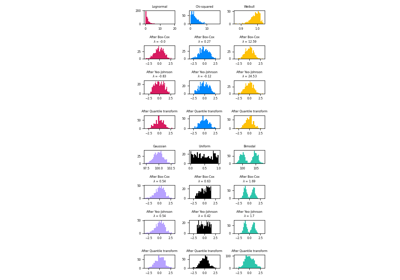
QuantileTransformer#
- class sklearn.preprocessing.QuantileTransformer(*, n_quantiles=1000, output_distribution='uniform', ignore_implicit_zeros=False, subsample=10000, random_state=None, copy=True)[源代码]#
使用分位数信息转换特征。
此方法将特征转换为服从均匀分布或正态分布。因此,对于给定的特征,这种转换倾向于分散最常见的值。它还减少了(边缘)异常值的影响:因此,这是一种鲁棒的预处理方案。
转换独立应用于每个特征。首先,使用特征的累积分布函数的估计值将原始值映射到均匀分布。然后使用相关的分位数函数将获得的值映射到所需的输出分布。新/未见数据中低于或高于拟合范围的特征值将被映射到输出分布的边界。请注意,此转换是非线性的。它可能会扭曲相同尺度下测量的变量之间的线性相关性,但会使不同尺度下测量的变量更直接地可比较。
有关示例可视化,请参阅 将 QuantileTransformer 与其他缩放器进行比较。
更多信息请参阅 用户指南。
Added in version 0.19.
- 参数:
- n_quantilesint, default=1000 或 n_samples
要计算的分位数数量。它对应于离散化累积分布函数使用的标志点数量。如果 n_quantiles 大于样本数量,则将 n_quantiles 设置为样本数量,因为更多的分位数不能更好地近似累积分布函数估计器。
- output_distribution{‘uniform’, ‘normal’}, default=’uniform’
转换数据的边际分布。选项是“uniform”(默认)或“normal”。
- ignore_implicit_zerosbool, default=False
仅适用于稀疏矩阵。如果为 True,则在计算分位数统计信息时会丢弃矩阵的稀疏条目。如果为 False,则将这些条目视为零。
- subsampleint 或 None, default=10_000
用于估计分位数的最大样本数,以提高计算效率。请注意,对于值相同的稀疏矩阵和密集矩阵,子采样过程可能会有所不同。通过将
subsample=None来禁用子采样。1.5 版本新增: 添加了
None选项以禁用子采样。- random_stateint, RandomState instance or None, default=None
确定用于子采样和平滑噪声的随机数生成。有关更多详细信息,请参阅
subsample。传递一个整数以在多次函数调用之间获得可复现的结果。请参阅 术语表。- copy布尔值, 默认为 True
设置为 False 以执行原地转换并避免复制(如果输入已经是 numpy 数组)。
- 属性:
另请参阅
quantile_transform不包含估算器 API 的等效函数。
PowerTransformer使用幂变换执行到正态分布的映射。
StandardScaler执行标准化,该标准化速度更快,但对异常值的鲁棒性较差。
RobustScaler执行鲁棒标准化,它消除了异常值的影响,但没有将异常值和内点置于相同的尺度。
注意事项
NaN 被视为缺失值:在拟合过程中忽略,在转换过程中保持。
示例
>>> import numpy as np >>> from sklearn.preprocessing import QuantileTransformer >>> rng = np.random.RandomState(0) >>> X = np.sort(rng.normal(loc=0.5, scale=0.25, size=(25, 1)), axis=0) >>> qt = QuantileTransformer(n_quantiles=10, random_state=0) >>> qt.fit_transform(X) array([...])
- fit(X, y=None)[源代码]#
计算用于转换的分位数。
- 参数:
- Xshape 为 (n_samples, n_features) 的 {array-like, sparse matrix}
用于沿特征轴进行缩放的数据。如果提供了稀疏矩阵,它将被转换为稀疏
csc_matrix。此外,如果ignore_implicit_zeros为 False,则稀疏矩阵必须是非负的。- yNone
忽略。
- 返回:
- selfobject
已拟合的转换器。
- fit_transform(X, y=None, **fit_params)[源代码]#
拟合数据,然后对其进行转换。
使用可选参数
fit_params将转换器拟合到X和y,并返回X的转换版本。- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
输入样本。
- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组对象,默认=None
目标值(对于无监督转换,为 None)。
- **fit_paramsdict
额外的拟合参数。仅当估计器在其
fit方法中接受额外的参数时才传递。
- 返回:
- X_newndarray array of shape (n_samples, n_features_new)
转换后的数组。
- get_feature_names_out(input_features=None)[源代码]#
获取转换的输出特征名称。
- 参数:
- input_featuresarray-like of str or None, default=None
输入特征。
如果
input_features为None,则使用feature_names_in_作为输入特征名称。如果feature_names_in_未定义,则生成以下输入特征名称:["x0", "x1", ..., "x(n_features_in_ - 1)"]。如果
input_features是 array-like,则如果定义了feature_names_in_,input_features必须与feature_names_in_匹配。
- 返回:
- feature_names_outstr 对象的 ndarray
与输入特征相同。
- get_metadata_routing()[源代码]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[源代码]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- inverse_transform(X)[源代码]#
反向投影到原始空间。
- 参数:
- Xshape 为 (n_samples, n_features) 的 {array-like, sparse matrix}
用于沿特征轴进行缩放的数据。如果提供了稀疏矩阵,它将被转换为稀疏
csc_matrix。此外,如果ignore_implicit_zeros为 False,则稀疏矩阵必须是非负的。
- 返回:
- X_original{ndarray, sparse matrix} of (n_samples, n_features)
投影后的数据。
- set_output(*, transform=None)[源代码]#
设置输出容器。
有关如何使用 API 的示例,请参阅引入 set_output API。
- 参数:
- transform{“default”, “pandas”, “polars”}, default=None
配置
transform和fit_transform的输出。"default": 转换器的默认输出格式"pandas": DataFrame 输出"polars": Polars 输出None: 转换配置保持不变
1.4 版本新增: 添加了
"polars"选项。
- 返回:
- selfestimator instance
估计器实例。