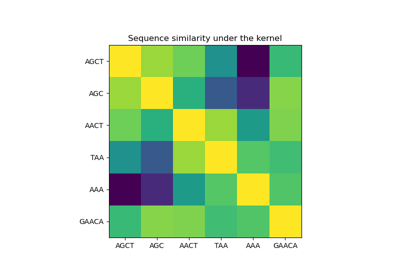
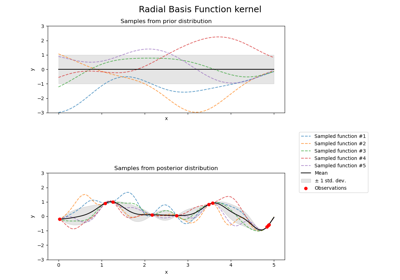
GaussianProcessRegressor#
- class sklearn.gaussian_process.GaussianProcessRegressor(kernel=None, *, alpha=1e-10, optimizer='fmin_l_bfgs_b', n_restarts_optimizer=0, normalize_y=False, copy_X_train=True, n_targets=None, random_state=None)[source]#
高斯过程回归(GPR)。
该实现基于[RW2006]的算法2.1。
除了标准的scikit-learn估计器API,
GaussianProcessRegressor允许在未拟合之前进行预测(基于GP先验)
提供一个额外的方法
sample_y(X),用于评估从GPR(先验或后验)中抽取并在给定输入处采样的样本公开一个方法
log_marginal_likelihood(theta),该方法可用于外部的其他超参数选择方式,例如通过马尔可夫链蒙特卡洛。
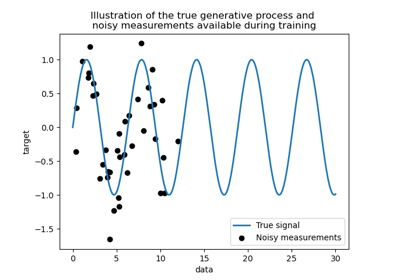
要了解点估计方法与更贝叶斯建模方法之间的区别,请参阅名为核岭回归与高斯过程回归的比较的示例。
在用户指南中阅读更多内容。
新增于版本0.18。
- 参数:
- kernel核实例,默认值=None
指定GP协方差函数的核。如果传入None,则默认使用核
ConstantKernel(1.0, constant_value_bounds="fixed") * RBF(1.0, length_scale_bounds="fixed")。请注意,除非边界被标记为“fixed”,否则核超参数将在拟合过程中进行优化。- alpha浮点数或形状为(n_samples,)的ndarray,默认值=1e-10
在拟合过程中添加到核矩阵对角线的值。这可以通过确保计算出的值形成一个正定矩阵来防止拟合过程中潜在的数值问题。它也可以解释为训练观测值上额外高斯测量噪声的方差。请注意,这与使用
WhiteKernel不同。如果传入一个数组,它的条目数量必须与用于拟合的数据相同,并用作数据点相关的噪声水平。允许直接将噪声水平指定为参数主要是为了方便,并与Ridge保持一致。有关说明alpha参数如何控制高斯过程回归中噪声方差的示例,请参阅高斯过程回归:基本入门示例。- optimizer“fmin_l_bfgs_b”,可调用对象或None,默认值=“fmin_l_bfgs_b”
可以是内部支持的用于优化核参数的优化器之一(通过字符串指定),也可以是作为可调用对象传入的外部定义优化器。如果传入可调用对象,它必须具有以下签名
def optimizer(obj_func, initial_theta, bounds): # * 'obj_func': the objective function to be minimized, which # takes the hyperparameters theta as a parameter and an # optional flag eval_gradient, which determines if the # gradient is returned additionally to the function value # * 'initial_theta': the initial value for theta, which can be # used by local optimizers # * 'bounds': the bounds on the values of theta .... # Returned are the best found hyperparameters theta and # the corresponding value of the target function. return theta_opt, func_min
默认情况下,使用
scipy.optimize.minimize中的L-BFGS-B算法。如果传入None,则核参数保持固定。可用的内部优化器有:{'fmin_l_bfgs_b'}。- n_restarts_optimizer整型,默认值=0
优化器重启的次数,用于寻找最大化对数边缘似然的核参数。优化器的第一次运行从核的初始参数开始,其余的(如果有)从允许的theta值空间中对数均匀随机采样的theta值开始。如果大于0,所有边界必须是有限的。请注意,
n_restarts_optimizer == 0意味着执行一次运行。- normalize_y布尔值,默认值=False
是否通过去除均值和缩放到单位方差来归一化目标值
y。这对于使用零均值、单位方差先验的情况是推荐的。请注意,在此实现中,归一化在报告GP预测之前会被反转。版本0.23中已更改。
- copy_X_train布尔值,默认值=True
如果为True,则训练数据的持久副本存储在对象中。否则,只存储训练数据的引用,如果数据在外部被修改,这可能会导致预测发生变化。
- n_targets整型,默认值=None
目标值的维度数量。用于在从先验分布采样时(即在调用
sample_y之前调用fit)决定输出数量。一旦调用fit,此参数将被忽略。新增于版本1.3。
- random_state整型,RandomState实例或None,默认值=None
确定用于初始化中心的随机数生成。传入一个整型以在多次函数调用中获得可重现的结果。参见术语表。
- 属性:
- X_train_形状为(n_samples, n_features)的类数组或对象列表
训练数据的特征向量或其他表示(预测也需要)。
- y_train_形状为(n_samples,)或(n_samples, n_targets)的类数组
