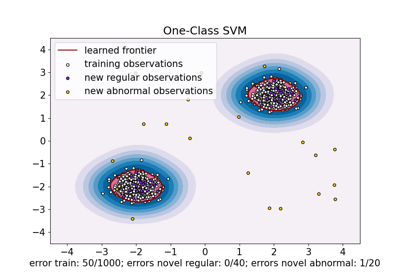
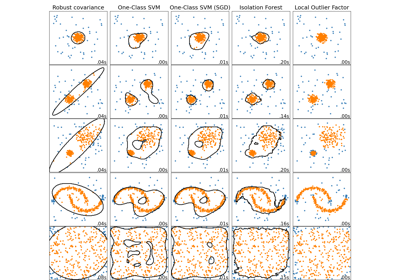
SGDOneClassSVM#
- class sklearn.linear_model.SGDOneClassSVM(nu=0.5, fit_intercept=True, max_iter=1000, tol=0.001, shuffle=True, verbose=0, random_state=None, learning_rate='optimal', eta0=0.01, power_t=0.5, warm_start=False, average=False)[source]#
使用随机梯度下降求解线性 One-Class SVM。
此实现旨在与核近似技术(例如
sklearn.kernel_approximation.Nystroem)一起使用,以获得类似于sklearn.svm.OneClassSVM的结果,后者默认使用高斯核。在用户指南中了解更多信息。
1.0 版本新增。
- 参数:
- nufloat, default=0.5
One Class SVM 的 nu 参数:训练误差分数的上限,以及支持向量分数的下限。应在区间 (0, 1] 内。默认值为 0.5。
- fit_interceptbool, default=True
是否估计截距。默认为 True。
- max_iterint, default=1000
对训练数据的最大遍历次数(也称为 epoch)。它只影响
fit方法的行为,而不影响partial_fit。默认为 1000。值必须在范围[1, inf)内。- tolfloat or None, default=1e-3
停止准则。如果它不是 None,则当 (loss > previous_loss - tol) 时,迭代将停止。默认为 1e-3。值必须在范围
[0.0, inf)内。- shufflebool, default=True
在每个 epoch 之后是否打乱训练数据。默认为 True。
- verboseint, default=0
详细程度。
- random_stateint, RandomState instance or None, default=None
用于打乱数据时使用的伪随机数生成器种子。如果为 int,则 random_state 是随机数生成器使用的种子;如果为 RandomState 实例,则 random_state 是随机数生成器;如果为 None,则随机数生成器是
np.random使用的 RandomState 实例。- learning_rate{‘constant’, ‘optimal’, ‘invscaling’, ‘adaptive’}, default=’optimal’
与
fit一起使用的学习率调度。(如果使用partial_fit,则必须直接控制学习率)。‘constant’:
eta = eta0‘optimal’:
eta = 1.0 / (alpha * (t + t0)),其中 t0 是由 Leon Bottou 提出的启发式方法选择的。‘invscaling’:
eta = eta0 / pow(t, power_t)‘adaptive’:eta = eta0,只要训练损失持续下降。每次 n_iter_no_change 个连续 epoch 未能使训练损失减少 tol,或者如果 early_stopping 为 True 时未能使验证分数增加 tol,则当前学习率除以 5。
- eta0float, default=0.01
‘constant’、‘invscaling’ 或 ‘adaptive’ 调度方案的初始学习率。默认值为 0.0,但请注意,默认学习率 ‘optimal’ 不使用 eta0。值必须在范围
(0.0, inf)内。- power_tfloat, default=0.5
The exponent for inverse scaling learning rate. Values must be in the range
[0.0, inf).Deprecated since version 1.8: Negative values for
power_tare deprecated in version 1.8 and will raise an error in 1.10. Use values in the range [0.0, inf) instead.- warm_startbool, default=False
When set to True, reuse the solution of the previous call to fit as initialization, otherwise, just erase the previous solution. See the Glossary.
Repeatedly calling fit or partial_fit when warm_start is True can result in a different solution than when calling fit a single time because of the way the data is shuffled. If a dynamic learning rate is used, the learning rate is adapted depending on the number of samples already seen. Calling
fitresets this counter, whilepartial_fitwill result in increasing the existing counter.- averagebool or int, default=False
设置为 True 时,计算平均 SGD 权重并将结果存储在
coef_属性中。如果设置为大于 1 的 int,则一旦看到的样本总数达到 average,就开始进行平均。因此average=10将在看到 10 个样本后开始平均。
- 属性:
- coef_ndarray of shape (1, n_features)
Weights assigned to the features.
- offset_ndarray of shape (1,)
用于从原始分数定义决策函数的偏移量。我们有以下关系:decision_function = score_samples - offset。
- n_iter_int
The actual number of iterations to reach the stopping criterion.
