3.2. 调整估计器的超参数#
超参数是估计器内部不会直接学习的参数。在 scikit-learn 中,它们作为参数传递给估计器类的构造函数。典型的例子包括支持向量分类器(Support Vector Classifier)的 C、kernel 和 gamma,Lasso 的 alpha 等。
搜索超参数空间以获得最佳交叉验证得分是可能且推荐的做法。
在构建估计器时提供的任何参数都可以通过这种方式进行优化。具体来说,要查找给定估计器的所有参数名称和当前值,请使用
estimator.get_params()
一次搜索包括:
一个估计器(回归器或分类器,例如
sklearn.svm.SVC());一个参数空间;
一种搜索或采样候选者的方法;
一个交叉验证方案;以及
一个得分函数。
scikit-learn 中提供了两种通用的参数搜索方法:对于给定值,GridSearchCV 详尽地考虑所有参数组合,而 RandomizedSearchCV 可以从具有指定分布的参数空间中采样给定数量的候选者。这两种工具都有相应的逐次减半(successive halving)版本 HalvingGridSearchCV 和 HalvingRandomSearchCV,它们在寻找好的参数组合方面可能快得多。
在描述完这些工具之后,我们将详细介绍适用于这些方法的最佳实践。一些模型允许使用专门的高效参数搜索策略,如暴力参数搜索的替代方案中所述。
请注意,这些参数中的一小部分通常会对模型的预测或计算性能产生巨大影响,而其他参数可以保留其默认值。建议阅读估计器类的 docstring 以更深入地了解它们的预期行为,可能还需要阅读其中包含的参考文献。
3.2.1. 详尽网格搜索#
由 GridSearchCV 提供的网格搜索会从使用 param_grid 参数指定的参数值网格中详尽地生成候选者。例如,下面的 param_grid
param_grid = [
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
]
指定应探索两个网格:一个使用线性核(linear kernel),C 值在 [1, 10, 100, 1000] 中;第二个使用 RBF 核,C 值在 [1, 10, 100, 1000] 中,gamma 值在 [0.001, 0.0001] 中的笛卡尔积。
GridSearchCV 实例实现了通常的估计器 API:当在数据集上“拟合”(fitting)它时,所有可能的参数值组合都会被评估,并保留最佳组合。
示例
请参阅 嵌套与非嵌套交叉验证,了解在 iris 数据集上进行交叉验证循环中的网格搜索示例。这是评估具有网格搜索的模型的性能的最佳实践。
请参阅 文本特征提取和评估的示例管道,了解使用
Pipeline实例将文本文档特征提取器(n-gram 计数向量化器和 TF-IDF 转换器)的参数与分类器(此处为使用 SGD 训练的线性 SVM,带有 elastic net 或 L2 惩罚)耦合的网格搜索示例。
高级示例#
请参阅 嵌套与非嵌套交叉验证,了解在 iris 数据集上进行交叉验证循环中的网格搜索示例。这是评估具有网格搜索的模型的性能的最佳实践。
请参阅 cross_val_score 和 GridSearchCV 上的多指标评估演示,了解
GridSearchCV同时评估多个指标的示例。请参阅 平衡模型复杂度和交叉验证得分,了解在
GridSearchCV中使用refit=callable接口的示例。该示例展示了此接口如何在识别“最佳”估计器方面增加一定程度的灵活性。此接口也可以用于多指标评估。请参阅 使用网格搜索进行模型的统计比较,了解如何对
GridSearchCV的输出进行统计比较的示例。
3.2.2. 随机参数优化#
尽管使用参数设置网格是目前最广泛使用的参数优化方法,但其他搜索方法具有更有利的特性。RandomizedSearchCV 实现了参数的随机搜索,其中每个设置都是从可能的参数值分布中采样的。这相对于详尽搜索有两个主要好处:
可以选择一个与参数数量和可能值无关的预算。
添加不影响性能的参数不会降低效率。
指定参数应如何采样是使用字典完成的,这与为 GridSearchCV 指定参数非常相似。此外,使用 n_iter 参数指定计算预算,即采样的候选者数量或采样迭代次数。对于每个参数,可以指定可能的数值分布或离散选择列表(将统一采样):
{'C': scipy.stats.expon(scale=100), 'gamma': scipy.stats.expon(scale=.1),
'kernel': ['rbf'], 'class_weight':['balanced', None]}
此示例使用 scipy.stats 模块,其中包含许多用于采样参数的有用分布,例如 expon、gamma、uniform、loguniform 或 randint。
原则上,可以传递任何提供 rvs(随机变量样本)方法来采样值的函数。对 rvs 函数的调用应在连续调用中提供可能的参数值的独立随机样本。
警告
scipy 0.16 版本之前的 scipy.stats 中的分布不允许指定随机状态。相反,它们使用全局 numpy 随机状态,可以通过 np.random.seed 或使用 np.random.set_state 进行设置。但是,从 scikit-learn 0.18 开始,如果 scipy >= 0.16 也可用,sklearn.model_selection 模块会设置用户提供的随机状态。