训练数据中的目标值(预测也需要)。
- kernel_核实例
用于预测的核。核的结构与作为参数传入的核相同,但具有优化的超参数。
- L_形状为(n_samples, n_samples)的类数组
X_train_中核的下三角乔利斯基分解。- alpha_形状为(n_samples,)的类数组
核空间中训练数据点的对偶系数。
- log_marginal_likelihood_value_浮点数
self.kernel_.theta的对数边缘似然值。- n_features_in_整型
在拟合期间看到的特征数量。
新增于版本0.24。
- feature_names_in_形状为(
n_features_in_,)的ndarray 在拟合期间看到的特征名称。仅当
X的特征名称全部为字符串时才定义。新增于版本1.0。
另请参阅
GaussianProcessClassifier基于拉普拉斯近似的高斯过程分类(GPC)。
参考文献
示例
>>> from sklearn.datasets import make_friedman2 >>> from sklearn.gaussian_process import GaussianProcessRegressor >>> from sklearn.gaussian_process.kernels import DotProduct, WhiteKernel >>> X, y = make_friedman2(n_samples=500, noise=0, random_state=0) >>> kernel = DotProduct() + WhiteKernel() >>> gpr = GaussianProcessRegressor(kernel=kernel, ... random_state=0).fit(X, y) >>> gpr.score(X, y) 0.3680... >>> gpr.predict(X[:2,:], return_std=True) (array([653.0, 592.1]), array([316.6, 316.6]))
- fit(X, y)[source]#
拟合高斯过程回归模型。
- 参数:
- X形状为(n_samples, n_features)的类数组或对象列表
训练数据的特征向量或其他表示。
- y形状为(n_samples,)或(n_samples, n_targets)的类数组
目标值。
- 返回:
- self对象
GaussianProcessRegressor类实例。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看用户指南了解路由机制的工作原理。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deep布尔值,默认值=True
如果为True,将返回此估计器及其包含的作为估计器的子对象的参数。
- 返回:
- params字典
参数名称映射到其值。
- log_marginal_likelihood(theta=None, eval_gradient=False, clone_kernel=True)[source]#
返回训练数据中theta的对数边缘似然。
- 参数:
- theta形状为(n_kernel_params,)的类数组,默认值=None
评估对数边缘似然的核超参数。如果为None,则返回
self.kernel_.theta的预计算对数边缘似然。- eval_gradient布尔值,默认值=False
如果为True,则额外返回对数边缘似然相对于theta位置的核超参数的梯度。如果为True,theta不能为None。
- clone_kernel布尔值,默认值=True
如果为True,则复制核属性。如果为False,则修改核属性,但这可能会带来性能提升。
- 返回:
- log_likelihood浮点数
训练数据中theta的对数边缘似然。
- log_likelihood_gradient形状为(n_kernel_params,)的ndarray,可选
对数边缘似然相对于theta位置的核超参数的梯度。仅当eval_gradient为True时返回。
- predict(X, return_std=False, return_cov=False)[source]#
使用高斯过程回归模型进行预测。
我们也可以使用GP先验,基于未拟合的模型进行预测。除了预测分布的均值,还可以选择性地返回其标准差(
return_std=True)或协方差(return_cov=True)。请注意,最多只能请求两者之一。- 参数:
- X形状为(n_samples, n_features)的类数组或对象列表
评估GP的查询点。
- return_std布尔值,默认值=False
如果为True,则查询点处预测分布的标准差将与均值一起返回。
- return_cov布尔值,默认值=False
如果为True,则查询点处联合预测分布的协方差将与均值一起返回。
- 返回:
- y_mean形状为(n_samples,)或(n_samples, n_targets)的ndarray
查询点处预测分布的均值。
- y_std形状为(n_samples,)或(n_samples, n_targets)的ndarray,可选
查询点处预测分布的标准差。仅当
return_std为True时返回。- y_cov形状为(n_samples, n_samples)或(n_samples, n_samples, n_targets)的ndarray,可选
查询点处联合预测分布的协方差。仅当
return_cov为True时返回。
- sample_y(X, n_samples=1, random_state=0)[source]#
从高斯过程中抽取样本并在X处评估。
- 参数:
- X形状为(n_samples_X, n_features)的类数组或对象列表
