注意
转到末尾 下载完整示例代码。或通过 JupyterLite 或 Binder 在浏览器中运行此示例
RBF 核的显式特征图近似#
一个示例,说明了 RBF 核特征图的近似。
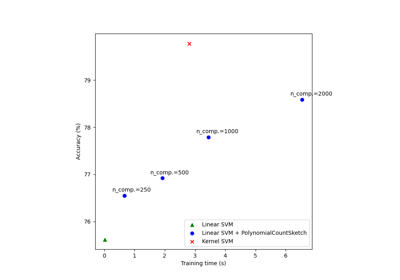
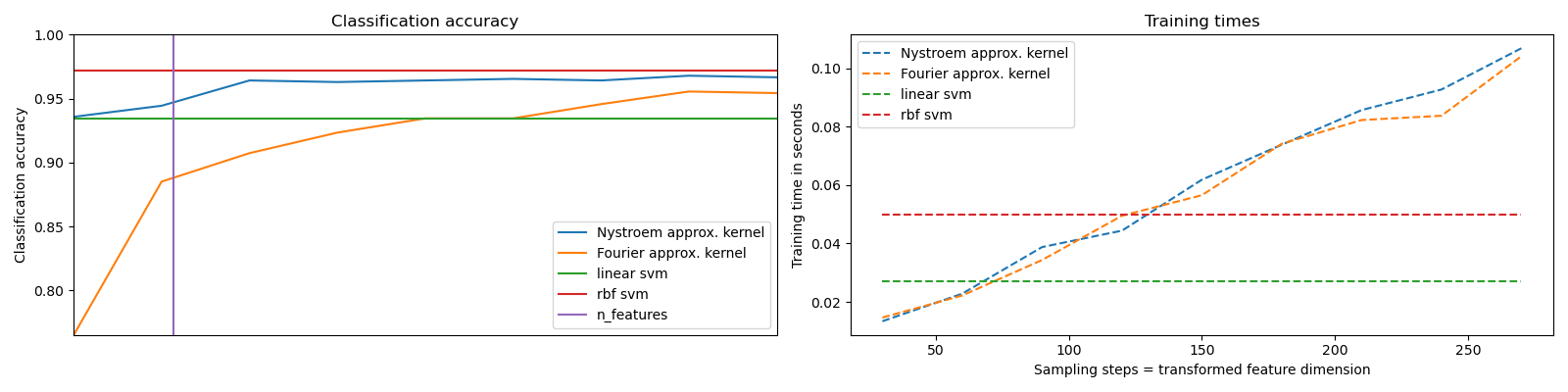
它展示了如何使用 RBFSampler 和 Nystroem 在数字数据集上使用 SVM 进行分类时,近似 RBF 核的特征映射。比较了在原始空间中使用线性 SVM、使用近似映射的线性 SVM 以及使用核化 SVM 的结果。显示了不同蒙特卡洛采样量(对于 RBFSampler,它使用随机傅里叶特征)和不同大小的训练子集(对于 Nystroem)的近似映射的时序和准确性。
请注意,此处的数据集不够大,无法显示核近似的优势,因为精确 SVM 仍然相当快。
采样更多的维度显然能带来更好的分类结果,但代价也更大。这意味着在运行时和准确性之间存在权衡,这由参数 n_components 决定。请注意,通过使用随机梯度下降,线性 SVM 和近似核 SVM 的求解速度都可以大大加快,具体可通过 SGDClassifier 实现。对于核化 SVM 的情况,这不容易实现。
Python 包和数据集导入,加载数据集#
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
# Standard scientific Python imports
from time import time
import matplotlib.pyplot as plt
import numpy as np
# Import datasets, classifiers and performance metrics
from sklearn import datasets, pipeline, svm
from sklearn.decomposition import PCA
from sklearn.kernel_approximation import Nystroem, RBFSampler
# The digits dataset
digits = datasets.load_digits(n_class=9)
时序和准确性图#
要在此数据上应用分类器,我们需要将图像展平,将数据转换为 (样本数, 特征数) 矩阵
n_samples = len(digits.data)
data = digits.data / 16.0
data -= data.mean(axis=0)
# We learn the digits on the first half of the digits
data_train, targets_train = (data[: n_samples // 2], digits.target[: n_samples // 2])
# Now predict the value of the digit on the second half:
data_test, targets_test = (data[n_samples // 2 :], digits.target[n_samples // 2 :])
# data_test = scaler.transform(data_test)
# Create a classifier: a support vector classifier
kernel_svm = svm.SVC(gamma=0.2)
linear_svm = svm.LinearSVC(random_state=42)
# create pipeline from kernel approximation
# and linear svm
feature_map_fourier = RBFSampler(gamma=0.2, random_state=1)
feature_map_nystroem = Nystroem(gamma=0.2, random_state=1)
fourier_approx_svm = pipeline.Pipeline(
[
("feature_map", feature_map_fourier),
("svm", svm.LinearSVC(random_state=42)),
]
)
nystroem_approx_svm = pipeline.Pipeline(
[
("feature_map", feature_map_nystroem),
("svm", svm.LinearSVC(random_state=42)),
]
)
# fit and predict using linear and kernel svm:
kernel_svm_time = time()
kernel_svm.fit(data_train, targets_train)
kernel_svm_score = kernel_svm.score(data_test, targets_test)