对于连续参数(如上面的 C),指定连续分布以充分利用随机化非常重要。通过这种方式,增加 n_iter 将始终导致更精细的搜索。
连续对数均匀随机变量是按对数间隔的参数的连续版本。例如,要指定与上面 C 等效的值,可以使用 loguniform(1, 100) 而不是 [1, 10, 100]。
模仿上面网格搜索中的示例,我们可以指定一个在 1e0 和 1e3 之间对数均匀分布的连续随机变量:
from sklearn.utils.fixes import loguniform
{'C': loguniform(1e0, 1e3),
'gamma': loguniform(1e-4, 1e-3),
'kernel': ['rbf'],
'class_weight':['balanced', None]}
示例
比较超参数估计中的随机搜索和网格搜索 比较了随机搜索和网格搜索的用法和效率。
References
Bergstra, J. and Bengio, Y., Random search for hyper-parameter optimization, The Journal of Machine Learning Research (2012)
3.2.3. 使用逐次减半搜索最佳参数#
Scikit-learn 还提供了 HalvingGridSearchCV 和 HalvingRandomSearchCV 估计器,可用于使用逐次减半(successive halving)[1] [2] 搜索参数空间。逐次减半(SH)就像候选参数组合之间的锦标赛。SH 是一个迭代选择过程,所有候选者(参数组合)在第一次迭代中以少量资源进行评估。只有其中一些候选者被选中进入下一次迭代,并分配更多的资源。对于参数调整,资源通常是训练样本的数量,但它也可以是任意数值参数,例如随机森林中的 n_estimators。
注意
选择的资源增量应该足够大,以便在考虑到统计显著性的情况下,得分能有很大的提高。
如下图所示,只有一部分候选者“幸存”到最后一次迭代。这些是在所有迭代中持续排名前列的候选者。每次迭代为每个候选者分配的资源量都会增加,这里是样本数量。
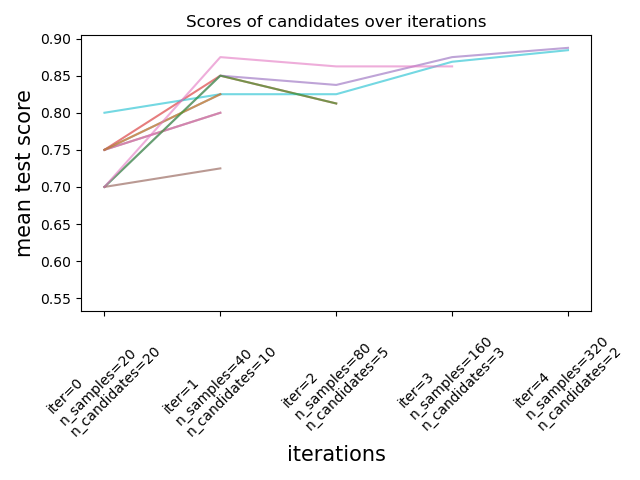
我们在这里简要描述主要参数,但在下面的下拉部分中会更详细地描述每个参数及其相互作用。factor (> 1) 参数控制资源增长的速度和候选者数量减少的速度。在每次迭代中,每个候选者的资源数量乘以 factor,候选者数量除以相同的因子。与 resource 和 min_resources 一起,factor 是控制我们实现中搜索的最重要参数,尽管值 3 通常效果很好。factor 有效地控制 HalvingGridSearchCV 中的迭代次数以及 HalvingRandomSearchCV 中的候选者数量(默认情况下)和迭代次数。aggressive_elimination=True 也可以在可用资源数量较少时使用。通过调整 min_resources 参数可以获得更多控制。
这些估计器仍然是 实验性的:它们的预测和 API 可能会在没有任何弃用周期的情况下发生变化。要使用它们,您需要显式导入 enable_halving_search_cv
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> from sklearn.model_selection import HalvingRandomSearchCV
示例
下面的部分将深入探讨逐次减半的技术方面。
选择 min_resources 和候选者数量#
除了 factor 之外,影响逐次减半搜索行为的两个主要参数是 min_resources 参数和被评估的候选者(或参数组合)的数量。min_resources 是在第一次迭代中为每个候选者分配的资源量。候选者数量在 HalvingRandomSearchCV 中直接指定,并由 HalvingGridSearchCV 的 param_grid 参数确定。
考虑一个资源是样本数量,并且我们有 1000 个样本的情况。理论上,使用 min_resources=10 和 factor=2,我们最多能够运行 7 次迭代,样本数量如下:[10, 20, 40, 80, 160, 320, 640]。
但是根据候选者的数量,我们可能运行少于 7 次迭代:如果我们从 少量 候选者开始,最后一次迭代可能使用少于 640 个样本,这意味着没有使用所有可用资源(样本)。例如,如果我们从 5 个候选者开始,我们只需要 2 次迭代:第一次迭代有 5 个候选者,然后第二次迭代有 5 // 2 = 2 个候选者,之后我们知道哪个候选者表现最好(所以我们不需要第三次迭代)。我们最多只使用 20 个样本,这是一种浪费,因为我们有 1000 个样本可供使用。另一方面,如果我们从 大量 候选者开始,最后一次迭代可能有很多候选者,这可能并不总是理想的:这意味着许多候选者将使用全部资源运行,基本上将过程简化为标准搜索。
在 HalvingRandomSearchCV 的情况下,默认设置候选者数量,使得最后一次迭代使用尽可能多的可用资源。对于 HalvingGridSearchCV,候选者数量由 param_grid 参数确定。更改 min_resources 的值将影响可能的迭代次数,因此也会影响理想的候选者数量。
