KNeighborsRegressor#
- class sklearn.neighbors.KNeighborsRegressor(n_neighbors=5, *, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None)[source]#
基于k-近邻的回归器。
通过训练集中最近邻居相关联的目标的局部插值来预测目标。
在用户指南中阅读更多内容。
0.9版本新增。
- 参数:
- n_neighborsint, default=5
默认情况下用于
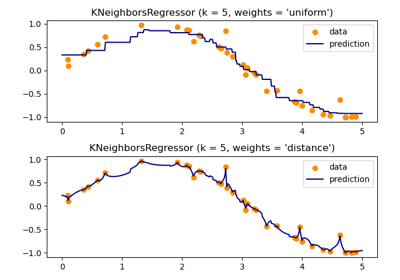
kneighbors查询的邻居数量。- weights{‘uniform’, ‘distance’}、可调用对象或None, default=’uniform’
预测中使用的权重函数。可能的值:
‘uniform’ : 均匀权重。每个邻域中的所有点都具有相同的权重。
‘distance’ : 按距离的倒数对点加权。在这种情况下,查询点较近的邻居将比距离较远的邻居具有更大的影响力。
[callable] : 用户定义的函数,接受一个距离数组,并返回一个具有相同形状的权重数组。
默认使用均匀权重。
有关不同加权方案对预测影响的演示,请参见以下示例:近邻回归。
- algorithm{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default=’auto’
用于计算最近邻的算法
注意:在稀疏输入上拟合将覆盖此参数的设置,使用暴力搜索。
- leaf_sizeint, default=30
传递给 BallTree 或 KDTree 的叶子大小。这会影响构建和查询的速度,以及存储树所需的内存。最优值取决于问题的性质。
- pfloat, default=2
Minkowski 度量的幂参数。当 p = 1 时,这等同于使用 manhattan_distance (l1);当 p = 2 时,等同于 euclidean_distance (l2)。对于任意 p,使用 minkowski_distance (l_p)。
- metricstr, DistanceMetric 对象或可调用对象, default=’minkowski’
用于距离计算的度量。默认为“minkowski”,当 p = 2 时,其结果为标准欧几里得距离。有关有效度量值,请参见scipy.spatial.distance的文档以及
distance_metrics中列出的度量。如果度量为“precomputed”,则假定 X 是一个距离矩阵,并且在拟合期间必须是方阵。X 可以是一个稀疏图,在这种情况下,只考虑“非零”元素作为邻居。
如果度量是可调用函数,它接受两个表示一维向量的数组作为输入,并且必须返回一个值,表示这些向量之间的距离。这适用于 Scipy 的度量,但效率不如将度量名称作为字符串传递。
如果度量是 DistanceMetric 对象,它将直接传递给底层计算例程。
- metric_paramsdict, default=None
度量函数的附加关键字参数。
- n_jobsint, default=None
用于邻居搜索的并行作业数量。
None表示1,除非在joblib.parallel_backend上下文中使用。-1表示使用所有处理器。有关更多详细信息,请参见术语表。不影响fit方法。
- 属性:
- effective_metric_str 或 可调用对象
要使用的距离度量。它将与
metric参数相同或其同义词,例如,如果metric参数设置为“minkowski”且p参数设置为2,则为“euclidean”。- effective_metric_params_dict
度量函数的附加关键字参数。对于大多数度量,将与
metric_params参数相同,但也可能包含p参数值,如果effective_metric_属性设置为“minkowski”。- n_features_in_int
在拟合期间观察到的特征数量。
0.24版本新增。
- feature_names_in_形状为 (
n_features_in_,) 的ndarray 在拟合期间观察到的特征名称。仅当
X的特征名称均为字符串时才定义。1.0版本新增。
- n_samples_fit_int
拟合数据中的样本数量。
另请参见
NearestNeighbors用于实现邻居搜索的无监督学习器。
RadiusNeighborsRegressor基于固定半径内邻居的回归。
KNeighborsClassifier实现k-近邻投票的分类器。
