IterativeImputer#
- class sklearn.impute.IterativeImputer(estimator=None, *, missing_values=nan, sample_posterior=False, max_iter=10, tol=0.001, n_nearest_features=None, initial_strategy='mean', fill_value=None, imputation_order='ascending', skip_complete=False, min_value=-inf, max_value=inf, verbose=0, random_state=None, add_indicator=False, keep_empty_features=False)[source]#
多元插补器,从所有其他特征估计每个特征。
一种通过对每个具有缺失值的特征进行建模(将其作为其他特征的函数)来插补缺失值的策略,采用循环方式。
在用户指南中阅读更多内容。
0.21 版本新增。
注意
该估计器目前仍处于实验阶段:预测结果和API可能会在没有任何弃用周期的情况下发生变化。要使用它,您需要显式导入
enable_iterative_imputer>>> # explicitly require this experimental feature >>> from sklearn.experimental import enable_iterative_imputer # noqa >>> # now you can import normally from sklearn.impute >>> from sklearn.impute import IterativeImputer
- 参数:
- estimatorestimator object, default=BayesianRidge()
在循环插补的每个步骤中使用的估计器。如果
sample_posterior=True,则估计器的predict方法必须支持return_std。- missing_valuesint or np.nan, default=np.nan
缺失值的占位符。所有出现
missing_values的地方都将被插补。对于带有可空整型dtype且包含缺失值的pandas DataFrame,missing_values应设置为np.nan,因为pd.NA将被转换为np.nan。- sample_posteriorbool, default=False
是否从拟合估计器(Gaussian)的预测后验分布中为每次插补进行采样。如果设置为
True,则估计器的predict方法必须支持return_std。如果使用IterativeImputer进行多次插补,则设置为True。- max_iterint, default=10
在返回最后一轮计算出的插补结果之前执行的最大插补轮数。一轮是对每个具有缺失值的特征进行一次插补。当满足停止准则
max(abs(X_t - X_{t-1}))/max(abs(X[known_vals])) < tol时,迭代停止,其中X_t是第t次迭代时的X。请注意,只有当sample_posterior=False时才应用提前停止。- tolfloat, default=1e-3
停止条件的容差。
- n_nearest_featuresint, default=None
用于估计每个特征列缺失值的其他特征的数量。特征之间的接近度是通过每对特征之间的绝对相关系数(在初始插补之后)来衡量的。为了确保在整个插补过程中对特征的覆盖,邻近特征不一定是最接近的,而是根据与每个被插补目标特征的相关性成比例的概率抽取的。当特征数量非常大时,可以显著提高速度。如果为
None,则将使用所有特征。- initial_strategy{‘mean’, ‘median’, ‘most_frequent’, ‘constant’}, default=’mean’
用于初始化缺失值的策略。与
SimpleImputer中的strategy参数相同。- fill_valuestr or numerical value, default=None
当
strategy="constant"时,fill_value用于替换所有出现的missing_values。对于字符串或对象数据类型,fill_value必须是一个字符串。如果为None,当插补数值数据时,fill_value将为0,对于字符串或对象数据类型则为“missing_value”。在版本 1.3 中新增。
- imputation_order{‘ascending’, ‘descending’, ‘roman’, ‘arabic’, ‘random’}, default=’ascending’
特征被插补的顺序。可能的值包括
'ascending':从缺失值最少的特征到缺失值最多的特征。'descending':从缺失值最多的特征到缺失值最少的特征。'roman':从左到右。'arabic':从右到左。'random':每轮使用随机顺序。
- skip_completebool, default=False
如果为
True,则在transform期间具有缺失值但在fit期间没有缺失值的特征将仅使用初始插补方法进行插补。如果存在许多在fit和transform时都没有缺失值的特征,则设置为True可以节省计算资源。- min_valuefloat or array-like of shape (n_features,), default=-np.inf
可能的最小插补值。如果为标量,则广播为形状
(n_features,)。如果为数组形式,则预期形状为(n_features,),每个特征对应一个最小值。默认值为-np.inf。Changed in version 0.23: 添加了对数组形式的支持。
- max_valuefloat or array-like of shape (n_features,), default=np.inf
可能的最小插补值。如果为标量,则广播为形状
(n_features,)。如果为数组形式,则预期形状为(n_features,),每个特征对应一个最大值。默认值为np.inf。Changed in version 0.23: 添加了对数组形式的支持。
- verboseint, default=0
冗余度标志,控制在函数评估时发出的调试消息。值越高,越冗余。可以是0、1或2。
- random_stateint, RandomState instance or None, default=None
使用的伪随机数生成器种子。如果
n_nearest_features不为None,则随机化估计器特征的选择;如果imputation_order为random,则随机化插补顺序;如果sample_posterior=True,则随机化后验采样。使用整数以实现确定性。请参阅词汇表。- add_indicatorbool, default=False
如果为
True,则MissingIndicator转换器将堆叠在imputer的转换输出上。这使得预测估计器能够考虑缺失情况,即使进行了插补。如果一个特征在fit/train时没有缺失值,那么即使在transform/test时有缺失值,该特征也不会出现在缺失指标中。- keep_empty_featuresbool, default=False
如果为True,当调用