评估GP的查询点。
- n_samples整型,默认值=1
每个查询点从高斯过程抽取的样本数量。
- random_state整型,RandomState实例或None,默认值=0
确定用于随机抽取样本的随机数生成。传入一个整型以在多次函数调用中获得可重现的结果。参见术语表。
- 返回:
- y_samples形状为(n_samples_X, n_samples)或(n_samples_X, n_targets, n_samples)的ndarray
从高斯过程抽取并在查询点评估的n_samples个样本的值。
- score(X, y, sample_weight=None)[source]#
返回测试数据上的决定系数。
决定系数 \(R^2\) 定义为 \((1 - \frac{u}{v})\),其中 \(u\) 是残差平方和
((y_true - y_pred)** 2).sum(),\(v\) 是总平方和((y_true - y_true.mean()) ** 2).sum()。最佳得分是1.0,它也可以是负数(因为模型可能任意地差)。一个总是预测y期望值而不考虑输入特征的常数模型,将获得\(R^2\)得分为0.0。- 参数:
- X形状为(n_samples, n_features)的类数组
测试样本。对于某些估计器,这可能是一个预计算的核矩阵或一个通用对象列表,形状为
(n_samples, n_samples_fitted),其中n_samples_fitted是用于估计器拟合的样本数量。- y形状为(n_samples,)或(n_samples, n_outputs)的类数组
X的真实值。- sample_weight形状为(n_samples,)的类数组,默认值=None
样本权重。
- 返回:
- score浮点数
self.predict(X)相对于y的\(R^2\)。
注意事项
在对回归器调用
score时使用的\(R^2\)分数,从0.23版本开始使用multioutput='uniform_average',以与r2_score的默认值保持一致。这影响了所有多输出回归器(除了MultiOutputRegressor)的score方法。
- set_params(**params)[source]#
设置此估计器的参数。
该方法适用于简单的估计器以及嵌套对象(如
Pipeline)。后者具有<component>__<parameter>形式的参数,因此可以更新嵌套对象的每个组件。- 参数:
- **params字典
估计器参数。
- 返回:
- self估计器实例
估计器实例。
- set_predict_request(*, return_cov: bool | None | str = '$UNCHANGED$', return_std: bool | None | str = '$UNCHANGED$') GaussianProcessRegressor[source]#
请求传递给
predict方法的元数据。请注意,此方法仅在
enable_metadata_routing=True时相关(参见sklearn.set_config)。请参阅用户指南了解路由机制的工作原理。每个参数的选项有
True:请求元数据,如果提供则传递给predict。如果未提供元数据,则忽略请求。False:不请求元数据,元估计器不会将其传递给predict。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:元数据应以这个给定别名而不是原始名称传递给元估计器。
默认值(
sklearn.utils.metadata_routing.UNCHANGED)保留现有请求。这允许您更改某些参数的请求而不更改其他参数。新增于版本1.3。
注意
此方法仅当此估计器用作元估计器的子估计器时才相关,例如在
Pipeline内部使用。否则它不起作用。- 参数:
- return_covstr, True, False, 或 None,默认值=sklearn.utils.metadata_routing.UNCHANGED
predict方法中return_cov参数的元数据路由。- return_stdstr, True, False, 或 None,默认值=sklearn.utils.metadata_routing.UNCHANGED
predict方法中return_std参数的元数据路由。
- 返回:
- self对象
更新后的对象。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') GaussianProcessRegressor[source]#
请求传递给
score方法的元数据。请注意,此方法仅在
enable_metadata_routing=True时相关(参见sklearn.set_config)。请参阅用户指南了解路由机制的工作原理。每个参数的选项有
True:请求元数据,如果提供则传递给score。如果未提供元数据,则忽略请求。False:不请求元数据,元估计器不会将其传递给score。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:元数据应以这个给定别名而不是原始名称传递给元估计器。
默认值(
sklearn.utils.metadata_routing.UNCHANGED)保留现有请求。这允许您更改某些参数的请求而不更改其他参数。新增于版本1.3。
注意
此方法仅当此估计器用作元估计器的子估计器时才相关,例如在
Pipeline内部使用。否则它不起作用。- 参数:
- sample_weightstr, True, False, 或 None,默认值=sklearn.utils.metadata_routing.UNCHANGED
score方法中sample_weight参数的元数据路由。
- 返回:
- self对象
更新后的对象。