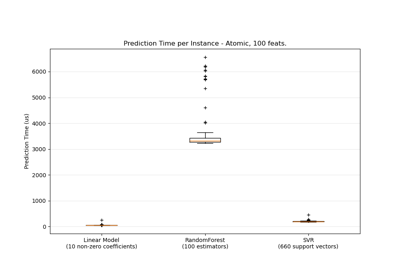
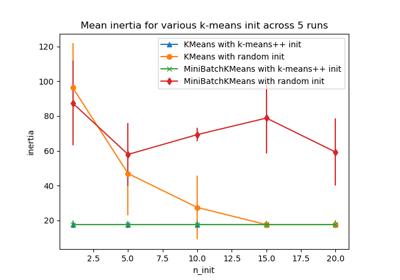
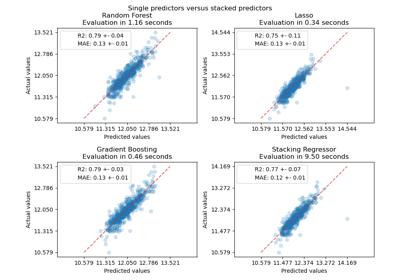
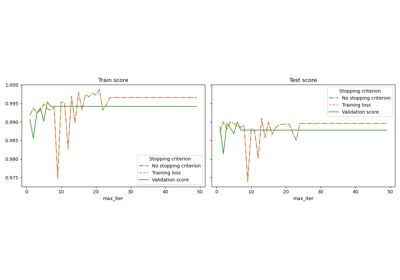
shuffle#
- sklearn.utils.shuffle(*arrays, random_state=None, n_samples=None)[source]#
以一致的方式打乱数组或稀疏矩阵。
这是
resample(*arrays, replace=False)的一个便利别名,用于对集合进行随机排列。- 参数:
- *arrays可索引数据结构的序列
可索引数据结构可以是数组、列表、数据框或第一维一致的scipy稀疏矩阵。
- random_stateint, RandomState instance or None, default=None
确定用于打乱数据的随机数生成器。传入一个整数可以在多次函数调用中获得可重现的结果。参见 词汇表。
- n_samplesint, default=None
要生成的样本数量。如果设置为None,则自动设置为数组的第一维大小。它不应大于数组的长度。
- 返回:
- shuffled_arrays可索引数据结构的序列
集合的打乱副本序列。原始数组不受影响。
另请参阅
resample以一致的方式重新采样数组或稀疏矩阵。
示例
可以在同一次运行中混合使用稀疏数组和密集数组
>>> import numpy as np >>> X = np.array([[1., 0.], [2., 1.], [0., 0.]]) >>> y = np.array([0, 1, 2]) >>> from scipy.sparse import coo_matrix >>> X_sparse = coo_matrix(X) >>> from sklearn.utils import shuffle >>> X, X_sparse, y = shuffle(X, X_sparse, y, random_state=0) >>> X array([[0., 0.], [2., 1.], [1., 0.]]) >>> X_sparse <Compressed Sparse Row sparse matrix of dtype 'float64' with 3 stored elements and shape (3, 2)> >>> X_sparse.toarray() array([[0., 0.], [2., 1.], [1., 0.]]) >>> y array([2, 1, 0]) >>> shuffle(y, n_samples=2, random_state=0) array([0, 1])