选择 min_resources 时的另一个考虑因素是,使用少量资源是否容易区分好候选者和坏候选者。例如,如果您需要大量样本来区分好参数和坏参数,建议使用较高的 min_resources。另一方面,如果即使使用少量样本也能清楚区分,那么较低的 min_resources 可能更可取,因为它可以加快计算速度。
请注意,在上面的示例中,最后一次迭代没有使用最大可用资源:有 1000 个样本可用,但最多只使用了 640 个。默认情况下,HalvingRandomSearchCV 和 HalvingGridSearchCV 都尝试在最后一次迭代中使用尽可能多的资源,约束条件是此资源量必须是 min_resources 和 factor 的倍数(此约束将在下一节中阐明)。HalvingRandomSearchCV 通过采样适当数量的候选者来实现这一点,而 HalvingGridSearchCV 通过正确设置 min_resources 来实现。
每次迭代的资源量和候选者数量#
在任何迭代 i 中,每个候选者都被分配了一定量的资源,我们将其表示为 n_resources_i。这个数量由参数 factor 和 min_resources 控制如下(factor 严格大于 1):
n_resources_i = factor**i * min_resources,
或等效地:
n_resources_{i+1} = n_resources_i * factor
其中 min_resources == n_resources_0 是第一次迭代中使用的资源量。factor 还定义了将为下一次迭代选择的候选者的比例:
n_candidates_i = n_candidates // (factor ** i)
或等效地:
n_candidates_0 = n_candidates
n_candidates_{i+1} = n_candidates_i // factor
因此在第一次迭代中,我们使用 min_resources 资源 n_candidates 次。在第二次迭代中,我们使用 min_resources * factor 资源 n_candidates // factor 次。第三次迭代再次乘以每个候选者的资源并除以候选者的数量。这个过程在达到每个候选者的最大资源量,或者当我们确定了最佳候选者时停止。最佳候选者是在评估 factor 或更少候选者的迭代中确定的(请参阅下文的解释)。
这是一个示例,其中 min_resources=3 和 factor=2,从 70 个候选者开始:
|
|
|---|---|
3 (=min_resources) |
70 (=n_candidates) |
3 * 2 = 6 |
70 // 2 = 35 |
6 * 2 = 12 |
35 // 2 = 17 |
12 * 2 = 24 |
17 // 2 = 8 |
24 * 2 = 48 |
8 // 2 = 4 |
48 * 2 = 96 |
4 // 2 = 2 |
我们可以注意到:
该过程在评估
factor=2个候选者的第一次迭代时停止:最佳候选者是这 2 个候选者中最好的。没有必要运行额外的迭代,因为它只会评估一个候选者(即我们已经确定的最佳候选者)。因此,通常我们希望最后一次迭代最多运行factor个候选者。如果最后一次迭代评估超过factor个候选者,则这最后一次迭代会简化为常规搜索(如RandomizedSearchCV或GridSearchCV)。每个
n_resources_i都是factor和min_resources的倍数(这由上面的定义证实)。
每次迭代中使用的资源量可以在 n_resources_ 属性中找到。
选择资源#
默认情况下,资源是根据样本数量定义的。也就是说,每次迭代将使用越来越多的样本进行训练。但是,您可以使用 resource 参数手动指定要用作资源的参数。这是一个示例,其中资源是根据随机森林的估计器数量定义的:
>>> from sklearn.datasets import make_classification
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>> param_grid = {'max_depth': [3, 5, 10],
... 'min_samples_split': [2, 5, 10]}
>>> base_estimator = RandomForestClassifier(random_state=0)
>>> X, y = make_classification(n_samples=1000, random_state=0)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, resource='n_estimators',
... max_resources=30).fit(X, y)
>>> sh.best_estimator_
RandomForestClassifier(max_depth=5, n_estimators=24, random_state=0)
请注意,不能对作为参数网格一部分的参数进行预算。
耗尽可用资源#
如上所述,每次迭代中使用的资源数量取决于 min_resources 参数。如果您有大量可用资源但从低资源数量开始,其中一些资源可能会被浪费(即未使用):
