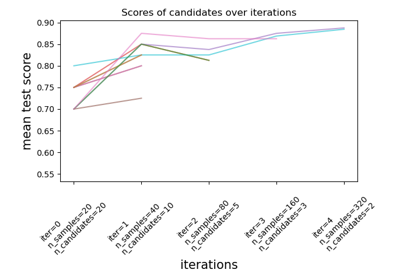
HalvingRandomSearchCV#
- class sklearn.model_selection.HalvingRandomSearchCV(estimator, param_distributions, *, n_candidates='exhaust', factor=3, resource='n_samples', max_resources='auto', min_resources='smallest', aggressive_elimination=False, cv=5, scoring=None, refit=True, error_score=nan, return_train_score=True, random_state=None, n_jobs=None, verbose=0)[source]#
对超参数进行随机搜索。
搜索策略从使用少量资源评估所有候选开始,并迭代选择最佳候选,使用越来越多的资源。
候选从参数空间中随机采样,采样候选的数量由
n_candidates确定。在用户指南中阅读更多内容。
注意
此估计器目前仍处于实验阶段:预测和 API 可能会在没有任何弃用周期的情况下发生变化。要使用它,您需要显式导入
enable_halving_search_cv>>> # explicitly require this experimental feature >>> from sklearn.experimental import enable_halving_search_cv # noqa >>> # now you can import normally from model_selection >>> from sklearn.model_selection import HalvingRandomSearchCV
- 参数:
- estimator估计器对象
假设这实现了 scikit-learn 估计器接口。估计器需要提供一个
score函数,或者必须传入scoring。- param_distributionsdict 或 dict 列表
字典,键为参数名称(
str),值为要尝试的分布或参数列表。分布必须提供用于采样的rvs方法(例如来自 scipy.stats.distributions)。如果给出了列表,则进行均匀采样。如果给出了字典列表,则首先均匀采样一个字典,然后使用该字典按照上述方式采样一个参数。- n_candidates“exhaust” 或 int,默认值=”exhaust”
在第一次迭代中采样的候选参数的数量。使用“exhaust”将采样足够的候选,使得最后一次迭代使用尽可能多的资源,基于
min_resources、max_resources和factor。在这种情况下,min_resources不能是“exhaust”。- factorint 或 float,默认值=3
“减半”参数,它决定了为每个后续迭代选择的候选的比例。例如,
factor=3意味着只选择三分之一的候选。- resource
'n_samples'或 str,默认值='n_samples' 定义随每次迭代增加的资源。默认情况下,资源是样本数量。它也可以设置为基本估计器的任何接受正整数值的参数,例如梯度提升估计器的“n_iterations”或“n_estimators”。在这种情况下,
max_resources不能是“auto”,必须显式设置。- max_resourcesint,默认值='auto'
任何候选在给定迭代中允许使用的最大资源数。默认情况下,当
resource='n_samples'(默认)时,此值设置为n_samples,否则会引发错误。- min_resources{‘exhaust’, ‘smallest’} 或 int,默认值='smallest'
任何候选在给定迭代中允许使用的最小资源量。等效地,这定义了在第一次迭代中分配给每个候选的资源量
r0。“smallest”是一种启发式方法,将
r0设置为一个小值当
resource='n_samples'用于回归问题时为n_splits * 2当
resource='n_samples'用于分类问题时为n_classes * n_splits * 2当
resource != 'n_samples'时为1
“exhaust”将设置
r0,使得最后一次迭代使用尽可能多的资源。具体来说,最后一次迭代将使用小于max_resources的最大值,该值是min_resources和factor的倍数。通常,使用“exhaust”会得到更准确的估计器,但会稍微耗时。“exhaust”在n_candidates='exhaust'时不可用。
请注意,每次迭代中使用的资源量始终是
min_resources的倍数。- aggressive_eliminationbool,默认值=False
这仅在资源不足以将剩余候选者在最后一次迭代后减少到至多
factor的情况下才相关。如果为True,则搜索过程将“重播”第一次迭代,直到候选数量足够小。默认情况下为False,这意味着最后一次迭代可能会评估超过factor个候选。有关更多详细信息,请参阅候选的激进消除。- cvint、交叉验证生成器或可迭代对象,默认值=5
确定交叉验证拆分策略。cv 的可能输入包括
integer,指定
(Stratified)KFold中的折数,一个可迭代对象,产生索引数组形式的 (训练集, 测试集) 拆分。
对于 integer/None 输入,如果估计器是分类器且
y是二元或多类,则使用StratifiedKFold。在所有其他情况下,使用KFold。这些分割器以shuffle=False实例化,因此拆分在不同调用中将保持相同。有关此处可使用的各种交叉验证策略,请参阅 用户指南。
注意
由于实现细节,
cv生成的折叠在对cv.split()的多次调用中必须相同。对于内置的scikit-learn迭代器,这可以通过禁用洗牌 (shuffle=False) 或将cv的random_state参数设置为整数来实现。- scoringstr 或可调用对象,默认=None
用于评估测试集上预测的评分方法。
str: 有关选项,请参阅 String name scorers。
callable: 带有签名
scorer(estimator, X, y)的可调用评分器对象(例如函数)。有关详细信息,请参阅 Callable scorers。None:使用estimator的 默认评估标准。
- refitbool 或可调用对象,默认值=True
