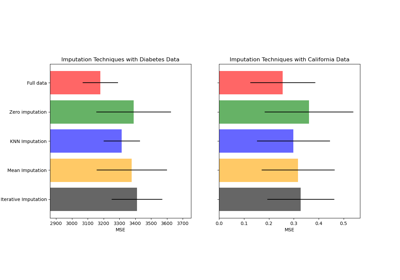
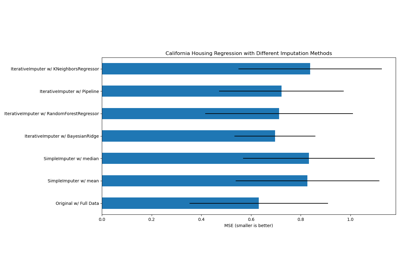
缺失值填充# 关于sklearn.impute模块的示例。 在构建估计器之前填充缺失值 在构建估计器之前填充缺失值 使用IterativeImputer的变体填充缺失值 使用IterativeImputer的变体填充缺失值