>>> from sklearn.datasets import make_classification
>>> from sklearn.svm import SVC
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>> param_grid= {'kernel': ('linear', 'rbf'),
... 'C': [1, 10, 100]}
>>> base_estimator = SVC(gamma='scale')
>>> X, y = make_classification(n_samples=1000)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, min_resources=20).fit(X, y)
>>> sh.n_resources_
[20, 40, 80]
搜索过程最多只使用 80 个资源,而我们可用的最大资源量是 n_samples=1000。在这里,我们有 min_resources = r_0 = 20。
对于 HalvingGridSearchCV,默认情况下,min_resources 参数设置为“exhaust”。这意味着 min_resources 会自动设置,以便最后一次迭代可以在 max_resources 限制内使用尽可能多的资源:
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, min_resources='exhaust').fit(X, y)
>>> sh.n_resources_
[250, 500, 1000]
min_resources 在这里自动设置为 250,这导致最后一次迭代使用了所有资源。使用的确切值取决于候选参数的数量、max_resources 和 factor。
对于 HalvingRandomSearchCV,耗尽资源可以通过 2 种方式完成:
通过设置
min_resources='exhaust',就像对于HalvingGridSearchCV一样;通过设置
n_candidates='exhaust'。
这两个选项是互斥的:使用 min_resources='exhaust' 需要知道候选者数量,对称地,n_candidates='exhaust' 需要知道 min_resources。
通常,耗尽总资源会导致更好的最终候选参数,并且耗时稍长。
3.2.3.1. 激进的候选者淘汰#
使用 aggressive_elimination 参数,您可以强制搜索过程在最后一次迭代中以少于 factor 个候选者结束。
激进淘汰的代码示例#
理想情况下,我们希望最后一次迭代评估 factor 个候选者。然后我们只需选出最好的一个。当可用资源数量相对于候选者数量较少时,最后一次迭代可能必须评估超过 factor 个候选者:
>>> from sklearn.datasets import make_classification
>>> from sklearn.svm import SVC
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>> param_grid = {'kernel': ('linear', 'rbf'),
... 'C': [1, 10, 100]}
>>> base_estimator = SVC(gamma='scale')
>>> X, y = make_classification(n_samples=1000)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, max_resources=40,
... aggressive_elimination=False).fit(X, y)
>>> sh.n_resources_
[20, 40]
>>> sh.n_candidates_
[6, 3]
由于我们不能使用超过 max_resources=40 的资源,因此过程必须在第二次迭代时停止,而这次迭代评估了超过 factor=2 个候选者。
使用 aggressive_elimination 时,过程将使用 min_resources 资源淘汰必要的候选者:
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2,
... max_resources=40,
... aggressive_elimination=True,
... ).fit(X, y)
>>> sh.n_resources_
[20, 20, 40]
>>> sh.n_candidates_
[6, 3, 2]
请注意,我们在最后一次迭代中以 2 个候选者结束,因为我们在第一次迭代中使用了 n_resources = min_resources = 20 淘汰了足够的候选者。
3.2.3.2. 使用 cv_results_ 属性分析结果#
cv_results_ 属性包含用于分析搜索结果的有用信息。可以使用 df = pd.DataFrame(est.cv_results_) 将其转换为 pandas dataframe。HalvingGridSearchCV 和 HalvingRandomSearchCV 的 cv_results_ 属性与 GridSearchCV 和 RandomizedSearchCV 的相似,并包含与逐次减半过程相关的额外信息。