使用找到的最佳参数在整个数据集上重新拟合估计器。
当选择最佳估计器时,除了最大分数之外还有其他考虑因素时,
refit可以设置为一个函数,该函数根据cv_results_返回选定的best_index_。在这种情况下,best_estimator_和best_params_将根据返回的best_index_设置,而best_score_属性将不可用。重新拟合的估计器可在
best_estimator_属性中获得,并允许直接在此HalvingRandomSearchCV实例上使用predict。请参阅 此示例,了解如何使用
refit=callable来平衡模型复杂度和交叉验证分数。- error_score‘raise’ 或 numeric
如果估计器拟合发生错误,分配给分数的值。如果设置为“raise”,则引发错误。如果给定数值,则引发 FitFailedWarning。此参数不影响重新拟合步骤,该步骤将始终引发错误。默认值为
np.nan。- return_train_scorebool, default=False
如果为
False,则cv_results_属性将不包括训练分数。计算训练分数用于深入了解不同参数设置如何影响过拟合/欠拟合的权衡。然而,计算训练集上的分数可能计算成本很高,并且不是严格要求用于选择产生最佳泛化性能的参数。- random_stateint, RandomState instance or None, default=None
当
resources != 'n_samples'时用于子采样数据集的伪随机数生成器状态。也用于从可能值列表中进行随机均匀采样,而不是 scipy.stats 分布。传入一个 int 以在多次函数调用中获得可重现的输出。请参阅词汇表。- n_jobsint or None, default=None
并行运行的作业数。
None表示 1,除非在joblib.parallel_backend上下文中。-1表示使用所有处理器。有关更多详细信息,请参阅 Glossary。- verboseint
控制详细程度:值越高,消息越多。
- 属性:
- n_resources_int 列表
每次迭代中使用的资源量。
- n_candidates_int 列表
每次迭代中评估的候选参数数量。
- n_remaining_candidates_int
最后一次迭代后剩余的候选参数数量。它对应于
ceil(n_candidates[-1] / factor)- max_resources_int
任何候选在给定迭代中允许使用的最大资源数。请注意,由于每次迭代中使用的资源数必须是
min_resources_的倍数,因此最后一次迭代中实际使用的资源数可能小于max_resources_。- min_resources_int
在第一次迭代中分配给每个候选的资源量。
- n_iterations_int
实际运行的迭代次数。如果
aggressive_elimination为True,则此值等于n_required_iterations_。否则,此值等于min(n_possible_iterations_, n_required_iterations_)。- n_possible_iterations_int
从
min_resources_资源开始且不超过max_resources_的情况下,可能进行的迭代次数。- n_required_iterations_int
从
min_resources_资源开始,在最后一次迭代中得到少于factor个候选所需的迭代次数。当资源不足时,此值将小于n_possible_iterations_。- cv_results_dict of numpy (masked) ndarrays
一个字典,以列标题作为键,以列作为值,可以导入到 pandas
DataFrame中。它包含大量用于分析搜索结果的信息。请参阅用户指南了解详细信息。有关分析cv_results_的示例,请参阅使用网格搜索进行模型统计比较。- best_estimator_估计器或 dict
搜索选择的估计器,即在保留数据上给出最高分数(或指定最小损失)的估计器。如果
refit=False则不可用。- best_score_float
best_estimator 的平均交叉验证分数。
- best_params_dict
在保留数据上给出最佳结果的参数设置。
- best_index_int
与最佳候选参数设置相对应的
cv_results_数组中的索引。search.cv_results_['params'][search.best_index_]处的字典给出了最佳模型的参数设置,该模型给出了最高平均分数(search.best_score_)。- scorer_function or a dict
用于在保留数据上选择模型最佳参数的评分函数。
- n_splits_int
交叉验证拆分的数量(折叠/迭代)。
- refit_time_float
用于在整个数据集上重新拟合最佳模型所花费的秒数。
仅在
refit不为 False 时存在。- multimetric_bool
评分器是否计算多个指标。
classes_形状为 (n_classes,) 的 ndarray类别标签。
n_features_in_int在 拟合 期间看到的特征数。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当定义了
best_estimator_(有关详细信息,请参阅refit参数的文档)并且best_estimator_在拟合时公开feature_names_in_时才定义。1.0 版本新增。
另请参阅
HalvingGridSearchCV使用逐次减半在参数网格上搜索。
注意事项
根据 scoring 参数,选择的参数是使保留数据分数最大化的参数。
所有得分带 NaN 的参数组合将共享最低排名。
示例
