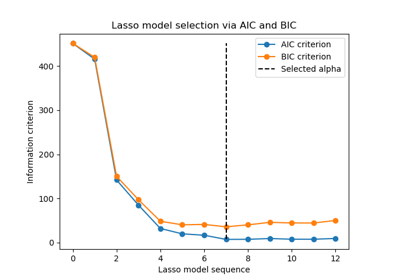
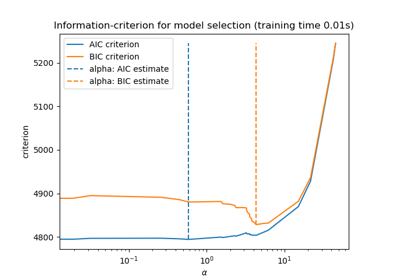
LassoLarsIC#
- class sklearn.linear_model.LassoLarsIC(criterion='aic', *, fit_intercept=True, verbose=False, precompute='auto', max_iter=500, eps=np.float64(2.220446049250313e-16), copy_X=True, positive=False, noise_variance=None)[source]#
使用 BIC 或 AIC 进行模型选择的 Lars 拟合 Lasso 模型。
The optimization objective for Lasso is
(1 / (2 * n_samples)) * ||y - Xw||^2_2 + alpha * ||w||_1
AIC is the Akaike information criterion [2] and BIC is the Bayes Information criterion [3]. Such criteria are useful to select the value of the regularization parameter by making a trade-off between the goodness of fit and the complexity of the model. A good model should explain well the data while being simple.
Read more in the User Guide.
- 参数:
- criterion{‘aic’, ‘bic’}, default=’aic’
The type of criterion to use.
- fit_interceptbool, default=True
Whether to calculate the intercept for this model. If set to false, no intercept will be used in calculations (i.e. data is expected to be centered).
- verbosebool or int, default=False
Sets the verbosity amount.
- precomputebool, ‘auto’ or array-like, default=’auto’
是否使用预计算的Gram矩阵来加快计算速度。如果设置为
'auto',则由我们决定。Gram矩阵也可以作为参数传入。- max_iterint, default=500
Maximum number of iterations to perform. Can be used for early stopping.
- epsfloat, default=np.finfo(float).eps
The machine-precision regularization in the computation of the Cholesky diagonal factors. Increase this for very ill-conditioned systems. Unlike the
tolparameter in some iterative optimization-based algorithms, this parameter does not control the tolerance of the optimization.- copy_Xbool, default=True
如果为 True,X 将被复制;否则,它可能会被覆盖。
- positivebool, default=False
Restrict coefficients to be >= 0. Be aware that you might want to remove fit_intercept which is set True by default. Under the positive restriction the model coefficients do not converge to the ordinary-least-squares solution for small values of alpha. Only coefficients up to the smallest alpha value (
alphas_[alphas_ > 0.].min()when fit_path=True) reached by the stepwise Lars-Lasso algorithm are typically in congruence with the solution of the coordinate descent Lasso estimator. As a consequence using LassoLarsIC only makes sense for problems where a sparse solution is expected and/or reached.- noise_variancefloat, default=None
The estimated noise variance of the data. If
None, an unbiased estimate is computed by an OLS model. However, it is only possible in the case wheren_samples > n_features + fit_intercept.版本 1.1 中新增。
- 属性:
- coef_array-like of shape (n_features,)
parameter vector (w in the formulation formula)
- intercept_float
independent term in decision function.
- alpha_float
the alpha parameter chosen by the information criterion
- alphas_array-like of shape (n_alphas + 1,) or list of such arrays
Maximum of covariances (in absolute value) at each iteration.
n_alphasis eithermax_iter,n_featuresor the number of nodes in the path withalpha >= alpha_min, whichever is smaller. If a list, it will be of lengthn_targets.- n_iter_int
number of iterations run by lars_path to find the grid of alphas.
- criterion_array-like of shape (n_alphas,)
The value of the information criteria (‘aic’, ‘bic’) across all alphas. The alpha which has the smallest information criterion is chosen, as specified in [1].