RadiusNeighborsClassifier实现给定半径内邻居投票的分类器。
注意
有关近邻算法,请参见在线文档中关于
algorithm和leaf_size选择的讨论近邻。警告
关于近邻算法,如果发现两个邻居,邻居
k+1和k具有相同的距离但标签不同,则结果将取决于训练数据的顺序。https://zh.wikipedia.org/wiki/K-%E8%BF%91%E9%82%BB%E7%AE%97%E6%B3%95
示例
>>> X = [[0], [1], [2], [3]] >>> y = [0, 0, 1, 1] >>> from sklearn.neighbors import KNeighborsRegressor >>> neigh = KNeighborsRegressor(n_neighbors=2) >>> neigh.fit(X, y) KNeighborsRegressor(...) >>> print(neigh.predict([[1.5]])) [0.5]
- fit(X, y)[source]#
根据训练数据集拟合k-近邻回归器。
- 参数:
- X{array-like, 稀疏矩阵}, 形状为 (n_samples, n_features) 或 (n_samples, n_samples) 如果 metric=’precomputed’
训练数据。
- y{array-like, 稀疏矩阵}, 形状为 (n_samples,) 或 (n_samples, n_outputs)
目标值。
- 返回:
- selfKNeighborsRegressor
拟合后的k-近邻回归器。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看用户指南,了解路由机制的工作原理。
- 返回:
- routingMetadataRequest
一个包含路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器及其包含的作为估计器的子对象的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- kneighbors(X=None, n_neighbors=None, return_distance=True)[source]#
查找一个点的 K 个邻居。
返回每个点的邻居索引和距离。
- 参数:
- X{array-like, 稀疏矩阵}, 形状为 (n_queries, n_features), 或 (n_queries, n_indexed) 如果 metric == ‘precomputed’, default=None
查询点或点集。如果未提供,则返回每个索引点的邻居。在这种情况下,查询点不被视为其自身的邻居。
- n_neighborsint, default=None
每个样本所需的邻居数量。默认值为构造函数中传递的值。
- return_distancebool, default=True
是否返回距离。
- 返回:
- neigh_dist形状为 (n_queries, n_neighbors) 的 ndarray
表示到点的长度的数组,仅在 return_distance=True 时存在。
- neigh_ind形状为 (n_queries, n_neighbors) 的 ndarray
总体矩阵中最接近点的索引。
示例
在以下示例中,我们从表示数据集的数组构造了一个 NearestNeighbors 类,并询问哪个点最接近 [1,1,1]
>>> samples = [[0., 0., 0.], [0., .5, 0.], [1., 1., .5]] >>> from sklearn.neighbors import NearestNeighbors >>> neigh = NearestNeighbors(n_neighbors=1) >>> neigh.fit(samples) NearestNeighbors(n_neighbors=1) >>> print(neigh.kneighbors([[1., 1., 1.]])) (array([[0.5]]), array([[2]]))
正如你所见,它返回 [[0.5]] 和 [[2]],这意味着该元素距离为 0.5,是样本中的第三个元素(索引从 0 开始)。你也可以查询多个点
>>> X = [[0., 1., 0.], [1., 0., 1.]] >>> neigh.kneighbors(X, return_distance=False) array([[1], [2]]...)
