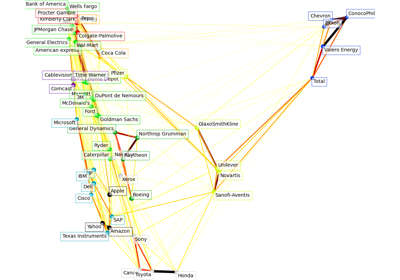
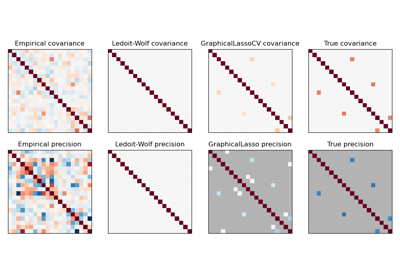
GraphicalLassoCV#
- class sklearn.covariance.GraphicalLassoCV(*, alphas=4, n_refinements=4, cv=None, tol=0.0001, enet_tol=0.0001, max_iter=100, mode='cd', n_jobs=None, verbose=False, eps=np.float64(2.220446049250313e-16), assume_centered=False)[source]#
稀疏逆协方差 w/ 交叉验证选择 l1 惩罚。
参见词汇表条目 交叉验证估计器。
Read more in the User Guide.
Changed in version v0.20: GraphLassoCV has been renamed to GraphicalLassoCV
- 参数:
- alphasint or array-like of shape (n_alphas,), dtype=float, default=4
If an integer is given, it fixes the number of points on the grids of alpha to be used. If a list is given, it gives the grid to be used. See the notes in the class docstring for more details. Range is [1, inf) for an integer. Range is (0, inf] for an array-like of floats.
- n_refinementsint, default=4
The number of times the grid is refined. Not used if explicit values of alphas are passed. Range is [1, inf).
- cvint, cross-validation generator or iterable, default=None
确定交叉验证拆分策略。cv 的可能输入包括
None,使用默认的 5 折交叉验证,
整数,指定折数。
一个可迭代对象,产生索引数组形式的 (训练集, 测试集) 拆分。
For integer/None inputs
KFoldis used.有关此处可使用的各种交叉验证策略,请参阅 用户指南。
Changed in version 0.20:
cvdefault value if None changed from 3-fold to 5-fold.- tolfloat, default=1e-4
The tolerance to declare convergence: if the dual gap goes below this value, iterations are stopped. Range is (0, inf].
- enet_tolfloat, default=1e-4
The tolerance for the elastic net solver used to calculate the descent direction. This parameter controls the accuracy of the search direction for a given column update, not of the overall parameter estimate. Only used for mode=’cd’. Range is (0, inf].
- max_iterint, default=100
最大迭代次数。
- mode{‘cd’, ‘lars’}, default=’cd’
The Lasso solver to use: coordinate descent or LARS. Use LARS for very sparse underlying graphs, where number of features is greater than number of samples. Elsewhere prefer cd which is more numerically stable.
- n_jobsint, default=None
并行运行的作业数。
None表示 1,除非在joblib.parallel_backend上下文中。-1表示使用所有处理器。有关更多详细信息,请参阅 Glossary。版本 v0.20 中已更改:
n_jobs默认值从 1 更改为 None- verbosebool, default=False
If verbose is True, the objective function and duality gap are printed at each iteration.
- epsfloat, default=eps
The machine-precision regularization in the computation of the Cholesky diagonal factors. Increase this for very ill-conditioned systems. Default is
np.finfo(np.float64).eps.在版本 1.3 中新增。
- assume_centeredbool, default=False
If True, data are not centered before computation. Useful when working with data whose mean is almost, but not exactly zero. If False, data are centered before computation.
- 属性:
- location_ndarray of shape (n_features,)
估计的位置,即估计的均值。
- covariance_ndarray of shape (n_features, n_features)
估计的协方差矩阵。
- precision_ndarray of shape (n_features, n_features)
Estimated precision matrix (inverse covariance).
- costs_list of (objective, dual_gap) pairs
The list of values of the objective function and the dual gap at each iteration. Returned only if return_costs is True.
在版本 1.3 中新增。
- alpha_float
Penalization parameter selected.
- cv_results_dict of ndarrays
A dict with keys
- alphasndarray of shape (n_alphas,)
All penalization parameters explored.
- split(k)_test_scorendarray of shape (n_alphas,)
Log-likelihood score on left-out data across (k)th fold.
1.0 版本新增。
- mean_test_scorendarray of shape (n_alphas,)
Mean of scores over the folds.
1.0 版本新增。
- std_test_scorendarray of shape (n_alphas,)
Standard deviation of scores over the folds.
1.0 版本新增。
- n_iter_int
Number of iterations run for the optimal alpha.
- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
另请参阅
graphical_lassoL1 惩罚协方差估算器。
GraphicalLasso使用 l1 惩罚估算器进行稀疏逆协方差估计。
注意事项
The search for the optimal penalization parameter (
alpha) is done on an iteratively refined grid: first the cross-validated scores on a grid are computed, then a new refined grid is centered around the maximum, and so on.One of the challenges which is faced here is that the solvers can fail to converge to a well-conditioned estimate. The corresponding values of
alphathen come out as missing values, but the optimum may be close to these missing values.In
fit, once the best parameteralphais found through cross-validation, the model is fit again using the entire training set.示例
>>> import numpy as np >>> from sklearn.covariance import GraphicalLassoCV >>> true_cov = np.array([[0.8, 0.0, 0.2, 0.0], ... [0.0, 0.4, 0.0, 0.0], ... [0.2, 0.0, 0.3, 0.1], ... [0.0, 0.0, 0.1, 0.7]]) >>> np.random.seed(0) >>> X = np.random.multivariate_normal(mean=[0, 0, 0, 0], ... cov=true_cov, ... size=200) >>> cov = GraphicalLassoCV().fit(X) >>> np.around(cov.covariance_, decimals=3) array([[0.816, 0.051, 0.22 , 0.017], [0.051, 0.364, 0.018, 0.036], [0.22 , 0.018, 0.322, 0.094], [0.017, 0.036, 0.094, 0.69 ]]) >>> np.around(cov.location_, decimals=3) array([0.073, 0.04 , 0.038, 0.143])
For an example comparing
sklearn.covariance.GraphicalLassoCV,sklearn.covariance.ledoit_wolfshrinkage and the empirical covariance on high-dimensional gaussian data, see Sparse inverse covariance estimation.- error_norm(comp_cov, norm='frobenius', scaling=True, squared=True)[source]#
计算两个协方差估计器之间的均方误差。
- 参数:
- comp_covarray-like of shape (n_features, n_features)
用于比较的协方差。
- norm{“frobenius”, “spectral”}, default=”frobenius”
用于计算误差的范数类型。可用的误差类型:- 'frobenius'(默认值):sqrt(tr(A^t.A)) - 'spectral':sqrt(max(eigenvalues(A^t.A)),其中 A 是误差
(comp_cov - self.covariance_)。- scalingbool, default=True
如果为 True(默认值),则将平方误差范数除以 n_features。如果为 False,则不重新缩放平方误差范数。
- squaredbool, default=True
是否计算平方误差范数或误差范数。如果为 True(默认值),则返回平方误差范数。如果为 False,则返回误差范数。
- 返回:
- resultfloat
self和comp_cov协方差估计器之间的均方误差(根据 Frobenius 范数)。
- fit(X, y=None, **params)[source]#
Fit the GraphicalLasso covariance model to X.
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
Data from which to compute the covariance estimate.
- y被忽略
未使用,按照惯例为保持 API 一致性而存在。
- **paramsdict, default=None
Parameters to be passed to the CV splitter and the cross_val_score function.
Added in version 1.5: Only available if
enable_metadata_routing=True, which can be set by usingsklearn.set_config(enable_metadata_routing=True). See Metadata Routing User Guide for more details.
- 返回:
- selfobject
返回实例本身。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
1.5 版本新增。
- 返回:
- routingMetadataRouter
封装路由信息的
MetadataRouter。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- get_precision()[source]#
获取精度矩阵。
- 返回:
- precision_array-like of shape (n_features, n_features)
与当前协方差对象关联的精度矩阵。
- mahalanobis(X)[source]#
计算给定观测值的平方马哈拉诺比斯距离。
有关离群值如何影响马哈拉诺比斯距离的详细示例,请参阅稳健协方差估计和马哈拉诺比斯距离相关性。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
观测值,我们计算其马哈拉诺比斯距离。假定观测值来自与用于拟合的数据相同的分布。
- 返回:
- distndarray of shape (n_samples,)
观测值的平方马哈拉诺比斯距离。
- score(X_test, y=None)[source]#
计算
X_test在估计的高斯模型下的对数似然。高斯模型由其均值和协方差矩阵定义,分别由
self.location_和self.covariance_表示。- 参数:
- X_testarray-like of shape (n_samples, n_features)
我们计算其似然的测试数据,其中
n_samples是样本数,n_features是特征数。X_test假定来自与用于拟合的数据相同的分布(包括中心化)。- y被忽略
未使用,按照惯例为保持 API 一致性而存在。
- 返回:
- resfloat
X_test的对数似然,其中self.location_和self.covariance_分别作为高斯模型均值和协方差矩阵的估计器。