- noise_variance_float
The estimated noise variance from the data used to compute the criterion.
版本 1.1 中新增。
- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
另请参阅
lars_pathCompute Least Angle Regression or Lasso path using LARS algorithm.
lasso_path使用坐标下降计算 Lasso 路径。
Lasso使用 L1 先验作为正则化项训练的线性模型(又名 Lasso)。
LassoCV具有沿正则化路径迭代拟合的 Lasso 线性模型。
LassoLars使用最小角回归(又名 Lars)拟合的 Lasso 模型。
LassoLarsCV使用 LARS 算法的交叉验证 Lasso。
sklearn.decomposition.sparse_encode稀疏编码。
注意事项
The number of degrees of freedom is computed as in [1].
To have more details regarding the mathematical formulation of the AIC and BIC criteria, please refer to User Guide.
References
示例
>>> from sklearn import linear_model >>> reg = linear_model.LassoLarsIC(criterion='bic') >>> X = [[-2, 2], [-1, 1], [0, 0], [1, 1], [2, 2]] >>> y = [-2.2222, -1.1111, 0, -1.1111, -2.2222] >>> reg.fit(X, y) LassoLarsIC(criterion='bic') >>> print(reg.coef_) [ 0. -1.11]
For a detailed example of using this class, see Lasso model selection via information criteria.
- fit(X, y, copy_X=None)[source]#
Fit the model using X, y as training data.
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
训练数据。
- yarray-like of shape (n_samples,)
目标值。如有必要,将被转换为 X 的 dtype。
- copy_Xbool, default=None
If provided, this parameter will override the choice of copy_X made at instance creation. If
True, X will be copied; else, it may be overwritten.
- 返回:
- selfobject
Returns an instance of self.
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- predict(X)[source]#
使用线性模型进行预测。
- 参数:
- Xarray-like or sparse matrix, shape (n_samples, n_features)
样本。
- 返回:
- Carray, shape (n_samples,)
返回预测值。
- score(X, y, sample_weight=None)[source]#
返回测试数据的 决定系数。
The coefficient of determination, \(R^2\), is defined as \((1 - \frac{u}{v})\), where \(u\) is the residual sum of squares
((y_true - y_pred)** 2).sum()and \(v\) is the total sum of squares((y_true - y_true.mean()) ** 2).sum(). The best possible score is 1.0 and it can be negative (because the model can be arbitrarily worse). A constant model that always predicts the expected value ofy, disregarding the input features, would get a \(R^2\) score of 0.0.- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
测试样本。对于某些估计器,这可能是一个预先计算的核矩阵或一个通用对象列表,形状为
(n_samples, n_samples_fitted),其中n_samples_fitted是用于估计器拟合的样本数。- yshape 为 (n_samples,) 或 (n_samples, n_outputs) 的 array-like
X的真实值。- sample_weightshape 为 (n_samples,) 的 array-like, default=None
样本权重。
- 返回:
- scorefloat
self.predict(X)相对于y的 \(R^2\)。
注意事项
The \(R^2\) score used when calling
scoreon a regressor usesmultioutput='uniform_average'from version 0.23 to keep consistent with default value ofr2_score. This influences thescoremethod of all the multioutput regressors (except forMultiOutputRegressor).
- set_fit_request(*, copy_X: bool | None | str = '$UNCHANGED$') LassoLarsIC[source]#
配置是否应请求元数据以传递给
fit方法。请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True:请求元数据,如果提供则传递给fit。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给fit。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- copy_Xstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
copy_Xparameter infit.
- 返回:
- selfobject
更新后的对象。
- set_params(**params)[source]#
设置此估计器的参数。
此方法适用于简单的估计器以及嵌套对象(如
Pipeline)。后者具有<component>__<parameter>形式的参数,以便可以更新嵌套对象的每个组件。- 参数:
- **paramsdict
估计器参数。
- 返回:
- selfestimator instance
估计器实例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LassoLarsIC[source]#
配置是否应请求元数据以传递给
score方法。请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True:请求元数据,如果提供则传递给score。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给score。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
score方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。