注意
转到末尾以下载完整的示例代码或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
目标编码器(Target Encoder)的内部交叉拟合#
TargetEncoder 将分类特征的每个类别替换为该类别目标变量的收缩均值。当分类特征与目标之间存在强关系时,此方法非常有用。为了防止过拟合,TargetEncoder.fit_transform 使用内部交叉拟合方案对训练数据进行编码,以供下游模型使用。此方案涉及将数据分成 k 折,并使用从 其他 k-1 折中学习到的编码对每一折进行编码。在此示例中,我们将演示交叉拟合过程对防止过拟合的重要性。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
创建合成数据集#
在此示例中,我们构建了一个包含三个分类特征的数据集
一个中等基数的信息特征(“informative”)
一个中等基数的非信息特征(“shuffled”)
一个高基数的非信息特征(“near_unique”)
首先,我们生成信息特征
import numpy as np
from sklearn.preprocessing import KBinsDiscretizer
n_samples = 50_000
rng = np.random.RandomState(42)
y = rng.randn(n_samples)
noise = 0.5 * rng.randn(n_samples)
n_categories = 100
kbins = KBinsDiscretizer(
n_bins=n_categories,
encode="ordinal",
strategy="uniform",
random_state=rng,
subsample=None,
)
X_informative = kbins.fit_transform((y + noise).reshape(-1, 1))
# Remove the linear relationship between y and the bin index by permuting the
# values of X_informative:
permuted_categories = rng.permutation(n_categories)
X_informative = permuted_categories[X_informative.astype(np.int32)]
中等基数的非信息特征是通过置换信息特征并消除与目标的关系来生成的
X_shuffled = rng.permutation(X_informative)
生成高基数的非信息特征,使其独立于目标变量。我们将展示,没有交叉拟合的目标编码将导致下游回归器出现灾难性的过拟合。这些高基数特征基本上是样本的唯一标识符,通常应从机器学习数据集中删除。在此示例中,我们生成它们是为了展示TargetEncoder的默认交叉拟合行为如何自动缓解过拟合问题。
X_near_unique_categories = rng.choice(
int(0.9 * n_samples), size=n_samples, replace=True
).reshape(-1, 1)
最后,我们组装数据集并执行训练测试拆分
import pandas as pd
from sklearn.model_selection import train_test_split
X = pd.DataFrame(
np.concatenate(
[X_informative, X_shuffled, X_near_unique_categories],
axis=1,
),
columns=["informative", "shuffled", "near_unique"],
)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
训练岭回归器#
在此部分中,我们将在有和没有编码的数据集上训练岭回归器,并探讨有和没有内部交叉拟合的目标编码器的影响。首先,我们看到在原始特征上训练的岭模型性能较低。这是因为我们打乱了信息特征的顺序,这意味着当原始特征时,X_informative 不具有信息性
import sklearn
from sklearn.linear_model import Ridge
# Configure transformers to always output DataFrames
sklearn.set_config(transform_output="pandas")
ridge = Ridge(alpha=1e-6, solver="lsqr", fit_intercept=False)
raw_model = ridge.fit(X_train, y_train)
print("Raw Model score on training set: ", raw_model.score(X_train, y_train))
print("Raw Model score on test set: ", raw_model.score(X_test, y_test))
Raw Model score on training set: 0.0049896314219657345
