5.1. 部分依赖图和个体条件期望图#
部分依赖图 (Partial dependence plots, PDP) 和个体条件期望 (Individual conditional expectation, ICE) 图可用于可视化和分析目标响应 [1] 与一组感兴趣的输入特征之间的交互作用。
PDP [H2009] 和 ICE [G2015] 都假设感兴趣的输入特征与其余特征是独立的,但这个假设在实践中经常被违反。因此,在特征相关的情况下,我们将创建荒谬的数据点来计算 PDP/ICE [M2019]。
5.1.1. 部分依赖图#
部分依赖图 (PDP) 显示了目标响应与一组感兴趣的输入特征之间的依赖关系,它通过对所有其他输入特征(“互补”特征)的值进行边缘化来计算。直观地讲,我们可以将部分依赖解释为目标响应作为感兴趣输入特征的函数的期望值。
由于人类感知的限制,感兴趣的输入特征集的规模必须很小(通常为一到两个),因此感兴趣的输入特征通常是从最重要的特征中选出的。
下图显示了自行车共享数据集的两个一维部分依赖图和一个二维部分依赖图,使用了 HistGradientBoostingRegressor
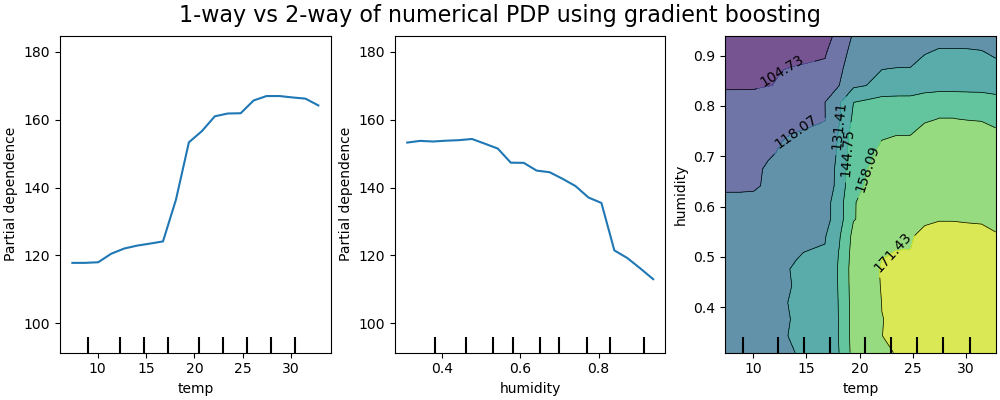
一维 PDP 告诉我们目标响应与感兴趣输入特征之间的交互作用(例如,线性、非线性)。上图中的左图显示了温度对自行车租赁数量的影响;我们可以清楚地看到,温度越高与自行车租赁数量越多相关。同样,我们可以分析湿度对自行车租赁数量的影响(中图)。因此,这些解释是边缘化的,一次只考虑一个特征。
具有两个感兴趣输入特征的 PDP 显示了这两个特征之间的交互作用。例如,上图中的双变量 PDP 显示了自行车租赁数量对温度和湿度联合值的依赖性。我们可以清楚地看到这两个特征之间的交互作用:当温度高于 20 摄氏度时,主要是湿度对自行车租赁数量有强烈影响。对于较低的温度,温度和湿度都对自行车租赁数量有影响。
sklearn.inspection 模块提供了一个便利函数 from_estimator 来创建一维和二维部分依赖图。在下面的示例中,我们展示了如何创建部分依赖图网格:特征 0 和 1 的两个一维 PDP 以及这两个特征之间的二维 PDP。
>>> from sklearn.datasets import make_hastie_10_2
>>> from sklearn.ensemble import GradientBoostingClassifier
>>> from sklearn.inspection import PartialDependenceDisplay
>>> X, y = make_hastie_10_2(random_state=0)
>>> clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0,
... max_depth=1, random_state=0).fit(X, y)
>>> features = [0, 1, (0, 1)]
>>> PartialDependenceDisplay.from_estimator(clf, X, features)
<...>
您可以使用 plt.gcf() 和 plt.gca() 访问新创建的图和 Axes 对象。
要使用分类特征制作部分依赖图,您需要使用参数 categorical_features 指定哪些特征是分类的。此参数接受分类特征的索引列表、名称列表或布尔掩码。分类特征的部分依赖的图形表示是条形图或二维热力图。
用于多类别分类的 PDPs#
对于多类别分类,您需要通过 target 参数设置应为其创建 PDP 的类别标签
>>> from sklearn.datasets import load_iris
>>> iris = load_iris()
>>> mc_clf = GradientBoostingClassifier(n_estimators=10,
