用了网格搜索)。但是,预测 100,000 个目标值时,SVR 快三倍多,因为它学习了一个稀疏模型,仅使用了 100 个训练数据点中约 1/3 作为支持向量。
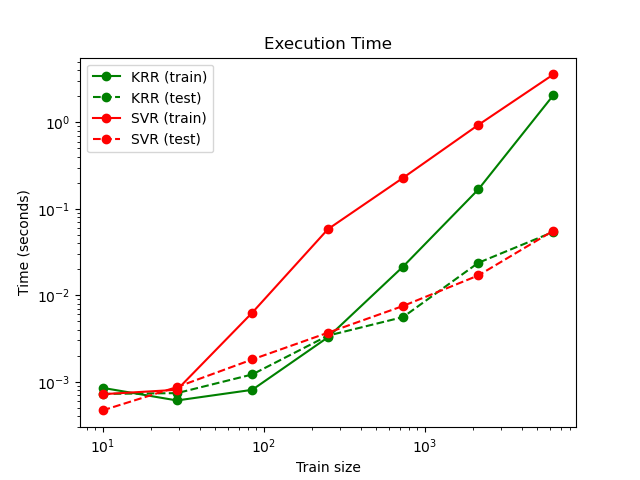
下图比较了 KernelRidge 和 SVR 在不同训练集大小下的拟合时间和预测时间。对于中等大小的训练集(少于 1000 个样本),拟合 KernelRidge 比 SVR 快;然而,对于更大的训练集,SVR 的扩展性更好。在预测时间方面,由于学习到了稀疏解,SVR 对于所有大小的训练集都比 KernelRidge 快。请注意,稀疏程度以及因此的预测时间取决于 SVR 的参数 \(\epsilon\) 和 \(C\);\(\epsilon = 0\) 将对应于一个密集模型。
示例
参考文献
“Machine Learning: A Probabilistic Perspective” Murphy, K. P. - 第 14.4.3 章, 第 492-493 页, 麻省理工学院出版社, 2012