- t_int
Number of weight updates performed during training. Same as
(n_iter_ * n_samples + 1).- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
另请参阅
sklearn.svm.OneClassSVM无监督异常值检测。
注意事项
此估计器在训练样本数量上具有线性复杂度,因此比
sklearn.svm.OneClassSVM实现更适合具有大量训练样本(例如 > 10,000)的数据集。示例
>>> import numpy as np >>> from sklearn import linear_model >>> X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]]) >>> clf = linear_model.SGDOneClassSVM(random_state=42, tol=None) >>> clf.fit(X) SGDOneClassSVM(random_state=42, tol=None)
>>> print(clf.predict([[4, 4]])) [1]
- decision_function(X)[source]#
到分离超平面的有符号距离。
有符号距离对于内点为正,对于离群点为负。
- 参数:
- X{array-like, sparse matrix}, shape (n_samples, n_features)
测试数据。
- 返回:
- decarray-like, shape (n_samples,)
样本的决策函数值。
- densify()[source]#
Convert coefficient matrix to dense array format.
Converts the
coef_member (back) to a numpy.ndarray. This is the default format ofcoef_and is required for fitting, so calling this method is only required on models that have previously been sparsified; otherwise, it is a no-op.- 返回:
- self
拟合的估计器。
- fit(X, y=None, coef_init=None, offset_init=None, sample_weight=None)[source]#
使用随机梯度下降拟合线性 One-Class SVM。
这解决了 One-Class SVM 原始优化问题的等效优化问题,并返回一个权重向量 w 和一个偏移量 rho,使得决策函数由 <w, x> - rho 给出。
- 参数:
- X{array-like, sparse matrix}, shape (n_samples, n_features)
训练数据。
- y被忽略
未使用,按照惯例为保持 API 一致性而存在。
- coef_initarray, shape (n_classes, n_features)
The initial coefficients to warm-start the optimization.
- offset_initarray, shape (n_classes,)
用于热启动优化的初始偏移量。
- sample_weightarray-like, shape (n_samples,), optional
应用于单个样本的权重。如果未提供,则假定均匀权重。如果指定了 class_weight(通过构造函数传入),这些权重将与 class_weight 相乘。
- 返回:
- selfobject
Returns a fitted instance of self.
- fit_predict(X, y=None, **kwargs)[source]#
Perform fit on X and returns labels for X.
Returns -1 for outliers and 1 for inliers.
- 参数:
- Xshape 为 (n_samples, n_features) 的 {array-like, sparse matrix}
输入样本。
- y被忽略
未使用,按照惯例为保持 API 一致性而存在。
- **kwargsdict
要传递给
fit的参数。1.4 版本新增。
- 返回:
- yndarray of shape (n_samples,)
1 for inliers, -1 for outliers.
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- partial_fit(X, y=None, sample_weight=None)[source]#
使用随机梯度下降拟合线性 One-Class SVM。
- 参数:
- X{array-like, sparse matrix}, shape (n_samples, n_features)
训练数据的子集。
- y被忽略
未使用,按照惯例为保持 API 一致性而存在。
- sample_weightarray-like, shape (n_samples,), optional
Weights applied to individual samples. If not provided, uniform weights are assumed.
- 返回:
- selfobject
Returns a fitted instance of self.
- predict(X)[source]#
返回样本的标签(1 内点,-1 离群点)。
- 参数:
- X{array-like, sparse matrix}, shape (n_samples, n_features)
测试数据。
- 返回:
- yarray, shape (n_samples,)
样本的标签。
- score_samples(X)[source]#
样本的原始评分函数。
- 参数:
- X{array-like, sparse matrix}, shape (n_samples, n_features)
测试数据。
- 返回:
- score_samplesarray-like, shape (n_samples,)
样本的未偏移评分函数值。
- set_fit_request(*, coef_init: bool | None | str = '$UNCHANGED$', offset_init: bool | None | str = '$UNCHANGED$', sample_weight: bool | None | str = '$UNCHANGED$') SGDOneClassSVM[source]#
配置是否应请求元数据以传递给
fit方法。请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True:请求元数据,如果提供则传递给fit。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给fit。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- coef_initstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
coef_initparameter infit.- offset_initstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
fit中offset_init参数的元数据路由。- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
fit方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。
- set_params(**params)[source]#
设置此估计器的参数。
此方法适用于简单的估计器以及嵌套对象(如
Pipeline)。后者具有<component>__<parameter>形式的参数,以便可以更新嵌套对象的每个组件。- 参数:
- **paramsdict
估计器参数。
- 返回:
- selfestimator instance
估计器实例。
- set_partial_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SGDOneClassSVM[source]#
Configure whether metadata should be requested to be passed to the
partial_fitmethod.请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True: metadata is requested, and passed topartial_fitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it topartial_fit.None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inpartial_fit.
- 返回:
- selfobject
更新后的对象。
- sparsify()[source]#
Convert coefficient matrix to sparse format.
Converts the
coef_member to a scipy.sparse matrix, which for L1-regularized models can be much more memory- and storage-efficient than the usual numpy.ndarray representation.The
intercept_member is not converted.- 返回:
- self
拟合的估计器。
注意事项
For non-sparse models, i.e. when there are not many zeros in
coef_, this may actually increase memory usage, so use this method with care. A rule of thumb is that the number of zero elements, which can be computed with(coef_ == 0).sum(), must be more than 50% for this to provide significant benefits.After calling this method, further fitting with the partial_fit method (if any) will not work until you call densify.