(截断的)输出 dataframe 示例:#
iter |
n_resources |
mean_test_score |
params |
|
|---|---|---|---|---|
0 |
0 |
125 |
0.983667 |
{‘criterion’: ‘log_loss’, ‘max_depth’: None, ‘max_features’: 9, ‘min_samples_split’: 5} |
1 |
0 |
125 |
0.983667 |
{‘criterion’: ‘gini’, ‘max_depth’: None, ‘max_features’: 8, ‘min_samples_split’: 7} |
2 |
0 |
125 |
0.983667 |
{‘criterion’: ‘gini’, ‘max_depth’: None, ‘max_features’: 10, ‘min_samples_split’: 10} |
3 |
0 |
125 |
0.983667 |
{‘criterion’: ‘log_loss’, ‘max_depth’: None, ‘max_features’: 6, ‘min_samples_split’: 6} |
… |
… |
… |
… |
… |
15 |
2 |
500 |
0.951958 |
{‘criterion’: ‘log_loss’, ‘max_depth’: None, ‘max_features’: 9, ‘min_samples_split’: 10} |
16 |
2 |
500 |
0.947958 |
{‘criterion’: ‘gini’, ‘max_depth’: None, ‘max_features’: 10, ‘min_samples_split’: 10} |
17 |
2 |
500 |
0.951958 |
{‘criterion’: ‘gini’, ‘max_depth’: None, ‘max_features’: 10, ‘min_samples_split’: 4} |
18 |
3 |
1000 |
0.961009 |
{‘criterion’: ‘log_loss’, ‘max_depth’: None, ‘max_features’: 9, ‘min_samples_split’: 10} |
19 |
3 |
1000 |
0.955989 |
{‘criterion’: ‘gini’, ‘max_depth’: None, ‘max_features’: 10, ‘min_samples_split’: 4} |
每行对应一个给定的参数组合(一个候选者)和一个给定的迭代。迭代由 iter 列给出。n_resources 列告诉您使用了多少资源。
在上面的示例中,最佳参数组合是 {'criterion': 'log_loss', 'max_depth': None, 'max_features': 9, 'min_samples_split': 10},因为它以最高得分 0.96 达到了最后一次迭代 (3)。
References
3.2.4. 参数搜索技巧#
3.2.4.1. 指定目标指标#
默认情况下,参数搜索使用估计器的 score 函数来评估参数设置。对于分类,这是 sklearn.metrics.accuracy_score,对于回归,这是 sklearn.metrics.r2_score。对于某些应用,其他评分函数更合适(例如在不平衡分类中,准确率得分通常信息量不足),请参阅 我应该使用哪个评分函数? 以获取一些指导。可以通过大多数参数搜索工具的 scoring 参数指定替代评分函数,有关详细信息,请参阅 评分参数:定义模型评估规则。
3.2.4.2. 指定多个评估指标#
GridSearchCV 和 RandomizedSearchCV 允许为 scoring 参数指定多个指标。
多指标评分可以指定为预定义得分名称的字符串列表,也可以指定为将评分器名称映射到评分器函数和/或预定义评分器名称的字典。有关详细信息,请参阅 使用多指标评估。
当指定多个指标时,必须将 refit 参数设置为用于查找 best_params_ 并用于在整个数据集上构建 best_estimator_ 的指标(字符串)。如果搜索不应该重新拟合,请设置 refit=False。如果将 refit 保持为默认值 None,则在使用多个指标时会导致错误。
请参阅 cross_val_score 和 GridSearchCV 上的多指标评估演示 以获取示例用法。
HalvingRandomSearchCV 和 HalvingGridSearchCV 不支持多指标评分。
3.2.4.3. 复合估计器和参数空间#
GridSearchCV 和 RandomizedSearchCV 允许使用专用的 <estimator>__<parameter> 语法搜索复合或嵌套估计器(如 Pipeline、ColumnTransformer、VotingClassifier 或 CalibratedClassifierCV)的参数:
>>> from sklearn.model_selection import GridSearchCV
>>> from sklearn.calibration import CalibratedClassifierCV