Raw Model score on test set: 0.0045776215814927745
接下来,我们使用目标编码器和岭模型创建一个管道。该管道使用TargetEncoder.fit_transform,它使用交叉拟合。我们看到模型很好地拟合了数据并推广到测试集
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import TargetEncoder
model_with_cf = make_pipeline(TargetEncoder(random_state=0), ridge)
model_with_cf.fit(X_train, y_train)
print("Model with CF on train set: ", model_with_cf.score(X_train, y_train))
print("Model with CF on test set: ", model_with_cf.score(X_test, y_test))
Model with CF on train set: 0.8000184677460304
Model with CF on test set: 0.7927845601690917
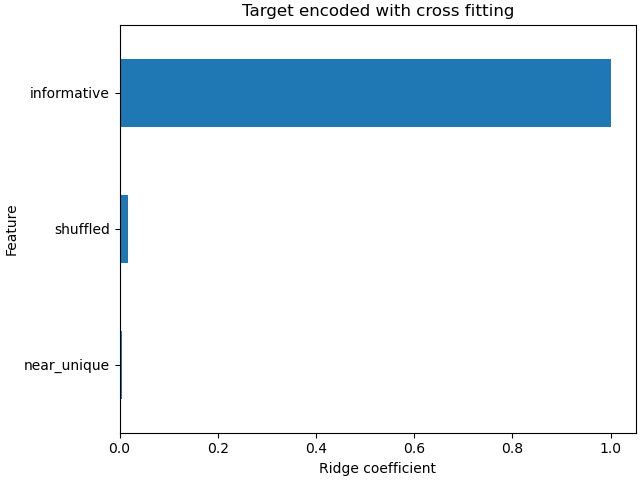
线性模型的系数表明,大部分权重都在列索引0处的特征上,这是信息特征
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams["figure.constrained_layout.use"] = True
coefs_cf = pd.Series(
model_with_cf[-1].coef_, index=model_with_cf[-1].feature_names_in_
).sort_values()
ax = coefs_cf.plot(kind="barh")
_ = ax.set(
title="Target encoded with cross fitting",
xlabel="Ridge coefficient",
ylabel="Feature",
)
尽管TargetEncoder.fit_transform使用内部交叉拟合方案来学习训练集的编码,但TargetEncoder.fit后接TargetEncoder.transform则不使用。它使用完整的训练集来学习编码和转换分类特征。因此,我们可以使用TargetEncoder.fit后接TargetEncoder.transform来禁用交叉拟合。然后将此编码传递给岭模型。
target_encoder = TargetEncoder(random_state=0)
target_encoder.fit(X_train, y_train)
X_train_no_cf_encoding = target_encoder.transform(X_train)
X_test_no_cf_encoding = target_encoder.transform(X_test)
model_no_cf = ridge.fit(X_train_no_cf_encoding, y_train)
我们评估了在编码时未使用交叉拟合的模型,发现它过拟合了
print(
"Model without CF on training set: ",
model_no_cf.score(X_train_no_cf_encoding, y_train),
)
print(
"Model without CF on test set: ",
model_no_cf.score(
X_test_no_cf_encoding,
y_test,
),
)
Model without CF on training set: 0.858486250088675
Model without CF on test set: 0.6338211367102257
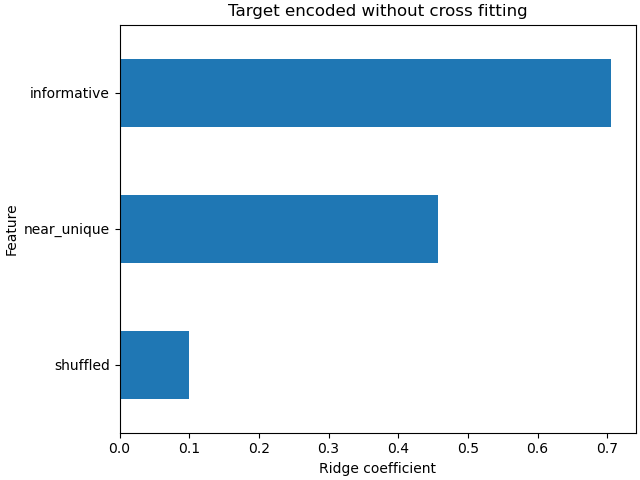
岭模型过拟合是因为它赋予了无信息性极高基数(“near_unique”)和中等基数(“shuffled”)特征的权重远大于模型使用交叉拟合对特征进行编码时。
coefs_no_cf = pd.Series(
model_no_cf.coef_, index=model_no_cf.feature_names_in_
).sort_values()
ax = coefs_no_cf.plot(kind="barh")
_ = ax.set(
title="Target encoded without cross fitting",
xlabel="Ridge coefficient",
ylabel="Feature",
)
结论#
此示例演示了TargetEncoder内部交叉拟合的重要性。在将训练数据传递给机器学习模型之前,使用TargetEncoder.fit_transform进行编码非常重要。当TargetEncoder是Pipeline的一部分并且管道已拟合时,管道将正确调用TargetEncoder.fit_transform并在编码训练数据时使用交叉拟合。
脚本总运行时间:(0分钟0.312秒)
相关示例