... max_depth=1).fit(iris.data, iris.target)
>>> features = [3, 2, (3, 2)]
>>> PartialDependenceDisplay.from_estimator(mc_clf, X, features, target=0)
<...>
在多输出回归设置中,也使用相同的参数 target 来指定目标。
如果您需要部分依赖函数的原始值而不是图表,可以使用 sklearn.inspection.partial_dependence 函数
>>> from sklearn.inspection import partial_dependence
>>> results = partial_dependence(clf, X, [0])
>>> results["average"]
array([[ 2.466..., 2.466..., ...
>>> results["grid_values"]
[array([-1.624..., -1.592..., ...
部分依赖应在其中评估的值是直接从 X 生成的。对于二维部分依赖,会生成一个二维值的网格。 sklearn.inspection.partial_dependence 返回的 values 字段给出了用于网格中每个感兴趣输入特征的实际值。它们也对应于图表的轴。
5.1.2. 个体条件期望 (ICE) 图#
与 PDP 类似,个体条件期望 (ICE) 图显示了目标函数与感兴趣输入特征之间的依赖关系。然而,与 PDP 显示输入特征的平均效应不同,ICE 图通过每样本一条线分别可视化预测对特征的依赖性。由于人类感知的限制,ICE 图只支持一个感兴趣的输入特征。
下图显示了自行车共享数据集的两个 ICE 图,使用了 HistGradientBoostingRegressor。这些图表将相应的 PD 线叠加在 ICE 线上。
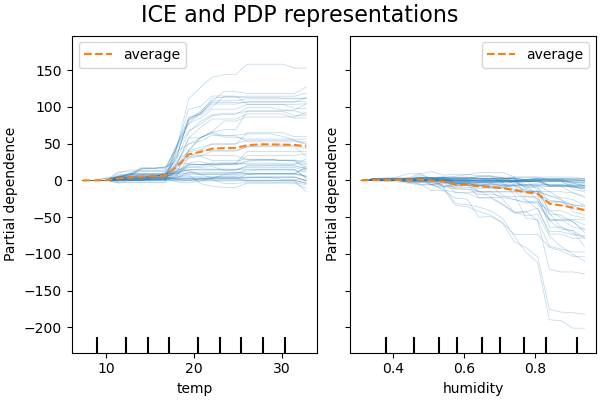
虽然 PDP 擅长显示目标特征的平均效应,但它们可能会掩盖由交互作用产生的异构关系。当存在交互作用时,ICE 图将提供更多见解。例如,我们看到温度特征的 ICE 给了我们一些额外的信息:一些 ICE 线是平坦的,而另一些则显示温度高于 35 摄氏度时依赖性有所下降。我们观察到湿度特征也有类似的模式:一些 ICE 线显示当湿度高于 80% 时急剧下降。
sklearn.inspection 模块的 PartialDependenceDisplay.from_estimator 便利函数可以通过设置 kind='individual' 来创建 ICE 图。在下面的示例中,我们展示了如何创建 ICE 图网格
>>> from sklearn.datasets import make_hastie_10_2
>>> from sklearn.ensemble import GradientBoostingClassifier
>>> from sklearn.inspection import PartialDependenceDisplay
>>> X, y = make_hastie_10_2(random_state=0)
>>> clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0,
... max_depth=1, random_state=0).fit(X, y)
>>> features = [0, 1]
>>> PartialDependenceDisplay.from_estimator(clf, X, features,
... kind='individual')
<...>
在 ICE 图中,可能不容易看到感兴趣输入特征的平均效应。因此,建议将 ICE 图与 PDP 一起使用。它们可以通过 kind='both' 一起绘制。
>>> PartialDependenceDisplay.from_estimator(clf, X, features,