kernel_svm_time = time() - kernel_svm_time
linear_svm_time = time()
linear_svm.fit(data_train, targets_train)
linear_svm_score = linear_svm.score(data_test, targets_test)
linear_svm_time = time() - linear_svm_time
sample_sizes = 30 * np.arange(1, 10)
fourier_scores = []
nystroem_scores = []
fourier_times = []
nystroem_times = []
for D in sample_sizes:
fourier_approx_svm.set_params(feature_map__n_components=D)
nystroem_approx_svm.set_params(feature_map__n_components=D)
start = time()
nystroem_approx_svm.fit(data_train, targets_train)
nystroem_times.append(time() - start)
start = time()
fourier_approx_svm.fit(data_train, targets_train)
fourier_times.append(time() - start)
fourier_score = fourier_approx_svm.score(data_test, targets_test)
nystroem_score = nystroem_approx_svm.score(data_test, targets_test)
nystroem_scores.append(nystroem_score)
fourier_scores.append(fourier_score)
# plot the results:
plt.figure(figsize=(16, 4))
accuracy = plt.subplot(121)
# second y axis for timings
timescale = plt.subplot(122)
accuracy.plot(sample_sizes, nystroem_scores, label="Nystroem approx. kernel")
timescale.plot(sample_sizes, nystroem_times, "--", label="Nystroem approx. kernel")
accuracy.plot(sample_sizes, fourier_scores, label="Fourier approx. kernel")
timescale.plot(sample_sizes, fourier_times, "--", label="Fourier approx. kernel")
# horizontal lines for exact rbf and linear kernels:
accuracy.plot(
[sample_sizes[0], sample_sizes[-1]],
[linear_svm_score, linear_svm_score],
label="linear svm",
)
timescale.plot(
[sample_sizes[0], sample_sizes[-1]],
[linear_svm_time, linear_svm_time],
"--",
label="linear svm",
)
accuracy.plot(
[sample_sizes[0], sample_sizes[-1]],
[kernel_svm_score, kernel_svm_score],
label="rbf svm",
)
timescale.plot(
[sample_sizes[0], sample_sizes[-1]],
[kernel_svm_time, kernel_svm_time],
"--",
label="rbf svm",
)
# vertical line for dataset dimensionality = 64
accuracy.plot([64, 64], [0.7, 1], label="n_features")
# legends and labels
accuracy.set_title("Classification accuracy")
timescale.set_title("Training times")
accuracy.set_xlim(sample_sizes[0], sample_sizes[-1])
accuracy.set_xticks(())
accuracy.set_ylim(np.min(fourier_scores), 1)
