注意
转到末尾以下载完整示例代码或通过JupyterLite或Binder在浏览器中运行此示例。
使用高斯过程回归(GPR)预测Mona Loa数据集上的CO2水平#
此示例基于《高斯过程用于机器学习》一书的第5.4.3节[1]。它演示了复杂的核函数工程和超参数优化,使用对数边际似然上的梯度上升法。数据包含在夏威夷莫纳罗亚天文台(Mauna Loa Observatory)收集的1958年至2001年间的月平均大气CO2浓度(百万分之几,ppm)。目标是建立CO2浓度随时间 \(t\) 变化的模型,并对2001年以后的年份进行外推。
References
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
构建数据集#
我们将从收集空气样本的莫纳罗亚天文台获取数据集。我们有兴趣估计CO2浓度并对其未来年份进行外推。首先,我们加载OpenML中可用的原始数据集作为pandas数据框。一旦fetch_openml增加了对Polars的原生支持,它将被替换为Polars。
from sklearn.datasets import fetch_openml
co2 = fetch_openml(data_id=41187, as_frame=True)
co2.frame.head()
首先,我们处理原始数据框以创建日期列,并将其与CO2列一起选择。
import polars as pl
co2_data = pl.DataFrame(co2.frame[["year", "month", "day", "co2"]]).select(
pl.date("year", "month", "day"), "co2"
)
co2_data.head()
co2_data["date"].min(), co2_data["date"].max()
(datetime.date(1958, 3, 29), datetime.date(2001, 12, 29))
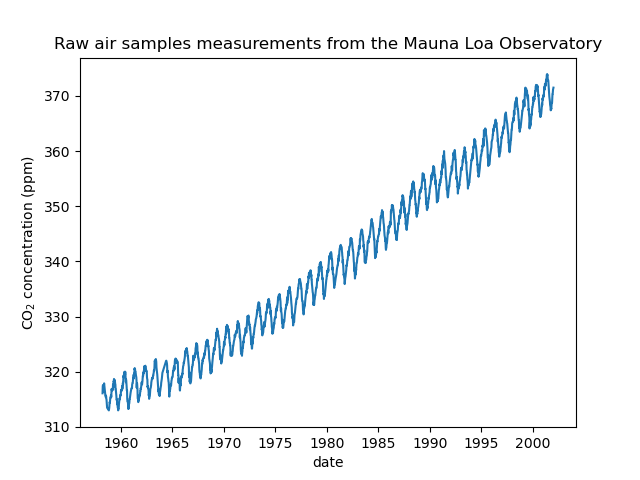
我们看到我们获得了从1958年3月到2001年12月某些日期的CO2浓度。我们可以绘制原始信息以获得更好的理解。
import matplotlib.pyplot as plt
plt.plot(co2_data["date"], co2_data["co2"])
plt.xlabel("date")
plt.ylabel("CO$_2$ concentration (ppm)")
_ = plt.title("Raw air samples measurements from the Mauna Loa Observatory")
我们将通过取月平均值并删除没有测量值的月份来预处理数据集。这种处理将对数据产生平滑效果。
co2_data = (
co2_data.sort(by="date")
.group_by_dynamic("date", every="1mo")
.agg(pl.col("co2").mean())
.drop_nulls()
)
plt.plot(co2_data["date"], co2_data["co2"])
plt.xlabel("date")
plt.ylabel("Monthly average of CO$_2$ concentration (ppm)")
_ = plt.title(
"Monthly average of air samples measurements\nfrom the Mauna Loa Observatory"
)
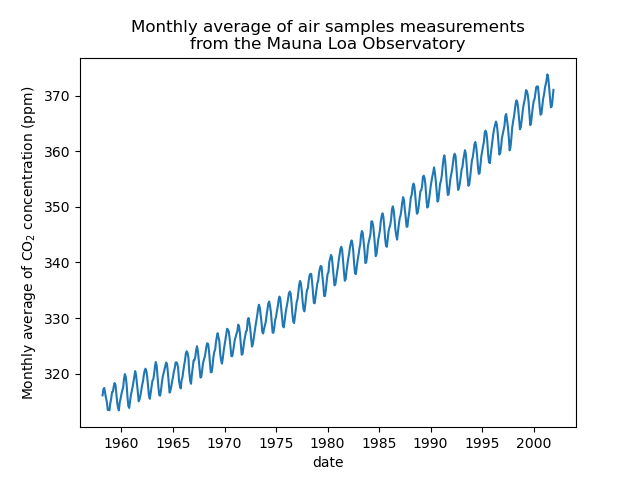
本例中的想法是根据日期预测CO2浓度。我们也有兴趣对2001年之后的年份进行外推。
第一步,我们将划分数据和要估计的目标。数据是日期,我们将它转换为数值。
X = co2_data.select(
pl.col("date").dt.year() + pl.col("date").dt.month() / 12
).to_numpy()
y = co2_data["co2"].to_numpy()
设计合适的核函数#
为了设计用于高斯过程的核函数,我们可以对手头的数据做一些假设。我们观察到它们具有几个特征:我们看到一个长期上升趋势、一个明显的季节性变化和一些较小的不规则性。我们可以使用不同的合适核函数来捕获这些特征。
首先,长期上升趋势可以使用具有大长度尺度参数的径向基函数(RBF)核函数来拟合。具有大长度尺度的RBF核函数强制此分量平滑。不强制要求趋势增加,以赋予模型一定的自由度。特定的长度尺度和幅度是自由超参数。
季节性变化由周期性指数正弦平方核函数解释,其固定周期为1年。此周期性分量的长度尺度控制其平滑度,是一个自由参数。为了允许偏离精确周期性而衰减,我们将其与RBF核函数相乘。此RBF分量的长度尺度控制衰减时间,是另一个自由参数。这种类型的核函数也称为局部周期性核函数。
from sklearn.gaussian_process.kernels import ExpSineSquared
seasonal_kernel = (
2.0**2
* RBF(length_scale=100.0)
* ExpSineSquared(length_scale=1.0, periodicity=1.0, periodicity_bounds="fixed")
)
较小的不规则性由有理二次核函数分量解释,其长度尺度和alpha参数(量化长度尺度的扩散性)待确定。有理二次核函数等同于具有多个长度尺度的RBF核函数,将更好地适应不同的不规则性。
from sklearn.gaussian_process.kernels import RationalQuadratic
