SplineTransformer#
- class sklearn.preprocessing.SplineTransformer(n_knots=5, degree=3, *, knots='uniform', extrapolation='constant', include_bias=True, order='C', handle_missing='error', sparse_output=False)[source]#
为特征生成单变量 B-样条基。
生成一个由
n_splines=n_knots + degree - 1(当extrapolation="periodic"时为n_knots - 1)样条基函数 (B-样条) 组成的新特征矩阵,每个特征的阶数为 `degree`。要了解更多关于 SplineTransformer 类的信息,请访问:与时间相关的特征工程
在用户指南中阅读更多信息。
1.0 版本新增。
- 参数:
- n_knotsint, default=5
如果
knots等于 {'uniform', 'quantile'} 之一,则为样条结点的数量。必须大于或等于 2。如果knots是数组型,则忽略此参数。- degreeint,默认值为3
样条基的多项式次数。必须是非负整数。
- knots{'uniform', 'quantile'} 或 形状为 (n_knots, n_features) 的数组型, default='uniform'
设置结点位置,使第一个结点 <= 特征 <= 最后一个结点。
如果为 'uniform',则
n_knots个结点均匀分布在特征的最小值到最大值之间。如果为 'quantile',则它们均匀分布在特征的分位数上。
如果给定数组型,它直接指定排序的结点位置,包括边界结点。请注意,在内部,第一个结点之前和最后一个结点之后都会添加
degree个结点。
- extrapolation{'error', 'constant', 'linear', 'continue', 'periodic'}, default='constant'
如果为 'error',则超出训练特征的最小值和最大值的值会引发
ValueError。如果为 'constant',则样条在特征的最小值和最大值处的值将用作常数外推。如果为 'linear',则使用线性外推。如果为 'continue',则样条按原样外推,即scipy.interpolate.BSpline中的选项extrapolate=True。如果为 'periodic',则使用周期样条,其周期等于第一个结点和最后一个结点之间的距离。周期样条强制第一个结点和最后一个结点处的函数值和导数相等。例如,这可以避免在从自然周期性的“一年中的某一天”输入特征派生的样条特征中,在 12 月 31 日和 1 月 1 日之间引入任意跳跃。在这种情况下,建议手动设置结点值以控制周期。- include_biasbool, default=True
如果为 False,则特征数据范围内的最后一个样条元素将被丢弃。由于 B 样条对每个数据点的样条基函数求和为一,因此它们隐式包含一个偏差项,即一列全为一的列。它在线性模型中充当截距项。
- order{'C', 'F'}, default='C'
稠密情况下的输出数组顺序。'F' 顺序计算速度更快,但可能会减慢后续估计器的速度。
- handle_missing{'error', 'zeros'}, default='error'
指定处理缺失值的方式。
'error':如果在
fit期间存在np.nan值,则会引发错误。'zeros':用值
0对缺失值的样条进行编码。
请注意,
handle_missing='zeros'与首先用零填充缺失值然后创建样条基有所不同。后者会创建在缺失值处具有非零值的样条基函数,而此选项只是简单地将所有样条基函数的值在缺失值处设置为零。1.8 版本新增。
- sparse_outputbool, default=False
如果设置为 True,将返回稀疏 CSR 矩阵,否则将返回一个数组。
1.2 版本新增。
- 属性:
- bsplines_形状为 (n_features,) 的列表
BSplines 对象列表,每个特征一个。
- n_features_in_int
输入特征的总数。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
- n_features_out_int
输出特征的总数,计算公式为
n_features * n_splines,其中n_splines是 B 样条的基元素数量,非周期样条为n_knots + degree - 1,周期样条为n_knots - 1。如果include_bias=False,则为n_features * (n_splines - 1)。
另请参阅
KBinsDiscretizer将连续数据分箱到间隔中的变换器。
PolynomialFeatures生成多项式和交互特征的变换器。
注意事项
高阶和大量的结点可能导致过拟合。
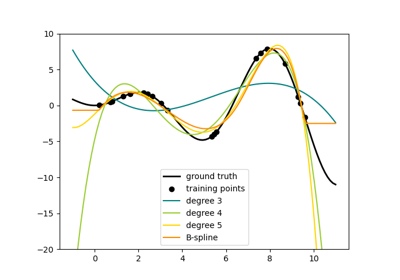
请参阅 examples/linear_model/plot_polynomial_interpolation.py。
示例
>>> import numpy as np >>> from sklearn.preprocessing import SplineTransformer >>> X = np.arange(6).reshape(6, 1) >>> spline = SplineTransformer(degree=2, n_knots=3) >>> spline.fit_transform(X) array([[0.5 , 0.5 , 0. , 0. ], [0.18, 0.74, 0.08, 0. ], [0.02, 0.66, 0.32, 0. ], [0. , 0.32, 0.66, 0.02], [0. , 0.08, 0.74, 0.18], [0. , 0. , 0.5 , 0.5 ]])
- fit(X, y=None, sample_weight=None)[source]#
计算样条的结点位置。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
数据。
- yNone
忽略。
- sample_weight形状为 (n_samples,) 的数组型, default = None
每个样本的单独权重。如果
knots="quantile",则用于计算分位数。对于knots="uniform",零权重观测值在查找X的最小值和最大值时被忽略。
- 返回:
- selfobject
已拟合的转换器。
- fit_transform(X, y=None, **fit_params)[source]#
拟合数据,然后对其进行转换。
使用可选参数
fit_params将转换器拟合到X和y,并返回X的转换版本。- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
输入样本。
- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组对象,默认=None
目标值(对于无监督转换,为 None)。
- **fit_paramsdict
额外的拟合参数。仅当估计器在其
fit方法中接受额外的参数时才传递。
- 返回:
- X_newndarray array of shape (n_samples, n_features_new)
转换后的数组。
- get_feature_names_out(input_features=None)[source]#
获取转换的输出特征名称。
- 参数:
- input_featuresarray-like of str or None, default=None
输入特征。
如果
input_features为None,则使用feature_names_in_作为输入特征名称。如果feature_names_in_未定义,则生成以下输入特征名称:["x0", "x1", ..., "x(n_features_in_ - 1)"]。如果
input_features是 array-like,则如果定义了feature_names_in_,input_features必须与feature_names_in_匹配。
- 返回:
- feature_names_outstr 对象的 ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SplineTransformer[source]#
配置是否应请求元数据以传递给
fit方法。请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True:请求元数据,如果提供则传递给fit。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给fit。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
fit方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用 API 的示例,请参阅引入 set_output API。
- 参数:
- transform{“default”, “pandas”, “polars”}, default=None
配置
transform和fit_transform的输出。"default": 转换器的默认输出格式"pandas": DataFrame 输出"polars": Polars 输出None: 转换配置保持不变
1.4 版本新增: 添加了
"polars"选项。
- 返回:
- selfestimator instance
估计器实例。