>>> from sklearn.datasets import load_iris >>> from sklearn.ensemble import RandomForestClassifier >>> from sklearn.experimental import enable_halving_search_cv # noqa >>> from sklearn.model_selection import HalvingRandomSearchCV >>> from scipy.stats import randint >>> import numpy as np ... >>> X, y = load_iris(return_X_y=True) >>> clf = RandomForestClassifier(random_state=0) >>> np.random.seed(0) ... >>> param_distributions = {"max_depth": [3, None], ... "min_samples_split": randint(2, 11)} >>> search = HalvingRandomSearchCV(clf, param_distributions, ... resource='n_estimators', ... max_resources=10, ... random_state=0).fit(X, y) >>> search.best_params_ {'max_depth': None, 'min_samples_split': 10, 'n_estimators': 9}
- decision_function(X)[source]#
使用找到的最佳参数调用估计器上的 decision_function。
仅当
refit=True且底层估计器支持decision_function时可用。- 参数:
- X可索引对象,长度 n_samples
必须满足底层估计器的输入假设。
- 返回:
- y_score形状为 (n_samples,) 或 (n_samples, n_classes) 或 (n_samples, n_classes * (n_classes-1) / 2) 的 ndarray
基于具有最佳找到参数的估计器对
X的决策函数结果。
- fit(X, y=None, **params)[source]#
使用所有参数集运行拟合。
- 参数:
- Xarray-like, shape (n_samples, n_features)
训练向量,其中
n_samples是样本数,n_features是特征数。- y类数组,形状 (n_samples,) 或 (n_samples, n_output),可选
相对于 X 的分类或回归目标;对于无监督学习为 None。
- **paramsstr -> object 字典
传递给估计器
fit方法的参数。
- 返回:
- selfobject
已拟合估计器的实例。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
1.4 版本新增。
- 返回:
- routingMetadataRouter
封装路由信息的
MetadataRouter。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- inverse_transform(X)[source]#
使用找到的最佳参数调用估计器上的 inverse_transform。
仅当底层估计器实现
inverse_transform且refit=True时可用。- 参数:
- X可索引对象,长度 n_samples
必须满足底层估计器的输入假设。
- 返回:
- X_original形状为 (n_samples, n_features) 的 {ndarray, sparse matrix}
基于具有最佳找到参数的估计器对
X的inverse_transform函数结果。
- predict(X)[source]#
使用找到的最佳参数调用估计器上的 predict。
仅当
refit=True且底层估计器支持predict时可用。- 参数:
- X可索引对象,长度 n_samples
必须满足底层估计器的输入假设。
- 返回:
- y_pred形状为 (n_samples,) 的 ndarray
基于具有最佳找到参数的估计器对
X的预测标签或值。
- predict_log_proba(X)[source]#
使用找到的最佳参数调用估计器上的 predict_log_proba。
仅当
refit=True且底层估计器支持predict_log_proba时可用。- 参数:
- X可索引对象,长度 n_samples
必须满足底层估计器的输入假设。
- 返回:
- y_pred形状为 (n_samples,) 或 (n_samples, n_classes) 的 ndarray
基于具有最佳找到参数的估计器对
X的预测类别对数概率。类别的顺序对应于已拟合属性 classes_ 中的顺序。
- predict_proba(X)[source]#
使用找到的最佳参数调用估计器上的 predict_proba。
仅当
refit=True且底层估计器支持predict_proba时可用。- 参数:
- X可索引对象,长度 n_samples
必须满足底层估计器的输入假设。
- 返回:
- y_pred形状为 (n_samples,) 或 (n_samples, n_classes) 的 ndarray
基于具有最佳找到参数的估计器对
X的预测类别概率。类别的顺序对应于已拟合属性 classes_ 中的顺序。
- score(X, y=None, **params)[source]#
如果估计器已重新拟合,则返回给定数据的分数。
如果提供了
scoring,则使用它定义的分数;否则使用best_estimator_.score方法。- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
输入数据,其中
n_samples是样本数量,n_features是特征数量。- y形状为 (n_samples, n_output) 或 (n_samples,) 的类数组对象, default=None
相对于 X 的分类或回归目标;对于无监督学习为 None。
- **paramsdict
要传递给底层评分器(s)的参数。
1.4 版本新增: 仅当
enable_metadata_routing=True时可用。有关更多详细信息,请参阅 元数据路由用户指南。
- 返回:
- scorefloat
如果提供了
scoring,则使用它定义的分数;否则使用best_estimator_.score方法。
- score_samples(X)[source]#
使用找到的最佳参数调用估计器上的 score_samples。
仅当
refit=True且底层估计器支持score_samples时可用。0.24 版本新增。
- 参数:
- Xiterable
用于预测的数据。必须满足底层估计器的输入要求。
- 返回:
- y_score形状为 (n_samples,) 的 ndarray
best_estimator_.score_samples方法。