timescale.set_xlabel("Sampling steps = transformed feature dimension")
accuracy.set_ylabel("Classification accuracy")
timescale.set_ylabel("Training time in seconds")
accuracy.legend(loc="best")
timescale.legend(loc="best")
plt.tight_layout()
plt.show()
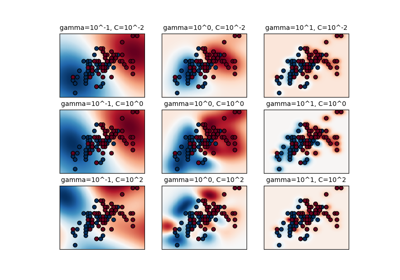
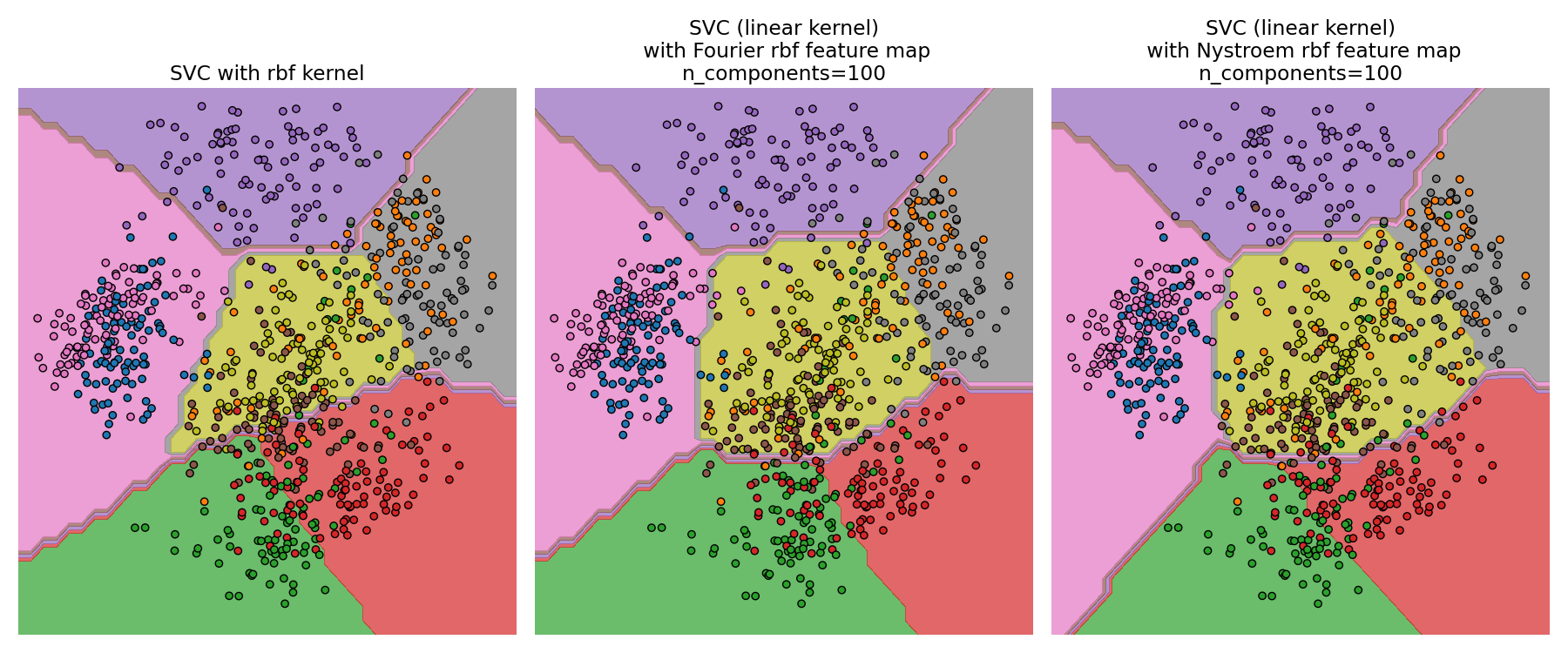
RBF 核 SVM 和线性 SVM 的决策边界#
第二个图可视化了 RBF 核 SVM 和带近似核映射的线性 SVM 的决策边界。该图显示了分类器的决策边界,这些边界被投影到数据的前两个主成分上。这种可视化需要谨慎对待,因为它只是 64 维决策边界的一个有趣切片。特别要注意的是,一个数据点(表示为一个点)不一定会被分类到其所在的区域,因为它不会位于前两个主成分所张成的平面上。RBFSampler 和 Nystroem 的使用在 核近似 中详细描述。
# visualize the decision surface, projected down to the first
# two principal components of the dataset
pca = PCA(n_components=8, random_state=42).fit(data_train)
X = pca.transform(data_train)
# Generate grid along first two principal components
multiples = np.arange(-2, 2, 0.1)
# steps along first component
first = multiples[:, np.newaxis] * pca.components_[0, :]
# steps along second component
second = multiples[:, np.newaxis] * pca.components_[1, :]
# combine
grid = first[np.newaxis, :, :] + second[:, np.newaxis, :]
flat_grid = grid.reshape(-1, data.shape[1])
# title for the plots
titles = [
"SVC with rbf kernel",
"SVC (linear kernel)\n with Fourier rbf feature map\nn_components=100",
"SVC (linear kernel)\n with Nystroem rbf feature map\nn_components=100",
]
plt.figure(figsize=(18, 7.5))
plt.rcParams.update({"font.size": 14})
# predict and plot
for i, clf in enumerate((kernel_svm, nystroem_approx_svm, fourier_approx_svm)):
# Plot the decision boundary. For that, we will assign a color to each
# point in the mesh [x_min, x_max]x[y_min, y_max].
plt.subplot(1, 3, i + 1)
Z = clf.predict(flat_grid)
# Put the result into a color plot
Z = Z.reshape(grid.shape[:-1])
levels = np.arange(10)
lv_eps = 0.01 # Adjust a mapping from calculated contour levels to color.
plt.contourf(
multiples,
multiples,
Z,
levels=levels - lv_eps,
cmap=plt.cm.tab10,
vmin=0,
vmax=10,
alpha=0.7,
)
plt.axis("off")
# Plot also the training points
plt.scatter(
X[:, 0],
X[:, 1],
c=targets_train,
cmap=plt.cm.tab10,
edgecolors=(0, 0, 0),
vmin=0,
vmax=10,
)
plt.title(titles[i])
plt.tight_layout()
plt.show()
脚本总运行时间: (0 分 1.582 秒)
相关示例