- kneighbors_graph(X=None, n_neighbors=None, mode='connectivity')[source]#
计算 X 中点的 k-邻居(加权)图。
- 参数:
- X{array-like, 稀疏矩阵}, 形状为 (n_queries, n_features), 或 (n_queries, n_indexed) 如果 metric == ‘precomputed’, default=None
查询点或点集。如果未提供,则返回每个索引点的邻居。在这种情况下,查询点不被视为其自身的邻居。对于
metric='precomputed',形状应为 (n_queries, n_indexed)。否则,形状应为 (n_queries, n_features)。- n_neighborsint, default=None
每个样本的邻居数量。默认值为构造函数中传递的值。
- mode{‘connectivity’, ‘distance’}, default=’connectivity’
返回矩阵的类型:‘connectivity’将返回带有一和零的连接矩阵;在‘distance’中,边是点之间的距离,距离类型取决于NearestNeighbors类中选择的度量参数。
- 返回:
- A形状为 (n_queries, n_samples_fit) 的稀疏矩阵
n_samples_fit是拟合数据中的样本数量。A[i, j]表示连接i到j的边的权重。矩阵是 CSR 格式。
另请参见
NearestNeighbors.radius_neighbors_graph计算 X 中点的邻居(加权)图。
示例
>>> X = [[0], [3], [1]] >>> from sklearn.neighbors import NearestNeighbors >>> neigh = NearestNeighbors(n_neighbors=2) >>> neigh.fit(X) NearestNeighbors(n_neighbors=2) >>> A = neigh.kneighbors_graph(X) >>> A.toarray() array([[1., 0., 1.], [0., 1., 1.], [1., 0., 1.]])
- predict(X)[source]#
预测所提供数据的目标。
- 参数:
- X{array-like, 稀疏矩阵}, 形状为 (n_queries, n_features), 或 (n_queries, n_indexed) 如果 metric == ‘precomputed’, 或 None
测试样本。如果为
None,则返回所有索引点的预测;在这种情况下,点不被视为其自身的邻居。
- 返回:
- y形状为 (n_queries,) 或 (n_queries, n_outputs) 的 ndarray, dtype=int
目标值。
- score(X, y, sample_weight=None)[source]#
返回测试数据上的决定系数。
决定系数 \(R^2\) 定义为 \((1 - \frac{u}{v})\),其中 \(u\) 是残差平方和
((y_true - y_pred)** 2).sum(),\(v\) 是总平方和((y_true - y_true.mean()) ** 2).sum()。最佳可能分数为 1.0,它也可以为负值(因为模型可能任意地差)。一个始终预测y期望值(不考虑输入特征)的常数模型将得到 0.0 的 \(R^2\) 分数。- 参数:
- X形状为 (n_samples, n_features) 的 array-like
测试样本。对于某些估计器,这可能是一个预计算的核矩阵或一个通用对象列表,其形状为
(n_samples, n_samples_fitted),其中n_samples_fitted是估计器拟合中使用的样本数量。- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的 array-like
X的真实值。- sample_weight形状为 (n_samples,) 的 array-like, default=None
样本权重。
- 返回:
- scorefloat
self.predict(X)相对于y的\(R^2\)。
注意
在调用回归器的
score方法时使用的\(R^2\)分数,从0.23版本开始使用multioutput='uniform_average',以与r2_score的默认值保持一致。这会影响所有多输出回归器(除了MultiOutputRegressor)的score方法。
- set_params(**params)[source]#
设置此估计器的参数。
此方法适用于简单估计器以及嵌套对象(例如
Pipeline)。后者具有<component>__<parameter>形式的参数,因此可以更新嵌套对象的每个组件。- 参数:
- **paramsdict
估计器参数。
- 返回:
- self估计器实例
估计器实例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') KNeighborsRegressor[source]#
请求传递给
score方法的元数据。请注意,此方法仅在
enable_metadata_routing=True时相关(参见sklearn.set_config)。请参见用户指南,了解路由机制的工作原理。每个参数的选项是
True: 请求元数据,如果提供则传递给score。如果未提供元数据,则忽略请求。False: 不请求元数据,元估计器不会将其传递给score。None: 不请求元数据,如果用户提供元数据,元估计器将引发错误。str: 元数据应使用此给定别名而不是原始名称传递给元估计器。
默认值(
sklearn.utils.metadata_routing.UNCHANGED)保留现有请求。这允许您更改某些参数的请求而不更改其他参数。1.3版本新增。
注意
此方法仅在此估计器用作元估计器的子估计器时相关,例如在
Pipeline内部使用。否则,它没有效果。- 参数:
- sample_weightstr, True, False, 或 None, default=sklearn.utils.metadata_routing.UNCHANGED
score方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。