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.datasets import make_moons
>>> X, y = make_moons()
>>> calibrated_forest = CalibratedClassifierCV(
... estimator=RandomForestClassifier(n_estimators=10))
>>> param_grid = {
... 'estimator__max_depth': [2, 4, 6, 8]}
>>> search = GridSearchCV(calibrated_forest, param_grid, cv=5)
>>> search.fit(X, y)
GridSearchCV(cv=5,
estimator=CalibratedClassifierCV(estimator=RandomForestClassifier(n_estimators=10)),
param_grid={'estimator__max_depth': [2, 4, 6, 8]})
在这里,<estimator> 是嵌套估计器的参数名称,在此例中为 estimator。如果元估计器是作为估计器集合构建的,如在 pipeline.Pipeline 中,则 <estimator> 指的是估计器的名称,请参阅 访问嵌套参数。实际上,可以有多个嵌套级别:
>>> from sklearn.pipeline import Pipeline
>>> from sklearn.feature_selection import SelectKBest
>>> pipe = Pipeline([
... ('select', SelectKBest()),
... ('model', calibrated_forest)])
>>> param_grid = {
... 'select__k': [1, 2],
... 'model__estimator__max_depth': [2, 4, 6, 8]}
>>> search = GridSearchCV(pipe, param_grid, cv=5).fit(X, y)
请参阅 Pipeline: 链式估计器 以在管道上执行参数搜索。
3.2.4.4. 模型选择:开发和评估#
通过评估各种参数设置进行模型选择可以被视为一种使用标记数据来“训练”网格参数的方式。
在评估生成的模型时,重要的是在网格搜索过程中未曾见过的保留样本上进行:建议将数据拆分为一个 开发集(用于馈送给 GridSearchCV 实例)和一个 评估集 以计算性能指标。
这可以通过使用 train_test_split 实用函数完成。
3.2.4.5. 并行化#
参数搜索工具独立地评估每个数据折叠上的每个参数组合。通过使用关键字 n_jobs=-1,可以并行运行计算。有关详细信息,请参阅函数签名,以及n_jobs 的术语表条目。
3.2.4.6. 对失败的鲁棒性#
某些参数设置可能导致无法 fit 一个或多个数据折叠。默认情况下,这些设置的得分将为 np.nan。可以通过设置 error_score="raise" 来引发异常(如果某个拟合失败),或者例如 error_score=0 来为失败的参数组合设置另一个值。
3.2.5. 暴力参数搜索的替代方案#
3.2.5.1. 模型特定的交叉验证#
一些模型可以针对某个参数的一系列值拟合数据,其效率几乎与针对该参数的单个值拟合估计器一样高。可以利用此功能执行更高效的交叉验证,用于此参数的模型选择。
最适合此策略的常见参数是编码正则化强度的参数。在这种情况下,我们说我们计算了估计器的 正则化路径。
以下是此类模型的列表:
|
具有沿正则化路径迭代拟合的 Elastic Net 模型。 |
|
交叉验证的最小角回归模型。 |
|
具有沿正则化路径迭代拟合的 Lasso 线性模型。 |
|
使用 LARS 算法的交叉验证 Lasso。 |
|
Logistic 回归 CV(又名 logit,MaxEnt)分类器。 |
|
具有内置交叉验证的多任务 L1/L2 ElasticNet。 |
|
使用 L1/L2 混合范数作为正则化项训练的多任务 Lasso 模型。 |
交叉验证的正交匹配追踪模型 (OMP)。 |
|
|
具有内置交叉验证的 Ridge 回归。 |
|
具有内置交叉验证的 Ridge 分类器。 |
3.2.5.2. 信息准则#
一些模型可以通过计算单个正则化路径(而不是在使用交叉验证时计算多个)来提供正则化参数最优估计的信息论闭式公式。
以下是受益于 Akaike 信息准则(AIC)或 Bayesian 信息准则(BIC)进行自动模型选择的模型列表:
|
使用 BIC 或 AIC 进行模型选择的 Lars 拟合 Lasso 模型。 |
3.2.5.3. 袋外估计#
当使用基于 bagging(即使用有放回抽样生成新训练集)的集成方法时,部分训练集保持未使用状态。对于集成中的每个分类器,训练集的不同部分被排除在外。
这部分被排除的部分可用于估计泛化误差,而无需依赖单独的验证集。这种估计是“免费的”,因为不需要额外的数据,并且可以用于模型选择。
目前在以下类中实现:
随机森林分类器。 |
|
随机森林回归器。 |
|
Extra-Trees 分类器。 |
|
|
Extra-Trees 回归器。 |
|
用于分类的梯度提升。 |
|
用于回归的梯度提升。 |