transform时,将返回在调用fit时仅由缺失值组成的特征的结果。插补值始终为0,除非initial_strategy="constant",此时将使用fill_value。1.2 版本新增。
- 属性:
- initial_imputer_object of type
SimpleImputer 用于初始化缺失值的imputer。
- imputation_sequence_list of tuples
每个元组包含
(feat_idx, neighbor_feat_idx, estimator),其中feat_idx是当前要插补的特征,neighbor_feat_idx是用于插补当前特征的其他特征的数组,estimator是用于插补的已训练估计器。长度为self.n_features_with_missing_ * self.n_iter_。- n_iter_int
已发生的迭代轮数。如果达到了提前停止准则,将小于
self.max_iter。- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
- n_features_with_missing_int
具有缺失值的特征数量。
- indicator_
MissingIndicator 用于添加缺失值二进制指示符的指示器。如果
add_indicator=False,则为None。- random_state_RandomState instance
由种子、随机数生成器或
np.random生成的RandomState实例。
- initial_imputer_object of type
另请参阅
SimpleImputer使用简单策略完成缺失值的单变量插补器。
KNNImputer多元imputer,使用最近的样本估计缺失特征。
注意事项
为了支持归纳模式下的插补,我们在
fit阶段存储每个特征的估计器,并在transform阶段按顺序预测而无需重新拟合。在
fit时包含所有缺失值的特征将在transform时被丢弃。使用默认设置时,imputer的缩放比例为\(\mathcal{O}(knp^3\min(n,p))\),其中\(k\) =
max_iter,\(n\)为样本数,\(p\)为特征数。因此,当特征数量增加时,其成本会变得非常高昂。设置n_nearest_features << n_features,skip_complete=True或增加tol有助于降低计算成本。根据缺失值的性质,简单的imputer在预测上下文中可能更可取。
References
示例
>>> import numpy as np >>> from sklearn.experimental import enable_iterative_imputer >>> from sklearn.impute import IterativeImputer >>> imp_mean = IterativeImputer(random_state=0) >>> imp_mean.fit([[7, 2, 3], [4, np.nan, 6], [10, 5, 9]]) IterativeImputer(random_state=0) >>> X = [[np.nan, 2, 3], [4, np.nan, 6], [10, np.nan, 9]] >>> imp_mean.transform(X) array([[ 6.9584, 2. , 3. ], [ 4. , 2.6000, 6. ], [10. , 4.9999, 9. ]])
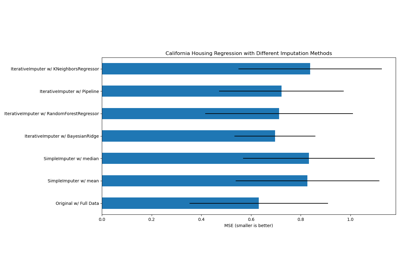
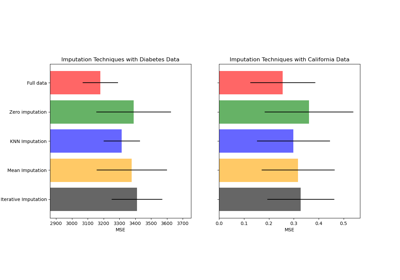
有关更详细的示例,请参阅在构建估计器之前插补缺失值或使用IterativeImputer的变体插补缺失值。
- fit(X, y=None, **fit_params)[source]#
在
X上拟合imputer并返回自身。- 参数:
- Xarray-like, shape (n_samples, n_features)
输入数据,其中
n_samples是样本数量,n_features是特征数量。- y被忽略
未使用,按照惯例为保持 API 一致性而存在。
- **fit_paramsdict
通过元数据路由API路由到子估计器的
fit方法的参数。Added in version 1.5: 仅当设置了
sklearn.set_config(enable_metadata_routing=True)时可用。有关更多详细信息,请参阅元数据路由用户指南。
- 返回:
- selfobject
拟合的估计器。
- fit_transform(X, y=None, **params)[source]#
在
X上拟合imputer并返回转换后的X。- 参数:
- Xarray-like, shape (n_samples, n_features)
输入数据,其中
n_samples是样本数量,n_features是特征数量。- y被忽略
未使用,按照惯例为保持 API 一致性而存在。
- **paramsdict
通过元数据路由API路由到子估计器的
fit方法的参数。Added in version 1.5: 仅当设置了
sklearn.set_config(enable_metadata_routing=True)时可用。有关更多详细信息,请参阅元数据路由用户指南。
- 返回:
- Xtarray-like, shape (n_samples, n_features)
插补后的输入数据。
- get_feature_names_out(input_features=None)[source]#
获取转换的输出特征名称。
- 参数:
- input_featuresarray-like of str or None, default=None
输入特征。
如果
input_features为None,则使用feature_names_in_作为输入特征名称。如果feature_names_in_未定义,则生成以下输入特征名称:["x0", "x1", ..., "x(n_features_in_ - 1)"]。如果
input_features是 array-like,则如果定义了feature_names_in_,input_features必须与feature_names_in_匹配。
- 返回:
- feature_names_outstr 对象的 ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
1.5 版本新增。
- 返回:
- routingMetadataRouter
封装路由信息的
MetadataRouter。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用 API 的示例,请参阅引入 set_output API。
- 参数:
- transform{“default”, “pandas”, “polars”}, default=None
配置
transform和fit_transform的输出。"default": 转换器的默认输出格式"pandas": DataFrame 输出"polars": Polars 输出None: 转换配置保持不变
1.4 版本新增: 添加了
"polars"选项。
- 返回:
- selfestimator instance
估计器实例。