... kind='both')
<...>
如果 ICE 图中有太多线条,可能难以看清单个样本之间的差异并解释模型。将 ICE 在 x 轴上的第一个值处居中,会生成居中个体条件期望 (cICE) 图 [G2015]。这强调了单个条件期望与平均线的偏差,从而使探索异构关系更加容易。cICE 图可以通过设置 centered=True 绘制。
>>> PartialDependenceDisplay.from_estimator(clf, X, features,
... kind='both', centered=True)
<...>
5.1.3. 数学定义#
设 \(X_S\) 为感兴趣的输入特征集(即 features 参数),设 \(X_C\) 为其补集。
响应 \(f\) 在点 \(x_S\) 处的部分依赖定义为
其中 \(f(x_S, x_C)\) 是对于给定样本的响应函数(predict、predict_proba 或 decision_function),其值由 \(x_S\) 定义为 \(X_S\) 中的特征,由 \(x_C\) 定义为 \(X_C\) 中的特征。请注意,\(x_S\) 和 \(x_C\) 可以是元组。
计算 \(x_S\) 的不同值时得到的积分会生成如上所述的 PDP 图。ICE 线定义为在 \(x_{S}\) 处评估的单个 \(f(x_{S}, x_{C}^{(i)})\)。
5.1.4. 计算方法#
有两种主要方法来近似上述积分,即 'brute' 和 'recursion' 方法。 method 参数控制使用哪种方法。
'brute' 方法是一种通用方法,适用于任何估计器。请注意,计算 ICE 图仅支持 'brute' 方法。它通过计算数据 X 上的平均值来近似上述积分
其中 \(x_C^{(i)}\) 是第 i 个样本在 \(X_C\) 中特征的值。对于 \(x_S\) 的每个值,此方法需要对数据集 X 进行一次完整的遍历,这在计算上是密集型的。
每个 \(f(x_{S}, x_{C}^{(i)})\) 对应于在 \(x_{S}\) 处评估的一条 ICE 线。计算 \(x_{S}\) 的多个值时,可以获得一条完整的 ICE 线。正如所见,ICE 线的平均值对应于部分依赖线。
'recursion' 方法比 'brute' 方法快,但它仅支持某些基于树的估计器的 PDP 图。它的计算方式如下。对于给定的点 \(x_S\),执行加权树遍历:如果拆分节点涉及感兴趣的输入特征,则遵循相应的左分支或右分支;否则,两个分支都遵循,每个分支都按进入该分支的训练样本比例加权。最后,部分依赖由所有访问叶子值的加权平均值给出。
使用 'brute' 方法时,参数 X 用于生成值 \(x_S\) 的网格和互补特征值 \(x_C\)。然而,使用 'recursion' 方法时,X 仅用于网格值:隐式地,\(x_C\) 值是训练数据的值。
默认情况下,对于支持它的基于树的估计器,使用 'recursion' 方法绘制 PDP,对于其余的则使用 'brute' 方法。
注意
虽然两种方法在一般情况下应该接近,但在某些特定设置中它们可能会有所不同。 'brute' 方法假设存在数据点 \((x_S, x_C^{(i)})\)。当特征相关时,此类人工样本的概率质量可能非常低。 'brute' 和 'recursion' 方法在部分依赖值方面可能会有所不同,因为它们将以不同方式处理这些不太可能的样本。然而,请记住,解释 PDP 的首要假设是特征应该是独立的。
示例
脚注
References
T. Hastie, R. Tibshirani and J. Friedman, The Elements of Statistical Learning, Second Edition, Section 10.13.2, Springer, 2009.
C. Molnar, Interpretable Machine Learning, Section 5.1, 2019.