irregularities_kernel = 0.5**2 * RationalQuadratic(length_scale=1.0, alpha=1.0)
最后,数据集中的噪声可以使用由RBF核函数贡献(应解释局部天气现象等相关噪声分量)和白核函数贡献(用于白噪声)组成的核函数来解释。相对幅度和RBF的长度尺度是进一步的自由参数。
from sklearn.gaussian_process.kernels import WhiteKernel
noise_kernel = 0.1**2 * RBF(length_scale=0.1) + WhiteKernel(
noise_level=0.1**2, noise_level_bounds=(1e-5, 1e5)
)
因此,我们最终的核函数是所有先前核函数的相加。
co2_kernel = (
long_term_trend_kernel + seasonal_kernel + irregularities_kernel + noise_kernel
)
co2_kernel
50**2 * RBF(length_scale=50) + 2**2 * RBF(length_scale=100) * ExpSineSquared(length_scale=1, periodicity=1) + 0.5**2 * RationalQuadratic(alpha=1, length_scale=1) + 0.1**2 * RBF(length_scale=0.1) + WhiteKernel(noise_level=0.01)
模型拟合和外推#
现在,我们准备好使用高斯过程回归器并拟合可用数据。为了遵循文献中的示例,我们将从目标中减去平均值。我们可以使用normalize_y=True。然而,这样做也会缩放目标(将y除以其标准差)。因此,不同核函数的超参数将具有不同的含义,因为它们将不再以ppm表示。
from sklearn.gaussian_process import GaussianProcessRegressor
y_mean = y.mean()
gaussian_process = GaussianProcessRegressor(kernel=co2_kernel, normalize_y=False)
gaussian_process.fit(X, y - y_mean)
现在,我们将使用高斯过程来预测:
训练数据以检查拟合优度;
未来数据以查看模型所做的外推。
因此,我们创建从1958年到当前月份的合成数据。此外,我们需要添加在训练期间计算的减去的均值。
import datetime
import numpy as np
today = datetime.datetime.now()
current_month = today.year + today.month / 12
X_test = np.linspace(start=1958, stop=current_month, num=1_000).reshape(-1, 1)
mean_y_pred, std_y_pred = gaussian_process.predict(X_test, return_std=True)
mean_y_pred += y_mean
plt.plot(X, y, color="black", linestyle="dashed", label="Measurements")
plt.plot(X_test, mean_y_pred, color="tab:blue", alpha=0.4, label="Gaussian process")
plt.fill_between(
X_test.ravel(),
mean_y_pred - std_y_pred,
mean_y_pred + std_y_pred,
color="tab:blue",
alpha=0.2,
)
plt.legend()
plt.xlabel("Year")
plt.ylabel("Monthly average of CO$_2$ concentration (ppm)")
_ = plt.title(
"Monthly average of air samples measurements\nfrom the Mauna Loa Observatory"
)
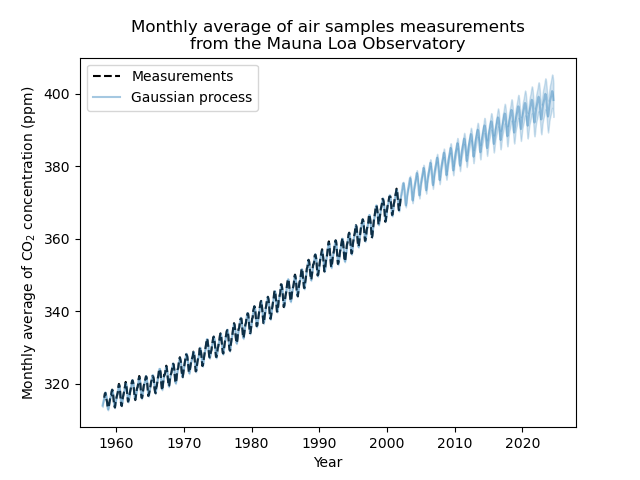
我们拟合的模型能够很好地拟合先前的数据,并自信地外推到未来年份。
核函数超参数的解释#
现在,我们可以看看核函数的超参数。
gaussian_process.kernel_
44.8**2 * RBF(length_scale=51.6) + 2.64**2 * RBF(length_scale=91.5) * ExpSineSquared(length_scale=1.48, periodicity=1) + 0.536**2 * RationalQuadratic(alpha=2.89, length_scale=0.968) + 0.188**2 * RBF(length_scale=0.122) + WhiteKernel(noise_level=0.0367)
因此,减去均值后的大部分目标信号由一个~45 ppm的长期上升趋势和~52年的长度尺度解释。周期性分量的幅度为~2.6 ppm,衰减时间为~90年,长度尺度为~1.5。长的衰减时间表明我们有一个非常接近季节性周期的分量。相关噪声的幅度为~0.2 ppm,长度尺度为~0.12年,白噪声贡献为~0.04 ppm。因此,总体噪声水平非常小,表明数据可以很好地由模型解释。
脚本总运行时间: (0 minutes 3.994 seconds)
相关示例